- The paper introduces a novel minimal-pair prompting method to assess surprisal differences between salient and non-salient entities.
- Results show that salient entities exhibit higher token-level surprisal while effectively reducing sentence-level surprisal across diverse genres.
- Implications include enhanced coreference resolution and summarization by incorporating global entity salience into language models.
Testing the Surprisal of Salient Entities in Discourse
Introduction
The paper "Expect the Unexpected? Testing the Surprisal of Salient Entities" (2604.10724) investigates the relationship between global discourse salience and information distribution, operationalized via surprisal metrics derived from LLMs. Distinct from prior UID-focused studies which emphasize evenness in information flow, this research fills a gap by systematically probing how globally salient entities—those deemed summary-worthy—affect both their own predictability and the anticipatory structure of discourse. By leveraging a large, annotated corpus spanning diverse genres and a novel minimal-pair prompting methodology, the authors empirically test three core questions: (1) whether salient entities manifest different surprisal profiles than non-salient entities, (2) whether salient entities systematically decrease the surprisal of surrounding discourse when used as prompts, and (3) whether these effects are genre-dependent.
Methods and Dataset
The experimental framework is built on the GUM-SAGE dataset, which provides over 70K manually annotated entity mentions across 16 spoken and written English genres, each annotated for global salience based on summary alignment. Salience scores range from 0 (non-salient, absent from summaries) to 5 (present in all summaries), providing a gradient measure rather than binary classification. Entity mentions encompass proper nouns, common nouns, and pronouns, with careful handling of nesting via gold-coreference resolution. Surprisal is computed using DistilGPT-2 (and replicated with GPT2-Small), extracting negative log-probability at the token level and then aggregating to mention- and entity-level z-scores normalized within documents.
Empirical Findings
Experiment 1: Surprisal Profiles in Natural Contexts
Analysis of token-level surprisal in running texts reveals that globally salient entities exhibit significantly higher surprisal than non-salient entities, even after controlling for position, length, and nesting. However, the effect size is modest (approximately 0.1 standard deviations), and several confounds (especially mention length and syntactic nesting) attenuate the raw signal.
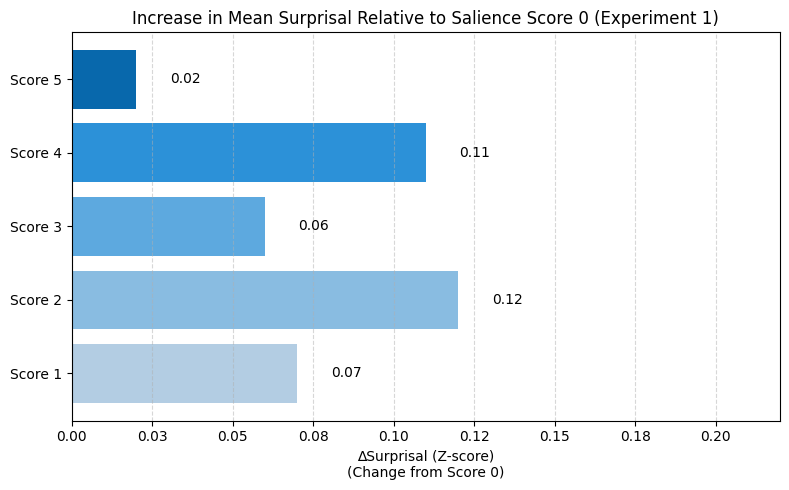
Figure 1: Change in mean surprisal for salience scores 1–5 relative to score 0 in Experiment 1.
Regression modeling demonstrates that position, length, and nesting are powerful predictors of surprisal, with nesting in particular reducing surprisal due to syntactic context constraint. Salience remains a significant predictor even after accounting for these confounding factors.
Experiment 2: Prompting and Surprisal Reduction
A minimal-pair prompting paradigm is introduced: salient and non-salient entities from the same document are used as prompts preceding identical sentences, and sentence-level surprisal is measured. The results show that globally salient entities consistently lower the surprisal of following content, with the magnitude of reduction growing monotonically with salience score.
