- The paper introduces EASE-TTT, a method that aligns evidence retrieval with test-time adaptation for enhanced long-context QA performance.
- It employs soft attention target construction to emphasize evidence tokens, guiding query-side LoRA adapter updates with KL-divergence minimization.
- Empirical results demonstrate consistent improvements over baselines, particularly in mitigating attention diffusion in smaller language models.
EASE-TTT: Evidence-Aligned Selective Test-Time Training for Long-Context Question Answering
Introduction
Long-context question answering (QA) presents unique challenges for LLMs, particularly for compact architectures. While context windows have expanded to hundreds of thousands of tokens, the core bottleneck remains evidence access rather than mere context size. Many instances include the answer-bearing evidence within the context, yet models—especially smaller ones—often fail to leverage this due to distractors and suboptimal attention allocation. This work identifies evidence-use failure as a primary limitation and introduces EASE-TTT, a method bridging input-level evidence retrieval and parameter-level test-time adaptation.
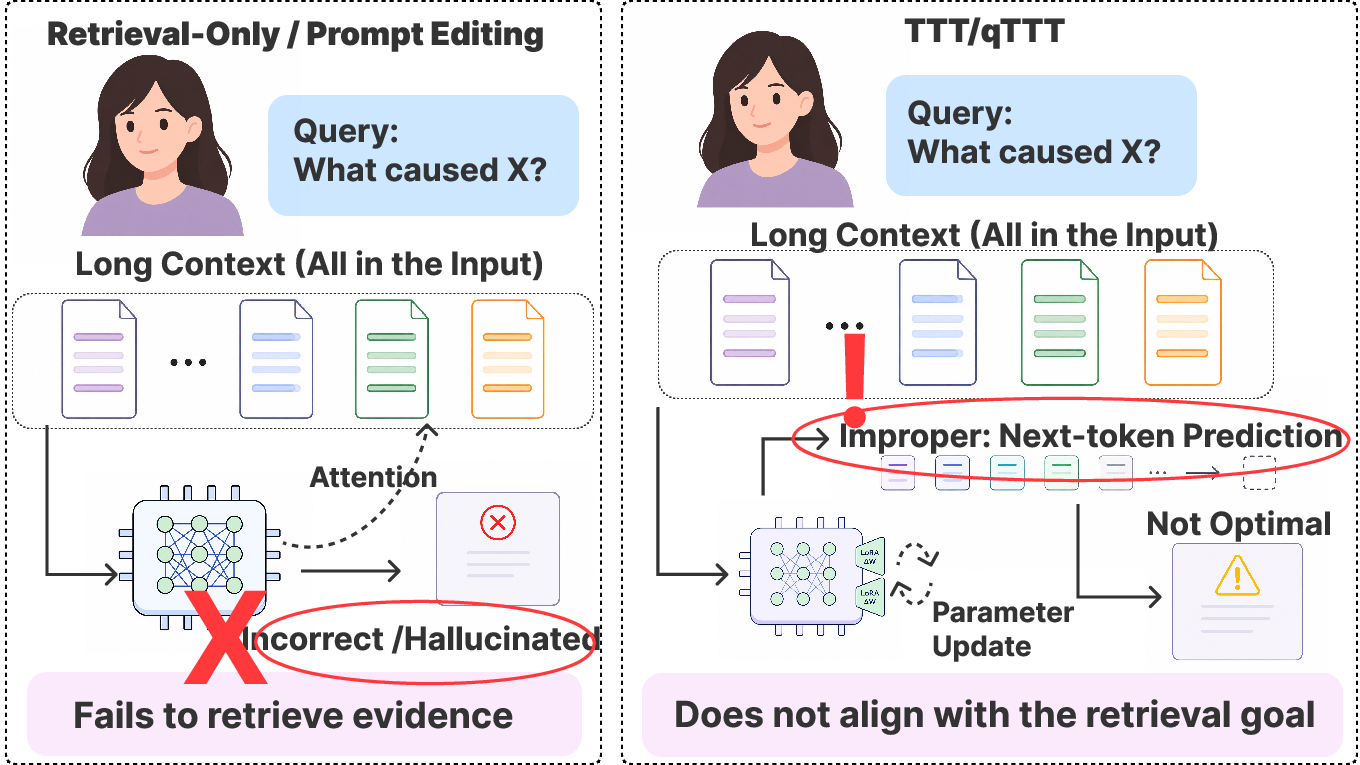
Figure 1: EASE-TTT motivation—retrieval and prompt-editing methods localize evidence but do not change model context-access; test-time training adapts attention but is not evidence-aligned; EASE-TTT unifies both approaches by using retrieved evidence to guide adaptation.
