- The paper offers the first systematic framework for test-time scaling in multimodal foundation models, detailing dynamic inference approaches as a complement to conventional parameter scaling.
- It categorizes TTS into sampling-based, feedback-based, and search-based methods, explaining their roles in generating and reasoning across modalities.
- The survey highlights challenges such as hybrid scaling, error propagation, and hallucination control that shape future research directions in AI deployment.
Comprehensive Review of Test-Time Scaling in Multimodal Foundation Models
Introduction and Motivation
The survey "Test-Time Scaling in Multimodal Foundation Models: A Comprehensive Survey of Generation and Reasoning" (2606.08231) provides the first systematic framework for Test-Time Scaling (TTS) in Multimodal Foundation Models (MFMs). TTS refers to mechanisms that dynamically allocate computational resources at inference time, exploiting model capabilities beyond static training or parameter scaling. The paradigm has gained prominence due to the diminishing returns from the conventional approach of expanding model parameters and training data during pre-training. The authors position TTS as an essential complement to scaling laws, enabling cost-effective, robust adaptation of MFMs in complex reasoning and generation scenarios without retraining.
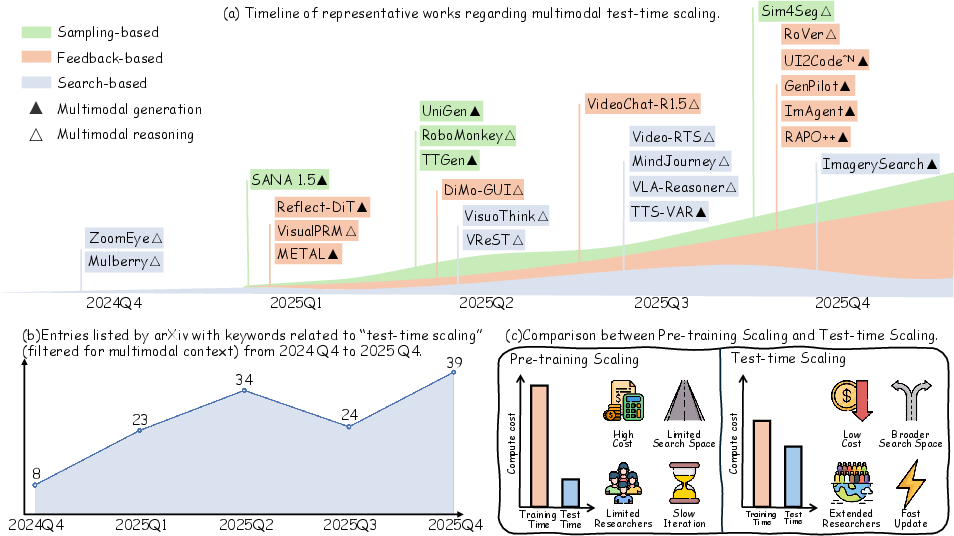
Figure 1: Recent evolution and paradigm shift in multimodal TTS, highlighting publication growth and the transition from static pre-training to dynamic inference scaling.
MFMs, including Multimodal LLMs (MLLMs) like GPT-4V and Gemini 2.0, and Diffusion Models, integrate vision and language modalities. Their architectural support for cross-modal fusion allows methods such as CoT reasoning and multi-step verification at test-time. These capabilities render MFMs central to AGI progress, but their performance, like that of LLMs, ultimately confronts scaling law bottlenecks. TTS unlocks further potential by enabling flexible allocation of inference resources, supporting adaptation to distribution shifts and increased reasoning depth.
Unified Taxonomy of TTS Approaches
The survey establishes a taxonomy categorizing TTS for MFMs into three main strategies: sampling-based, feedback-based, and search-based approaches. Each paradigm targets specific strengths, limitations, and trade-offs across generation and reasoning tasks.
