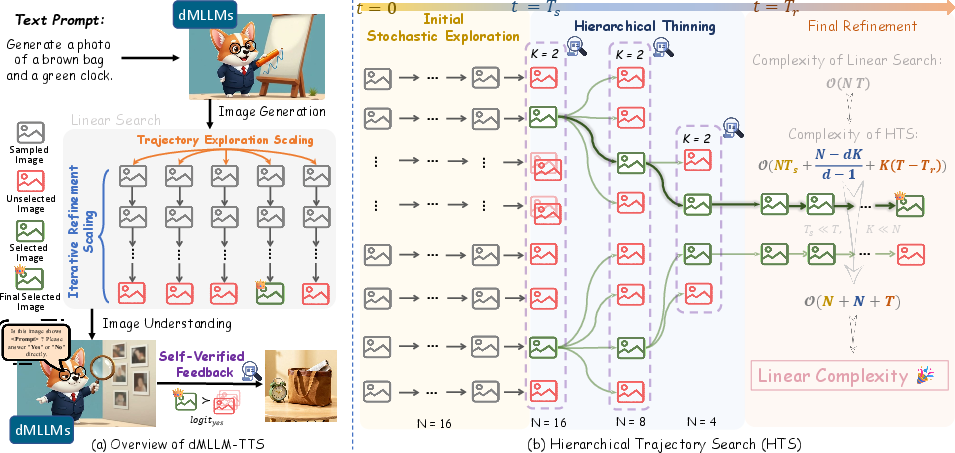
- The paper introduces a test-time scaling framework that integrates trajectory exploration and iterative refinement to improve compositional text-to-image generation.
- Experimental results show substantial improvements in GenEval scores and computational efficiency, with gains up to 6× over baseline methods.
- The framework leverages self-verified feedback within dMLLMs, reducing reliance on external verifiers while ensuring high fidelity and prompt alignment.
Self-Verified and Efficient Test-Time Scaling for Diffusion Multi-Modal LLMs: dMLLM-TTS
Introduction and Background
The "dMLLM-TTS: Self-Verified and Efficient Test-Time Scaling for Diffusion Multi-Modal LLMs" paper (2512.19433) introduces an inference-time framework designed to optimize the generative capacity and compute efficiency of Diffusion Multi-Modal LLMs (dMLLMs). dMLLMs unify token-wise image synthesis and multimodal understanding within a discrete diffusion modeling framework, pushing forward the paradigm for compositional text-to-image generation. While scaling during model training has led to incremental improvements, increases in data and model size have started to yield diminishing returns. Test-time scaling (TTS), which allocates additional compute at inference without increasing model size or retraining, is a promising alternative for further progress in generative quality.
This work proposes dMLLM-TTS, a first-of-its-kind framework that systematically integrates both scaling strategies and search algorithms, and—importantly—a self-verification mechanism that leverages the image understanding inherent in dMLLM architectures. The framework decomposes TTS along two axes: trajectory exploration scaling (diversifying generative hypotheses) and iterative refinement scaling (stabilizing the denoising process). Instead of traditional approaches relying on brute-force search with external vision-LLM (VLM) verifiers and incurring quadratic computational cost, the authors innovate via efficient hierarchical search and an internal self-verification procedure.
The dMLLM Generation Process
dMLLMs operate through iterative, parallel denoising within a discrete latent token space. The process initializes with a sequence of fully masked tokens; at each step, the model predicts candidates for masked positions, progressively filling latent structure and details.
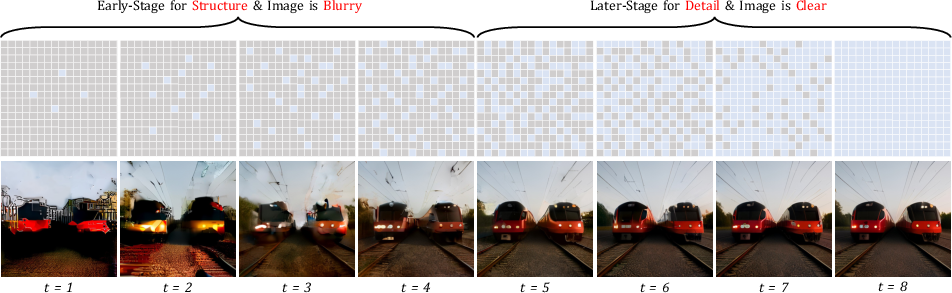
Figure 1: Visualization of the image generation process in dMLLMs, illustrating progressive filling of the latent multimodal space.
The denoising is performed in T steps, and uncertainty masked tokens are repeatedly resampled until the model converges to a plausible sample. This parallel refinement enables broad and deep exploration of candidate solutions at test time, a property pivotal to the proposed scaling strategy.
Test-Time Scaling Framework
The framework formalizes TTS along two axes:
Key to efficiency is judicious allocation of compute. Rather than distributing resources equally among all trajectories (linear search with O(NT) complexity), the authors propose a hierarchical search: initial broad exploration across trajectories followed by progressive pruning based on internal feedback, culminating in focused refinement for only promising candidates.
Self-Verified Feedback Mechanism
Conventional TTS often relies on external VLMs (e.g., CLIP, GPT-4o) to score candidate text-image alignment, adding compute and deployment overhead. Here, the dMLLM itself is used as the verifier by repurposing its own multimodal QA capabilities. Formally, the model answers binary queries regarding prompt-image alignment (e.g., "Is this image a depiction of …?"), using the logit score of a “Yes” response for ranking and selection. This self-verified feedback (SVF) is leveraged iteratively throughout hierarchical search to identify and allocate refinement steps only to plausible candidates.
Hierarchical Trajectory Search
Hierarchical Trajectory Search (HTS) guides inference in three phases:
- Stochastic Exploration: Sample N trajectories, rapidly denoising for Ts warm-up steps to yield coarse hypotheses.
