- The paper introduces a novel round-trip evaluation pipeline that leverages detailed psychometric profiles to guide narrative generation, achieving correlations up to r=0.825.
- It validates the method across multiple LLM architectures, demonstrating cross-architectural consistency with recovery rates reaching 85% of human test-retest reliability.
- The study highlights the potential of immersive narrative generation for enhancing AI persona conditioning and advancing computational personality assessment.
Robust Round-Trip Personality Encoding in LLM-Generated Life Stories
Introduction
"Stories of Your Life as Others: A Round-Trip Evaluation of LLM-Generated Life Stories Conditioned on Rich Psychometric Profiles" (2604.06071) presents a rigorous, multi-stage evaluation paradigm for examining the representational fidelity of personality information in LLMs. Prior approaches to LLM persona conditioning have relied heavily on self-report questionnaires, synthetic profiles, or limited architectural validation. This study moves beyond these limitations by leveraging real human psychometric profiles, immersive prompt conditioning, extended narrative generation, and cross-architecture validation to systematically assess whether LLMs can encode, retain, and subsequently reveal robust, psychometrically valid individual difference signals through the medium of extended autobiographical narrative.
Methodology
The round-trip pipeline comprises three critical stages. First, detailed psychometric profiles—including the full HEXACO-60, trust, social anxiety, and psychopathy measures—from 290 participants in the PARSEL dataset are converted to immersive, second-person personality prompts via advanced LLM generation. Second, these prompts condition generation of ~8,000-word, first-person life story narratives using the McAdams Life Story Interview (LSI) protocol. Third, independent LLMs perform blind recovery of the original psychometric scores by scoring the generated narratives, with no access to original items or biographical details.
To control for the possibility of biographical leakage, narratives are matched against masked personality-only prompts in forced-choice experiments. Multiple independent scorers and generators (spanning OpenAI, Google, Anthropic, xAI, and others, including a diffusion LM, Mercury 2) ensure generalizability of results across architectures and training paradigms.
Quantitative Personality Signal Recovery
The primary pipeline (GPT-4.1 generator, Sonnet scorer) recovers HEXACO domain scores from narrative with r=0.750 mean Pearson correlation to ground-truth, achieving 85% of the human test-retest reliability ceiling as benchmarked by Henry et al. (2022). Recovery for individual domains ranges from r=0.682 (Conscientiousness) up to r=0.825 (Extraversion), with all domains significantly above chance and approaching the gold standard for personality measurement reliability.
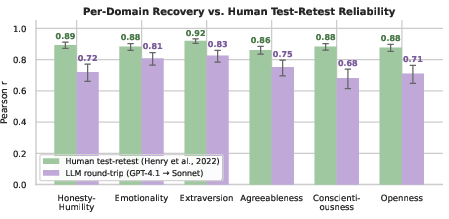
Figure 1: Per-domain HEXACO recovery (r) for the LLM-based round-trip pipeline versus human test-retest reliability, with 95% CIs, demonstrating high-fidelity preservation of individual difference signal in generated text.
Importantly, this pipeline generalizes robustly: 9 generator–scorer pairs—including cross-provider and cross-archetype models—yield r=0.719–$0.750$. Mercury 2, a non-autoregressive diffusion LLM, maintains r≈0.69, demonstrating the persistence of personality-language mapping independently of generation inductive bias.
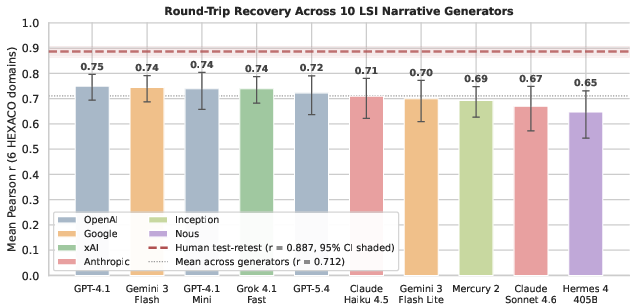
Figure 2: Round-trip personality recovery correlations across six model providers, indicating negligible architecture-specific effects and benchmarking against the human test-retest interval.