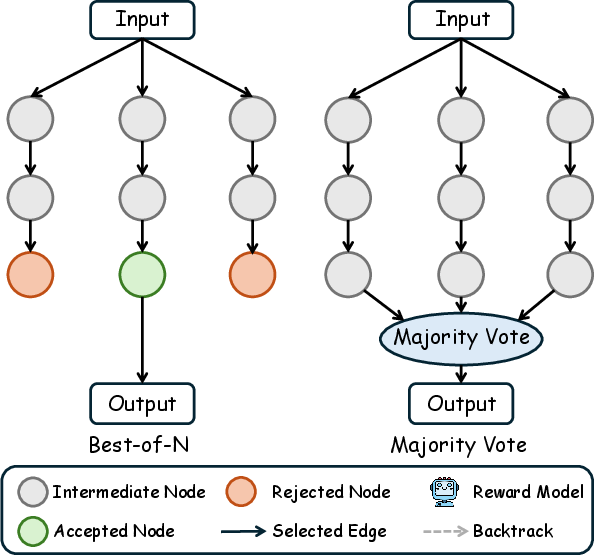
Figure 2: Illustration of sampling-based methods demonstrating candidate generation and aggregation for multimodal outputs.
Sampling-Based Methods
Sampling-based TTS generates multiple candidates in parallel, aggregating or selecting optimal outputs using scoring mechanisms or majority voting. This expands the explored solution space, improving output fidelity and diversity. Benchmarks and methods such as TTGen, SANA-1.5, and UniGen employ Best-of-N selection using CLIP scores or tournament-tier VLM scoring, while approaches like EQA-RM and RoboMonkey leverage majority voting for answer reliability. Although parallelizable, performance gains plateau with increased sampling, and selection depends critically on the quality of auxiliary scoring models.
Feedback-Based Methods
Feedback-based strategies utilize reward models or iterative refinement to steer or correct outputs. ORMs evaluate final candidates, often integrated with sampling methods, while PRMs provide intermediate stepwise feedback, supporting dynamic exploration via beam or tree search. Notable methods include EQA-RM, Athena, RoVer, and VisualPRM, which supply global and local feedback for multimodal QA, math reasoning, and visual-language action. Iterative refinement frameworks (e.g., Reflect-DiT, UI2CodeN, VideoChat-R1.5) implement "generate-evaluate-correct" loops, progressively optimizing generated content using internal or external evaluation signals.
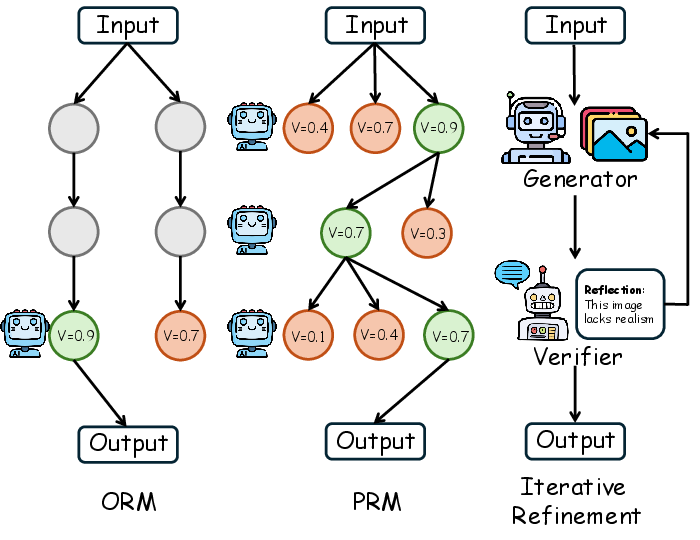
Figure 3: Feedback-based methods using Output and Process Reward Models to filter and refine candidates across reasoning trajectories.