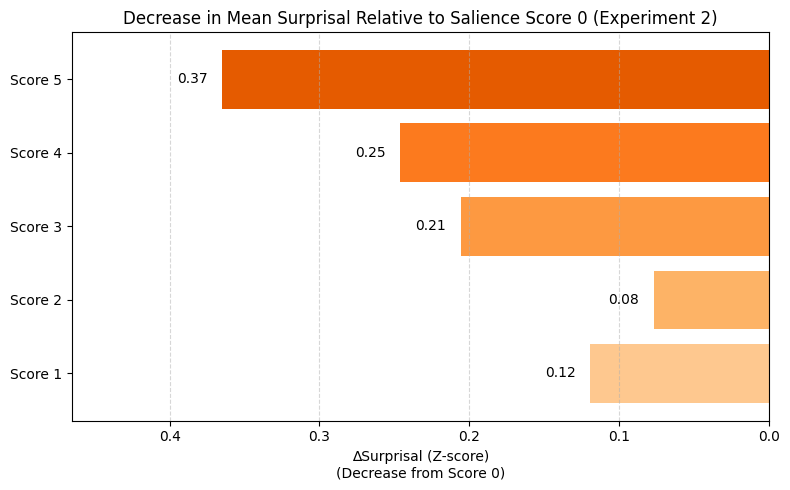
Figure 2: Decrease in mean surprisal relative to salience score 0 in Experiment 2. Magnitude of surprisal reduction largely grows with salience.
Cross-genre analysis confirms universality of the effect, with pronounced surprisal reduction in topic-coherent genres (academic, interviews) and attenuated effects in conversational and informal genres.
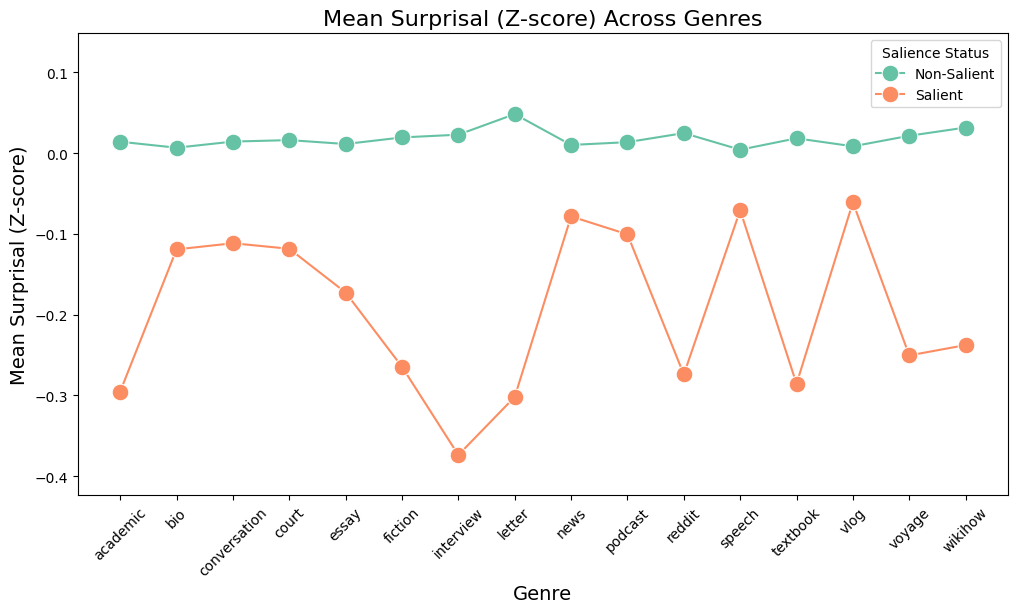
Figure 3: Mean surprisal scores across genres for Experiment 2 (salience score > 0 in orange, score = 0 in green).
Experiment 3: Head-Noun Control for Confounds
To precisely control for length and nesting, prompts are reduced to head nouns, based on gold UD annotations. The monotonic pattern of surprisal reduction is amplified, affirming that global salience robustly shapes predictability independent of syntactic and lexical confounds.
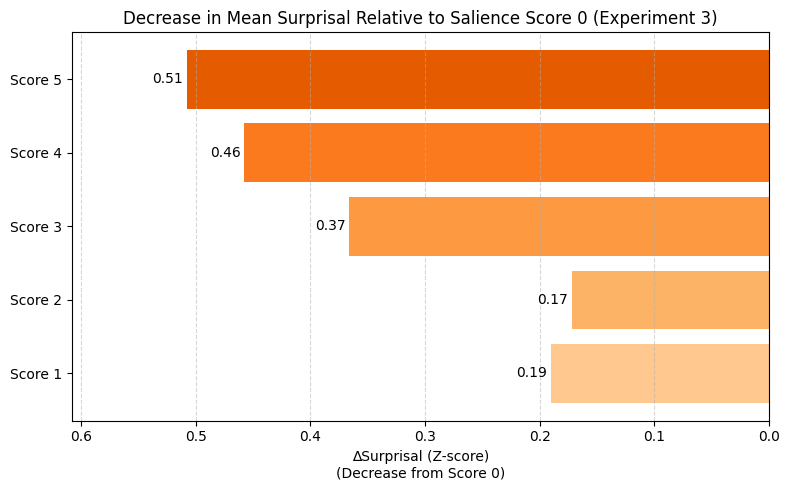
Figure 4: Decrease in mean surprisal relative to salience score 0 in Experiment 3.