The approach is not limited to core personality traits. All nine "beyond-HEXACO" subscales (e.g., Trust Benevolence, SIAS, PPTS Affective Responsiveness) are both statistically and practically recoverable, with r values up to $0.65$ for affective and interpersonal domains.
Validation Against Artifactual Explanations
Masked matching experiments confirm that narrative–personality pairing is achieved nearly four times above chance (79.4% accuracy for independent LLMs, compared to 20% random baseline) even after removing all biographical information. Jaccard analysis reveals zero cases of narrative sentences exceeding $0.7$ similarity to questionnaire item stems, confirming absence of verbatim leakage. Distortion analysis attributes most residual bias not to overfitting but to shared alignment defaults (high Honesty-Humility and Conscientiousness, low Emotionality) induced during RLHF or alignment phases, which are actively "counter-leveraged" by richer conditioning.
Linking Synthetic Narrative Behaviour to Real Human Communication
A critical challenge is to determine whether LLM-generated narratives reflect not only encoded psychometric properties but also real human behavioural signatures. Correlation analysis between coded features in synthetic LSI narratives and actual conversation transcripts (e.g., vulnerability, agency, disclosure depth) show positive and significant correlations for 9 out of 10 content features. For example, vulnerability (r=0.6820), agency (r=0.6821), and emotional valence (r=0.6822) bridge consistently from narrative to real interaction. Importantly, individual difference effects extend beyond trait centroids: variability in emotional valence across narrative sections tracks with Emotionality (r=0.6823), and the same intra-individual reactivity variance is found in spontaneous conversation (r=0.6824). This supports not only the encoding of trait levels but also of characteristic affective fluctuations.
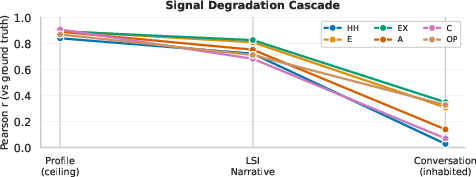
Figure 3: Cascade of signal degradation—profile ceiling, LSI narrative, and real conversation—quantifying the preservation of personality signal across each transformational stage.
Supervised (content feature coding) and unsupervised (BERTopic clustering) analyses confirm that narrative structure is robustly organized by trait dimensions, especially Honesty-Humility and Emotionality.
Theoretical and Practical Implications
Architecture and Inductive Bias
The finding that recovery rates are invariant across major model architectures, including non-autoregressive paradigms, strongly indicates that the personality-language associations necessary for round-trip signal preservation are emergent properties of large-scale human text pretraining. Architecture-specific artifacts or biases are therefore insufficient explanations for the observed effects. Instead, these associations are deeply embedded in the distributional semantics and narrative conventions saturating the training corpus.
Personality Assessment and AI Persona Conditioning
These results empirically validate immersive, detailed persona prompting for AI agents as substantially more effective than classic thin descriptor methods, aligning with recent results (e.g., [Bai2025], [Kang2025]). The McAdams-format LSI elicits personality-behaviour mappings that not only reflect target scores but also generate differentiated, context-sensitive behaviour, supporting naturalistic alternatives to questionnaire-based measures in both assessment and agent design.
Future Directions
Anticipated directions include:
- Integrating ground-truth human-annotated narrative and conversation coding, to address shared-method variance limitations.
- Extending cross-linguistic and cross-cultural generalization, considering current model training biases towards WEIRD populations and westernized constructs.
- Developing model selection and persona conditioning frameworks minimizing alignment-induced default biases, possibly via post-hoc calibration or diversified training regimes.
- Investigating privacy-preserving mechanisms for synthetic persona generation, especially when models can reconstruct robust "trait-fitted" narratives from non-proprietary or widely administered psychometric data.
Conclusion
This study establishes that personality and related psychometric signals can be robustly injected into, preserved through, and subsequently extracted from extended LLM-generated narratives with fidelity approaching human test–retest reliability. Cross-architecture consistency and the replication of personality-driven behavioural signatures in both synthetic and spontaneous contexts underscore the depth and resilience of the personality–language mapping inherent to large-scale pretraining. These findings have broad implications for personality assessment, socially-grounded AI agent development, and our understanding of how trait information is distributed and recoverable within high-dimensional text spaces.