Methodology
Problem Setting and Prior Approaches
Long-context QA is defined as generating an answer y∼pθ(⋅ ∣ c,q) given a long context c (up to 32k tokens) and a question q. Prior paradigms fall into two categories: within-context retrieval and test-time parameter adaptation. Retrieval-based methods segment the context, score and select question-relevant chunks, and use these as input; these approaches change what the model “sees” but not how it attends. Conversely, query-only test-time training (qTTT) adapts query-projection parameters using self-supervised losses on random input spans, modifying attention behavior but lacking evidence-alignment to the current question.
Neither approach guarantees robust, question-driven evidence utilization throughout the full context.
EASE-TTT Framework
EASE-TTT (Evidence-Aligned Selective Test-Time Training) extends qTTT by localizing within-context evidence and using this signal to shape instance-specific adaptation. The framework comprises three modules:
- Within-Context Evidence Selection: The context is first segmented, and utility scores are computed for each chunk based on how much prepending that chunk improves next-token prediction for the question. The highest-utility K chunks are selected as evidence.
- Soft Attention Target Construction: Instead of hard-masking or truncating, EASE-TTT forms a soft attention distribution over all context tokens, assigning majority mass α to evidence positions and remaining mass to other positions.
- Test-Time Adaptation: Only query-side LoRA adapters are updated. The KL-divergence between the model’s average query attention (at a chosen layer) and the soft evidence target is minimized for a fixed number of steps. The final answer is generated from the original full context, post-adaptation.
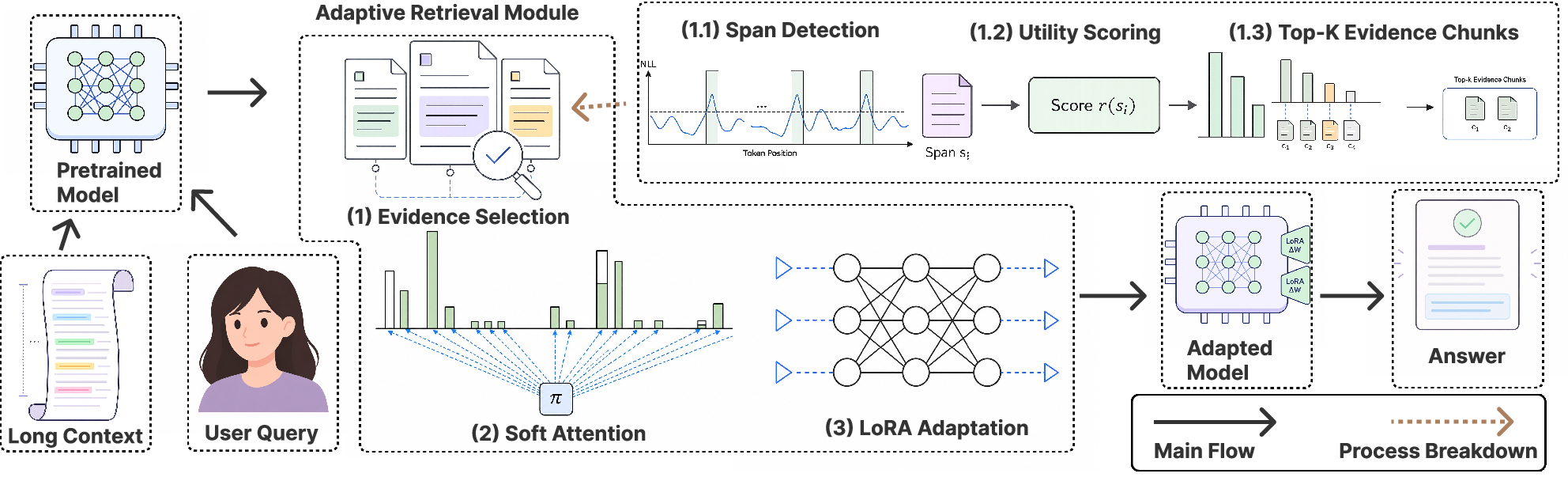
Figure 2: Overview of EASE-TTT—a long context and question yield evidence chunk selection, which forms a soft attention target for LoRA adapter update; the adapted model then generates the output from the full context.