Search-Based Methods
Search-based TTS organizes inference as systematic trajectory exploration via beam search, tree search, or heuristic/adaptive search. In beam search, candidate paths are maintained and pruned based on scores, balancing breadth and efficiency. Tree search recursively generates, branches, and backtracks among nodes, supporting hierarchical exploration in spatial or temporal domains (e.g., ZoomEye, AKEYS, VReST, Mulberry). Adaptive search leverages dynamic compute allocation and evolutionary algorithms, activating additional resources or search steps when instance difficulty increases (e.g., VideoICL, TTS-VAR).
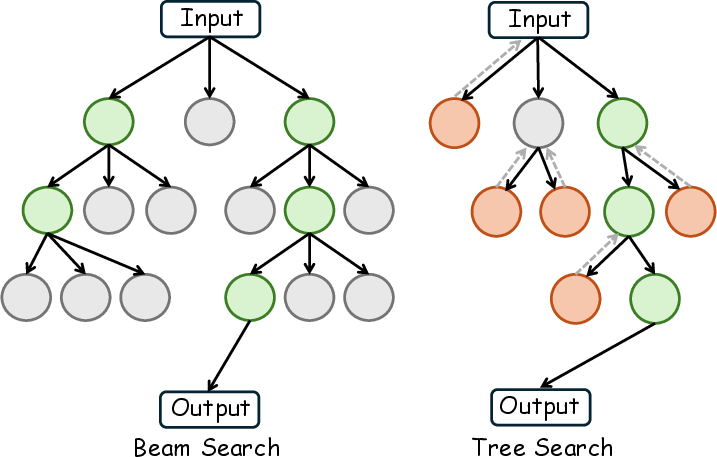
Figure 4: Search-based methods employ structured trajectory exploration and adaptive resource allocation for complex multimodal reasoning and generation.
Applications and Benchmarks
The practical relevance of TTS spans both multimodal generation (image, video) and multimodal reasoning (video reasoning, vision-language-action, math reasoning):
- Image Generation: Sampling and iterative refinement dominate, maximizing visual-semantic consistency through parallel candidate evaluation and dynamic prompt optimization.
- Video Generation: Search strategies prune incoherent frame sequences, maintaining temporal stability via optimal trajectory selection.
- Video Reasoning: Search and refinement methods focus computation on salient events and filter irrelevant information, handling long-context dependencies.
- Vision Language Action: Parallel sampling and tree search generate multiple action paths, employing scoring/consensus and lookahead planning for robust execution.
- Math Reasoning: MCTS-based approaches simulate future reasoning states, supporting rollback and correction of intermediate visual/textual steps.
Benchmarks are tailored for each domain (e.g., MSCOCO, DrawBench, VBench for generation; SAT, MathVista, LongVideoBench for reasoning), quantifying semantic quality, compositionality, temporal consistency, and cross-modal alignment.
Technical Challenges and Implications
The survey underscores several core challenges:
- Hybrid Scaling: Current methods rarely combine strategies, missing synergistic effects. Hybrid frameworks (e.g., coupling MCTS and feedback loops) offer improved efficiency without sacrificing accuracy.
- Error Propagation: Long-chain multimodal reasoning suffers cascading errors; future solutions should incorporate process-level correction and critical node verification.
- Hallucination Control: Existing methods mostly apply post-hoc checks; advanced cross-modal verification procedures for process-level suppression are needed.
The theoretical implication is clear: TTS formalizes inference as dynamic utility maximization given fixed model weights, introducing new axes for model improvement orthogonal to conventional pre-training scaling. Practically, optimized TTS yields robust adaptation, improved reliability, and cost efficiency, supporting AGI-relevant reasoning capacities without retraining.
Conclusion
This survey defines a unified taxonomy for TTS in MFMs, synthesizing sampling, feedback, and search paradigms while highlighting their distinct applicability to multimodal generation and reasoning. By organizing existing methods and identifying open challenges—hybrid scaling, error correction, hallucination mitigation—the survey maps a clear direction for subsequent research. The TTS paradigm, as formalized here, is fundamental to advancing both the practical deployment and theoretical understanding of AI systems capable of general multimodal reasoning.

