- The paper introduces an exact IEEE 754-compliant FP multiplier and an approximate variant using mantissa segmentation to enable configurable accuracy.
- It leverages conditional computation of low-significance segments to achieve up to 78.4% area and 82.1% power reductions without compromising application-level performance.
- The design integrates compiler-visible accuracy knobs within a DCiM framework, expanding hardware-software co-optimization for energy-efficient edge AI applications.
Accuracy-Configurable Floating-Point Multiplication for SRAM-Based Compute-in-Memory
Motivation and Context
SRAM-based Digital Compute-in-Memory (DCiM) is a key paradigm for mitigating the von Neumann memory bottleneck, especially under the strict energy and area constraints of edge AI. Existing DCiM compilation flows, exemplified by systems like OpenACM, primarily target integer or fixed-point arithmetics, leaving crucial gaps for floating-point (FP) support. Although a few recent DCiM macros demonstrate floating-point computation, in practice, area and power penalties remain prohibitive for direct adoption of standards-compliant FP units. Additionally, true compiler-level integration and accuracy configuration of FP operations within DCiM compilation frameworks remain poorly supported.
This work systematically addresses these gaps by proposing (1) an exact IEEE 754-compliant floating-point multiplier for use as a correctness-preserving baseline, and (2) a mantissa-segmentation-based approximate floating-point multiplier (AFPM), exposing accuracy as a compilation-time knob, and evaluates these designs within the OpenACM flow. The AFPM leverages segmentation and conditional execution of mantissa multiplication to yield significant improvements in area and power without notable degradation in numerical or network-level accuracy.
Design Architecture
The exact floating-point multiplier follows the canonical IEEE 754 multiplication pipeline, including sign bit computation, exponent accumulation and bias correction, normalization, rounding, and overflow/underflow handling. The workflow is summarized as:
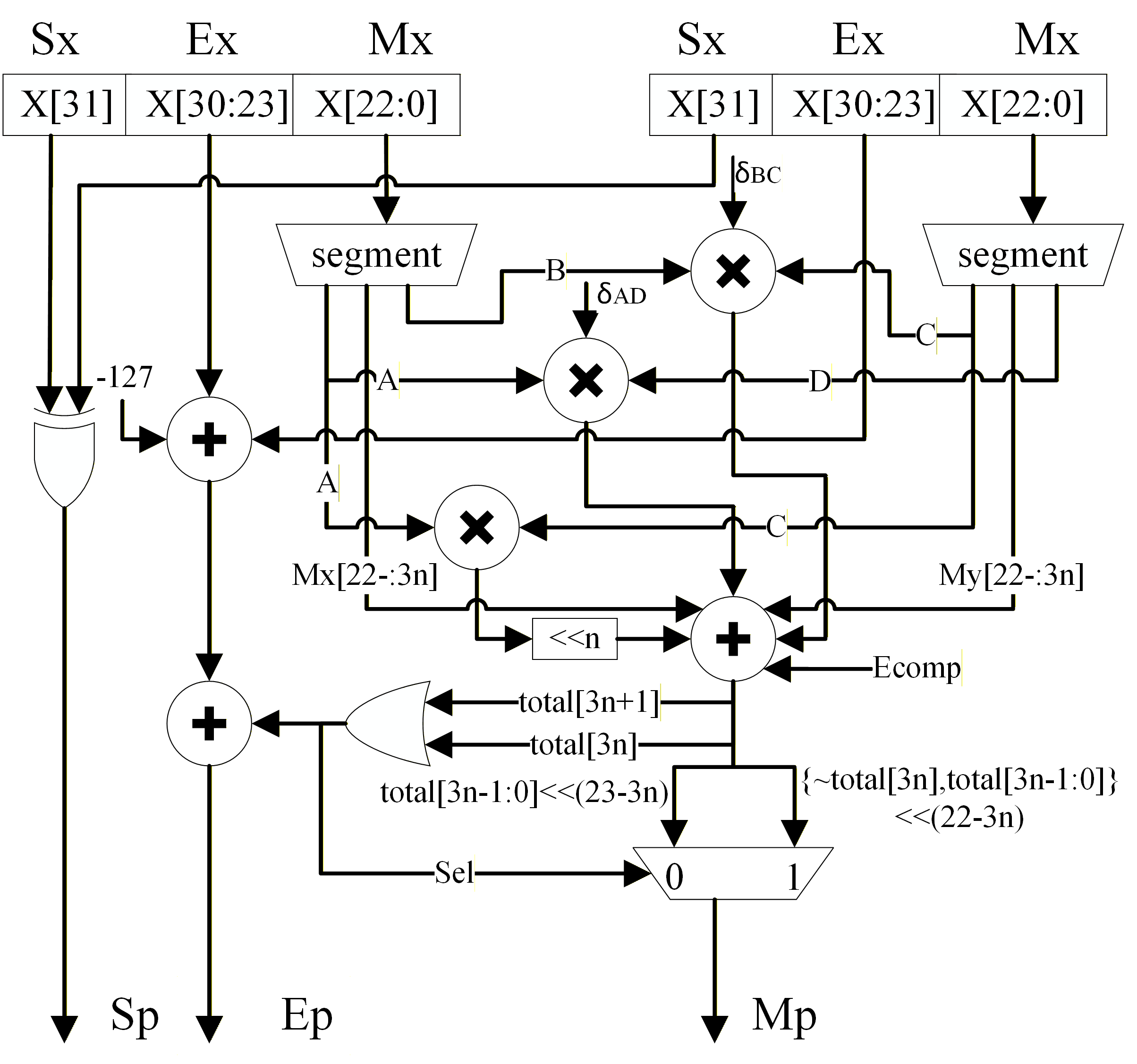
Figure 1: Overall hardware architecture of the proposed approximate floating-point multiplier.
The core technical contribution is the mantissa-segmentation-based approximate multiplier. This architecture partitions the mantissas of both operands into high- and low-significance segments of configurable width n, enabling fine-grained trade-offs between computational accuracy and PPA (power, performance, area) metrics.
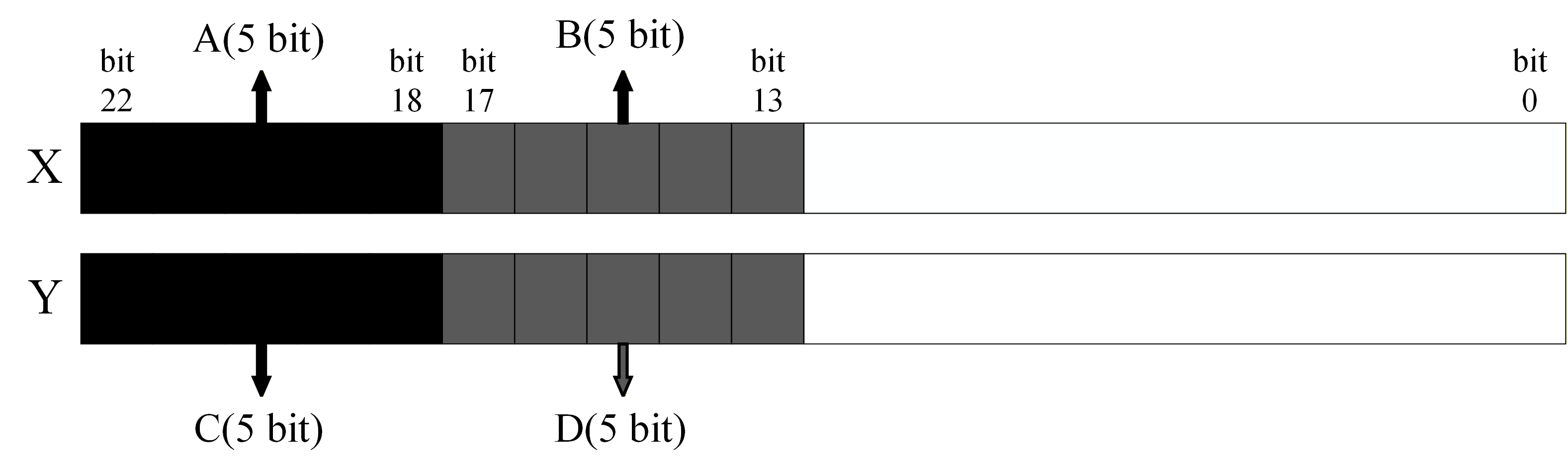
Figure 2: Mantissa segmentation with configurable width n.