Genre-specific results are consistent, with formal, coherent genres producing larger effects.
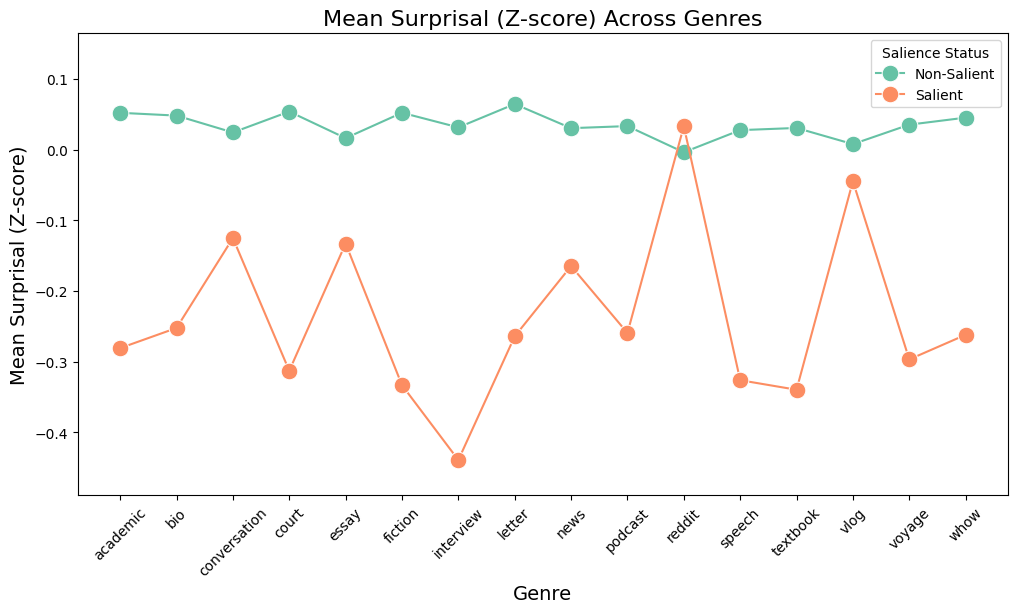
Figure 5: Mean surprisal scores across genres for Experiment 3 (salience > 0 in orange, salience = 0 in green).
Genre-Specific Analysis
Salient entities decrease surprisal in most genres, but the effect size and statistical significance vary considerably. Structured genres (academic, biography, fiction) exhibit strong and significant gaps, while topic-shifting and informal genres (conversation, vlog, reddit) show smaller or non-significant differences.
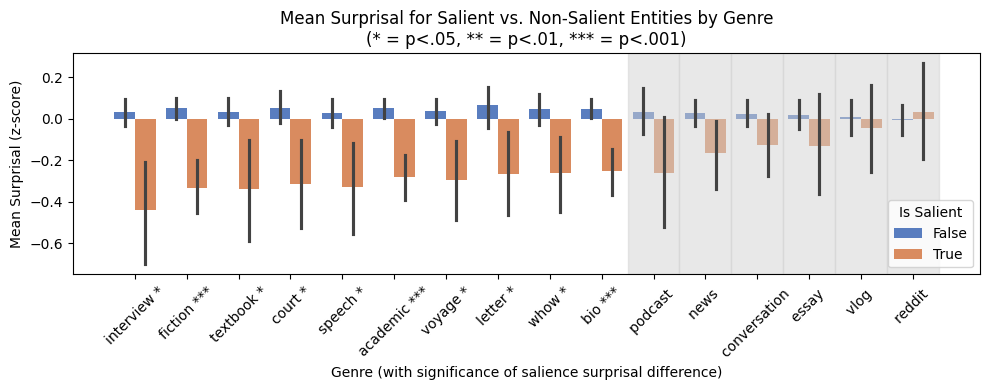
Figure 6: Mean surprisal (z-score) for salient vs. non-salient entities across genres. Bars show mean surprisal for salient (orange) and non-salient (blue) entities, with genres sorted by surprisal difference.
Qualitative contours highlight the genre-dependent nature of the effect: salient entities prompt strong expectations in academic writing, shaping surrounding surprisal, whereas in informal conversation, topic instability leads to less predictable content post-prompt.