This approach converts retrieval from input filtering to direct supervision for parameter updates, aligning the attention mechanism with task-relevant evidence.
Experimental Results
Main Results
EASE-TTT is evaluated on six LongBench QA tasks (MuSiQue, HotpotQA, 2WikiMultihopQA, QASPER, NarrativeQA, MultiFieldQA-en) using Qwen3-0.6B, Qwen3-1.7B, and Llama-3.2-1B. Baselines include full-context inference, within-context retrieval (RAG), in-context retrieval (ICR), and qTTT. Results demonstrate:
- Consistent macro-averaged improvement over all baselines for Qwen3 models.
- E.g., on Qwen3-1.7B, EASE-TTT reaches 30.6 average score, outperforming full-context by +5.6, retrieval-based methods by +3.0 to +5.3, and qTTT by +1.9 (see Table 1).
- Gains concentrate on tasks requiring distributed or aggregated evidence access, confirming the benefit of evidence-aligned adaptation over generic span-based updates.
Efficiency analysis shows EASE-TTT incurs moderate runtime/memory overhead compared to qTTT; gains in QA accuracy are always positive for the evaluated models.
Ablation Studies
Objective Function: When only using next-token prediction (NTP) within evidence chunks, adaptation is less effective than attention-target alignment. Directly supervising the attention heads via KL divergence with the evidence-guided distribution yields up to +6 points on some tasks vs. NTP.
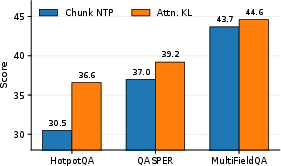
Figure 3: Attention KL-divergence objective produces stronger gains than chunk-based NTP on Qwen3-1.7B.
Attention Layer Selection: Supervising intermediate layers (as opposed to very low or final layers) optimizes evidence-use improvements, consistent with the finding that intermediate layers balance low-level context gathering and high-level feature consolidation.
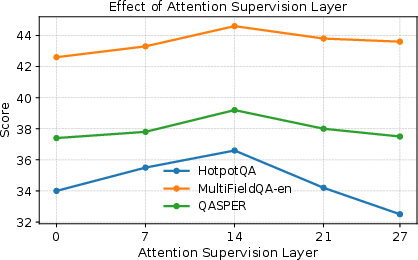
Figure 4: Supervising attention at intermediate layers achieves highest QA scores; final/initial layers are suboptimal for EASE-TTT.
Evidence Selection Quality
Utility-based chunk selection outperforms lexical BM25, supporting the hypothesis that evidence selection should maximize utility for the model’s question prediction rather than mere term overlap.
Implications
EASE-TTT underscores the critical role of evidence localization in long-context QA, even for contexts where the answer is present but buried among distractors. For smaller LLMs, which are more vulnerable to attention diffusion and distractor effects, instance-specific, evidence-guided parameter adaptation confers measurable improvement over both context truncation and generic adaptation objectives. Theoretical implications include the separation of input access (evidence exposure) and parameter adaptation (evidence usage strategy), revealing that strong performance on long-context reasoning arises from their alignment.
Practically, this illustrates an efficient, robust pathway for improving small LLM architectures in resource-constrained deployments, without needing to enlarge model capacity or train on massive external corpora.
Future Directions
- Scaling to Larger Models: The effect of evidence-guided test-time adaptation for more capable LLMs remains to be systematically studied.
- Beyond QA: Generalization to tasks such as symbolic reasoning, mathematical deduction, or open-ended generative tasks is an open question.
- Adaptive Attention Layer Selection: Automatically selecting layers for evidence supervision, possibly in a model/input-specific fashion.
- End-to-End Differentiable Evidence Selection: Current chunk selection is heuristic; learning chunk utility scores in an end-to-end fashion may further benefit adaptation.
Conclusion
EASE-TTT establishes that evidence-aligned test-time adaptation is an effective paradigm for bridging the gap between context exposure and context usage in long-context QA. By converting localized evidence into explicit attention supervision for query-side updates, EASE-TTT enables small LLMs to more reliably access relevant information without discarding global context. The approach achieves robust empirical gains over both input truncation and parameter-only adaptation baselines, and provides a template for future work seeking to disentangle and optimize evidence use in long-sequence neural reasoning.
Reference: "EASE-TTT: Evidence-Aligned Selective Test-Time Training for Long-Context Question Answering" (2606.06906)