Consider input mantissas MX,MY, expressed as:
MX=A⋅2−n+B⋅2−2n,MY=C⋅2−n+D⋅2−2n
where A and C are high-significance and B, D low-significance segments. The partial products AC, AD, n0, and n1 are assigned inexact or omitted implementations based on their relative weights.
The n2 term is always calculated exactly. Conditional logic assesses the necessity of executing n3 and n4 based on operand significance, and lightweight error compensation mechanisms are introduced to minimize overall accuracy loss. The n5 term, representing the least significant cross-term, is systematically omitted to minimize hardware overhead.
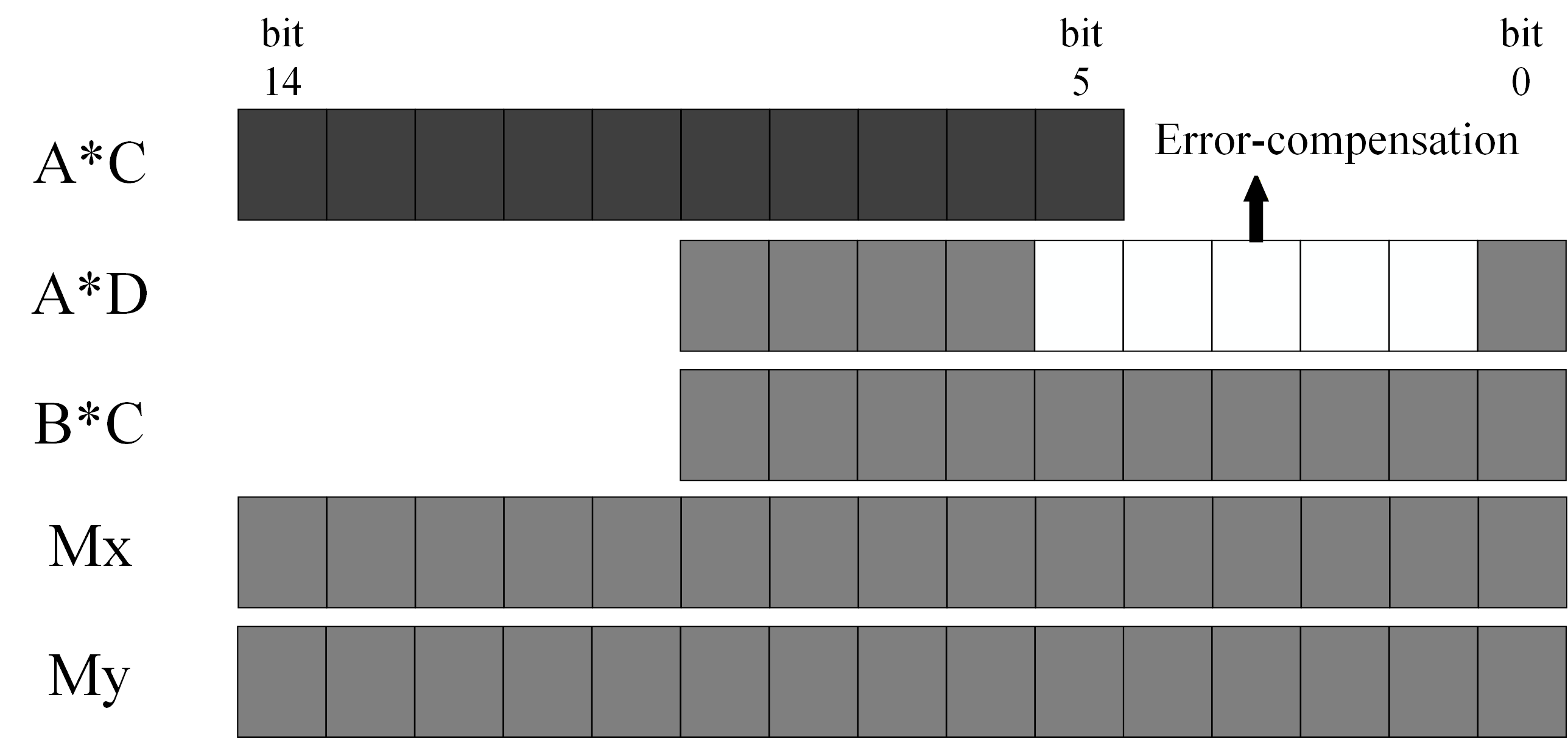
Figure 3: Shift-and-add alignment and accumulation of partial products.