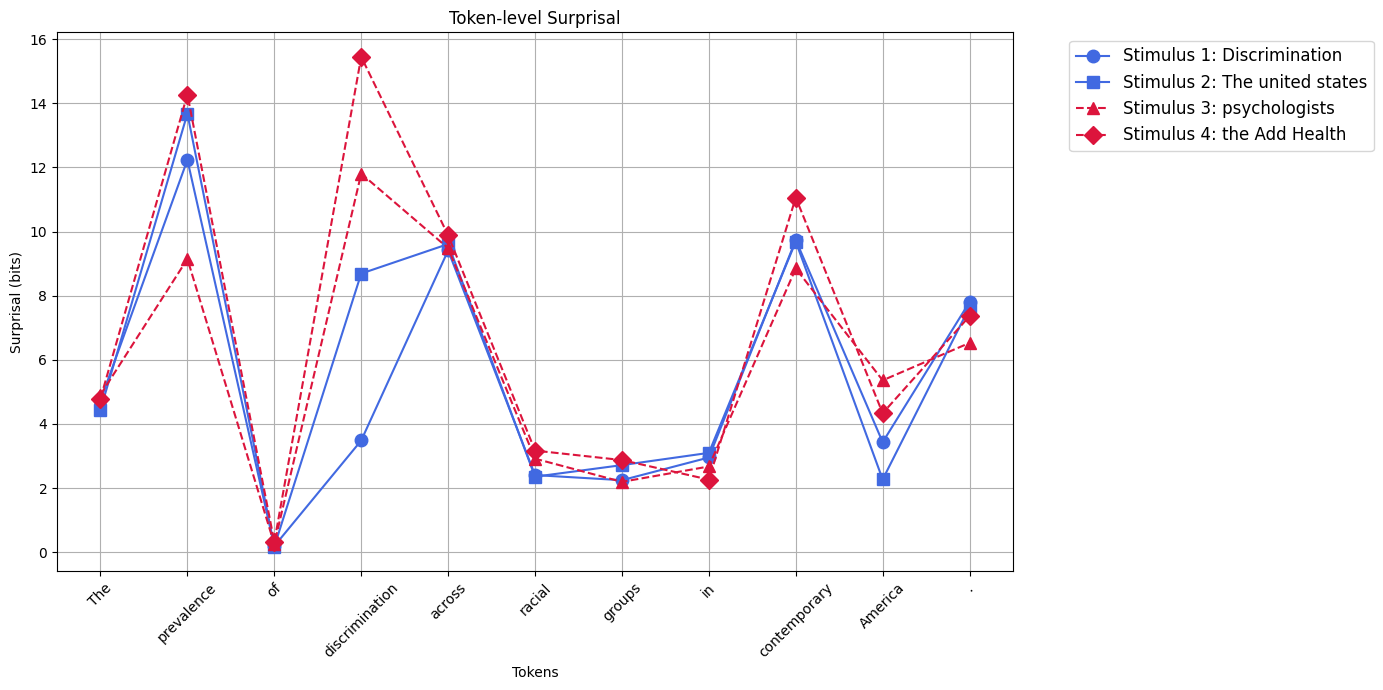

Figure 7: Surprisal contour for a minimal pair in an academic excerpt.
Theoretical and Practical Implications
The findings formally refine the UID competing pressures framework, introducing global entity salience as a discourse-level mechanism that shapes information distribution non-uniformly. While UID posits a tendency toward uniform information flow, salient entities establish localized zones of high expectation (surprisal reduction), competing against syntactic and phonotactic pressures previously identified. This underlines the predictive power of summary-based salience as a proxy for discourse centrality and its utility in modeling referential predictability.
Practically, these results inform coreference resolution, automatic summarization, and language modeling: integrating entity salience metrics could enhance models’ capacity to anticipate discourse structure and optimize generation for topical coherence. For genre-sensitive NLP applications, the discovered interaction between salience and predictability can be used to tailor approaches for structured vs. conversational discourse.
Future Directions
Open questions include the generalizability of salience-surprisal dynamics across typologically diverse languages, especially in lower-resource contexts and morphologically rich languages. The extension to proposition-level salience and multimodal contexts, as referenced by current annotation efforts and ongoing UID research with visual grounding, represents promising avenues. Exploration of alternate information-theoretic metrics (entropy, mutual information) and more granular interaction with local referential factors (definiteness, grammatical role) could enrich discourse processing models.
Conclusion
This work rigorously establishes global discourse salience as a competitive structural pressure influencing information distribution, shaping localized surprisal contours in English discourse. While salient entities are more surprising in isolation, their presence robustly enhances predictability for surrounding content, with the effect modulated by discourse genre structure. The theoretical contribution to UID and practical implications for language modeling and discourse analysis highlight the importance of representing global salience in computational approaches to extended text. The methodology and corpus provide a foundation for future research on salience, surprisal, and their cross-linguistic and multimodal extensions.