- Hierarchical Thinning: Progressively reduce the number of active trajectories using SVF scores via geometric decay, shifting computational budget to top-K candidates. Local neighborhood branching further diversifies promising hypotheses.
- Final Refinement: Concentrate resources on the few surviving trajectories for the remainder of denoising steps, producing high-fidelity generations.
HTS attains nearly linear compute complexity, O(N+T), in contrast to the brute-force linear trajectory search baseline, without sacrificing model diversity or generative optimality.
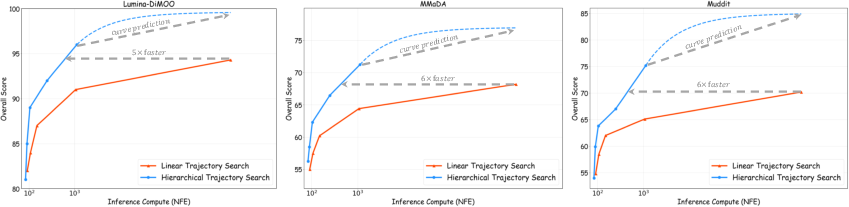
Figure 3: Comparison of linear and hierarchical trajectory search, showing superior convergence and efficiency of HTS.
Experimental Validation and Results
Experiments utilize three open-source dMLLMs—Lumina-DiMOO, MMaDA, Muddit—spanning parameter scales from 1B to 8B, on the GenEval compositional text-to-image benchmark. Across all models, the dMLLM-TTS framework achieves consistent and substantial improvements in prompt alignment and overall generative score.
- Lumina-DiMOO achieves a GenEval score of $0.92$, a +17.9% absolute gain over baseline, outperforming leading text-to-image models including Qwen-Image ($0.87$) and GPT-4o ($0.84$).
- MMaDA and Muddit register $0.66$ and $0.67$ respectively, gains of +29.4% and +26.4%.
- HTS achieves up to 6× computational efficiency compared with conventional linear search.
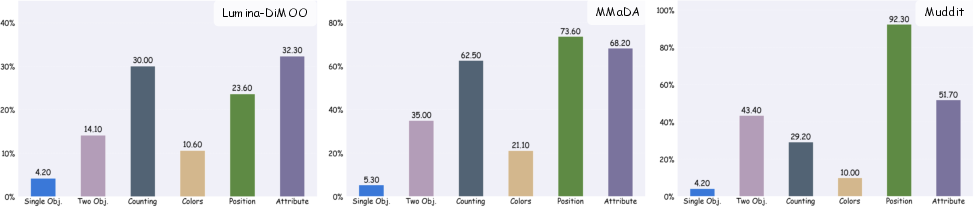
Figure 4: TTS yields qualitative improvements across all prompt complexity dimensions in GenEval, especially for counting, position, and attribute tasks.
Ablation studies demonstrate monotonic gains in output fidelity with increased N and T, until compute limits are reached.
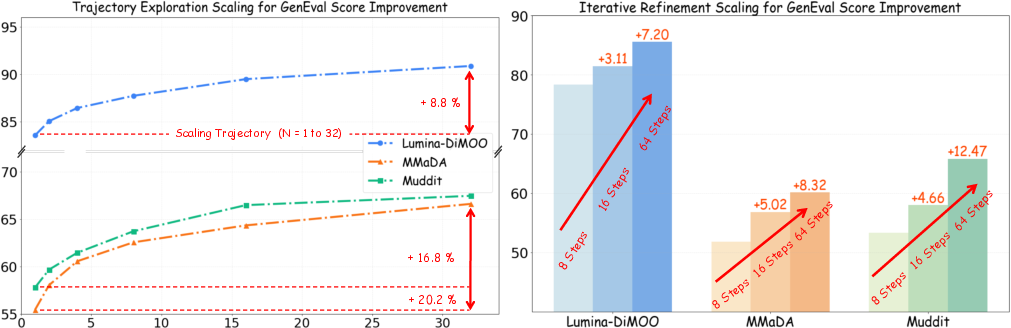
Figure 5: Both trajectory exploration (N) and iterative refinement (T) scaling drive performance across dMLLMs.
Qualitative analysis of intermediate and final outputs illustrates that the baseline often fails to establish plausible initial states or diverges in generation trajectory, whereas dMLLM-TTS maintains text-aligned generative pathways, yielding semantically faithful images.

Figure 6: dMLLM-TTS markedly improves text-to-image synthesis compared to baseline, especially for complex prompts.
Implications and Future Directions
The introduction of self-verified feedback and hierarchical search in dMLLM inference has major practical implications. It eliminates external dependency for verification, reduces redundancy in compute allocation, and provides a blueprint for efficient scaling of generative inference. The methodology generalizes over model architectures and parameter regimes, indicating a fundamental advance in scalable deployment.
However, experiments confirm that external commercial verifiers (e.g., GPT-4o) still exhibit stronger image understanding, suggesting room for further improvement in internal comprehension mechanisms of current dMLLMs. Improving the multimodal reasoning and verification capability of these models could further close this gap or surpass external verifiers, enabling next-generation systems with fully autonomous fidelity assessment and prompt alignment. The HTS paradigm also opens opportunities for adaptive inference in related domains such as video generation and multimodal conversational agents.
Conclusion
The dMLLM-TTS framework provides a technically rigorous and highly efficient solution for test-time scaling in diffusion multi-modal LLMs. By unifying search, scaling, and verification in a self-contained, hierarchical inference process, it achieves substantial gains in text-image alignment and generative quality with near-linear computational cost. This work establishes robust foundations for scalable, autonomous, and efficient multimodal generative models, with promising implications for broader AI applications.