Alignment, normalization, and rounding are applied based on the distribution of significance, using a compact accumulator and significance-aware rounding strategies. The computation workflow, incorporating all segmentation logic, conditional execution, and compensation, is depicted below.
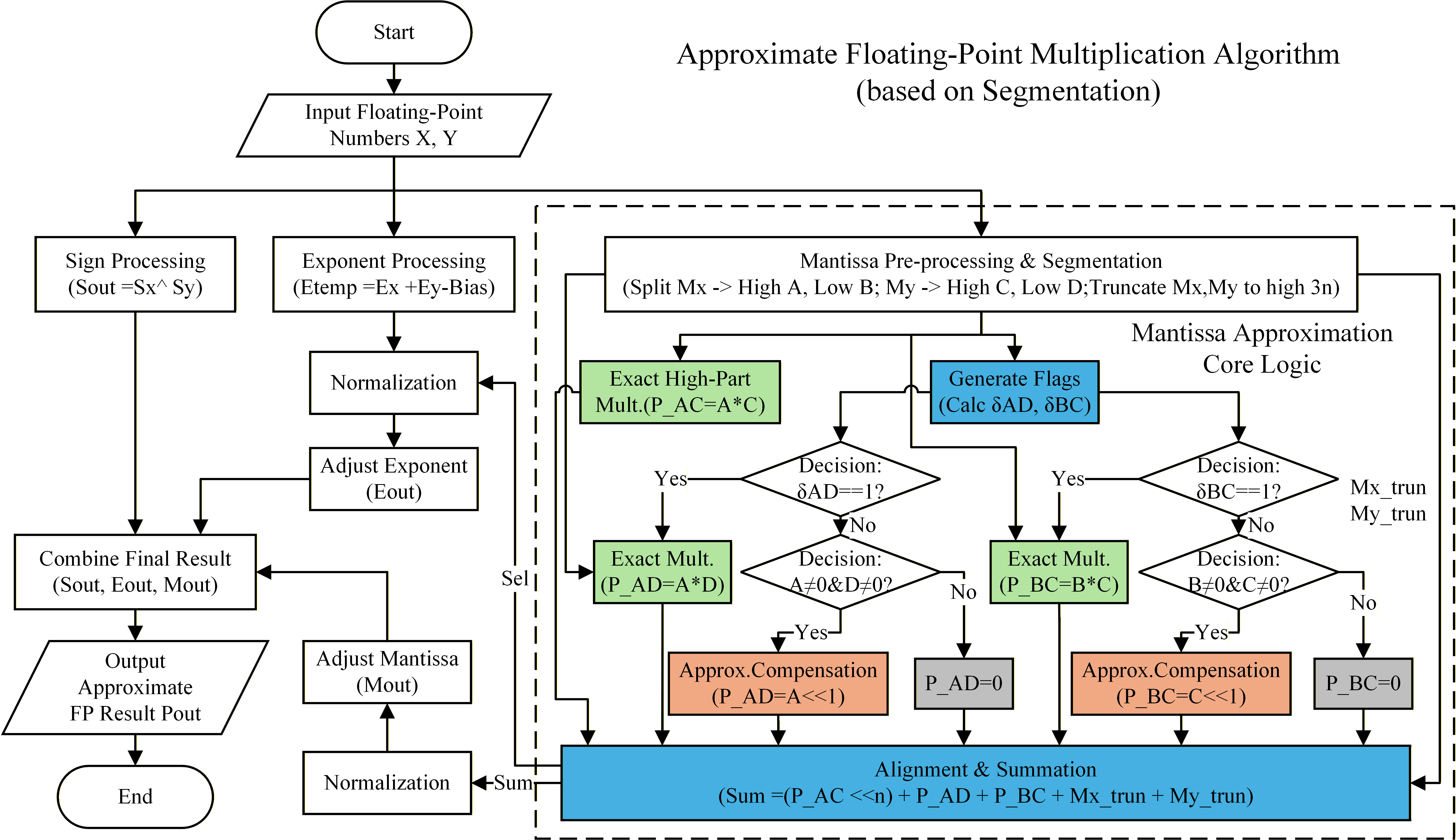
Figure 4: Computation flow of the proposed mantissa-segmentation-based approximate floating-point multiplier.
The design additionally supports a low-precision mode, substituting the high-order product with a bitwise AND, further lowering area/power at the cost of increased error, and is tunable to match application requirements.
Hardware and System-Level Results
Rigorous post-layout PPA analysis, performed on multiple OpenROAD-synthesized SRAM+Multiplier DCiM instances, evidences significant area and power benefits. The ACL5 instantiation of the proposed AFPM achieves a 78.4% reduction in logic area and 82.1% reduction in power consumption compared to the exact baseline, without violating SRAM-dominated critical path constraints.
Experimentally, the architecture's accuracy–efficiency design space subsumes and in some cases outperforms classical segmentation-based (e.g., MMBS, CSS) and logarithmic-based (e.g., NC, LPC, HPC) multipliers in both MRED and NMED error metrics, while maintaining competitive application accuracy on image processing and CNN inference.
Application-Driven Evaluation
The practical consequences of the approximate multiplier are explored on representative image processing tasks (image fusion, edge detection), where the AFPM's PSNR consistently improves with segmentation width n6, and always remained in excess of 80 dB for nontrivial n7. This demonstrates that the error introduced by AFPM does not manifest as perceptible artifacts at the application level.
On CNN inference (ResNet-18, CIFAR-10), the Top-1 and Top-5 accuracy remains virtually indistinguishable from IEEE-754 exact computation for moderate-to-high segmentation widths, with only the most aggressive low-precision modes showing a minor decrease. For example, AC4-4 and AC5-5 configurations reported n80.02% Top-1 degradation, with error metrics demonstrating 80%+ reduction relative to prior segmentation-based units.
Theoretical and Practical Implications
From a system design perspective, integration of compiler-visible FP accuracy knobs fundamentally expands the hardware–software co-optimization space. Floating-point units are, for the first time in OpenACM, accessible for application-tuned hardware implementation, permitting DSE across FP bit-width and segmentation granularity for diverse accuracy and power envelopes. The adoption of mantissa segmentation as the primary approximation axis aligns well with observed sensitivity analysis in deep learning workloads, where high-order product fidelity dominates architectural robustness.
Practically, approximate floating-point compute-in-memory is made feasible for edge inference, lifelong learning, and other non-stationary, energy-critical tasks where area/power headroom is prohibitive and integer/fixed-point quantization alone is insufficient. Furthermore, the proposed framework can naturally generalize to hybrid-precision and retrain-free deployment flows, facilitating end-to-end toolchain automation for approximate DCiM.
Future Directions
The availability of a flexible, compiler-integrated AFPM library within DCiM architectures enables new lines of research, including (but not limited to): hardware-aware NAS with approximate FP search; hybrid quantization and dynamic precision scaling at runtime; reliability and yield-driven arithmetic selection; and the exploration of DCiM architectures for edge training and federated learning, where training convergence and numerical robustness intersect tightly with area/energy efficiency.
Conclusion
This work delivers a unified methodology and hardware-software stack that supports accuracy-configurable FP multiplication in SRAM-based DCiM. The incorporation of mantissa segmentation and compiler-driven accuracy configuration results in substantial system-level PPA benefits, with compelling evidence that these savings do not meaningfully impact critical AI inference or image processing performance. The proposed architecture materially expands the design and deployment landscape for energy-efficient, accuracy-tunable on-chip learning systems.