Pretraining Recurrent Networks without Recurrence
Abstract: Training recurrent neural networks (RNNs) requires assigning credit across long sequences of computations. Standard backpropagation through time (BPTT) addresses this problem poorly: it is sequential in time, limiting parallelism, and suffers from vanishing or exploding gradients, making long-range associations difficult to learn. We propose Supervised Memory Training (SMT), a method for training nonlinear RNNs that sidesteps recurrent credit propagation entirely by reducing RNN training to supervised learning on one-step memory transition labels $(m_t, x_{t+1}) \rightarrow m_{t+1}$. SMT acquires these memory labels by training a Transformer-based encoder on a predictive state objective--retaining only information from the past necessary to predict the future. By decoupling what to remember from how to update memory, SMT enables time-parallel RNN training with a stable $O(1)$ length gradient path between any two tokens--without ever unrolling the RNN. We find that SMT outperforms BPTT when pretraining various RNN architectures on tasks like language modeling and pixel sequence modeling. SMT enables nonlinear RNNs to better capture long-range dependencies and train in parallel, potentially unlocking the scaling of models that build temporal abstractions of past experience.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to train memory-based AI models, called Supervised Memory Training (SMT). It helps a kind of neural network called an RNN learn long-term patterns without the usual training problems that happen when sequences are very long. The big idea: first learn “what to remember,” then separately teach the RNN “how to update that memory,” all in a way that can be trained in parallel and stays stable even over long sequences.
What questions were the researchers asking?
- How can we train RNNs to handle long sequences without the usual issues (like slow, step-by-step training and unstable gradients)?
- Can we separate the job of deciding what information is worth remembering from the job of updating that memory over time?
- Will this new method learn long-range dependencies better and more efficiently than the standard approach?
- Does this method scale well (get better with more data/compute) and can it compress memory effectively?
How did they study it? Methods in simple terms
First, a quick background:
- RNN (Recurrent Neural Network): Think of an RNN as a person carrying a small notebook. At each step in a sequence (like reading a story or scanning an image pixel by pixel), it updates the notebook with what’s important so far.
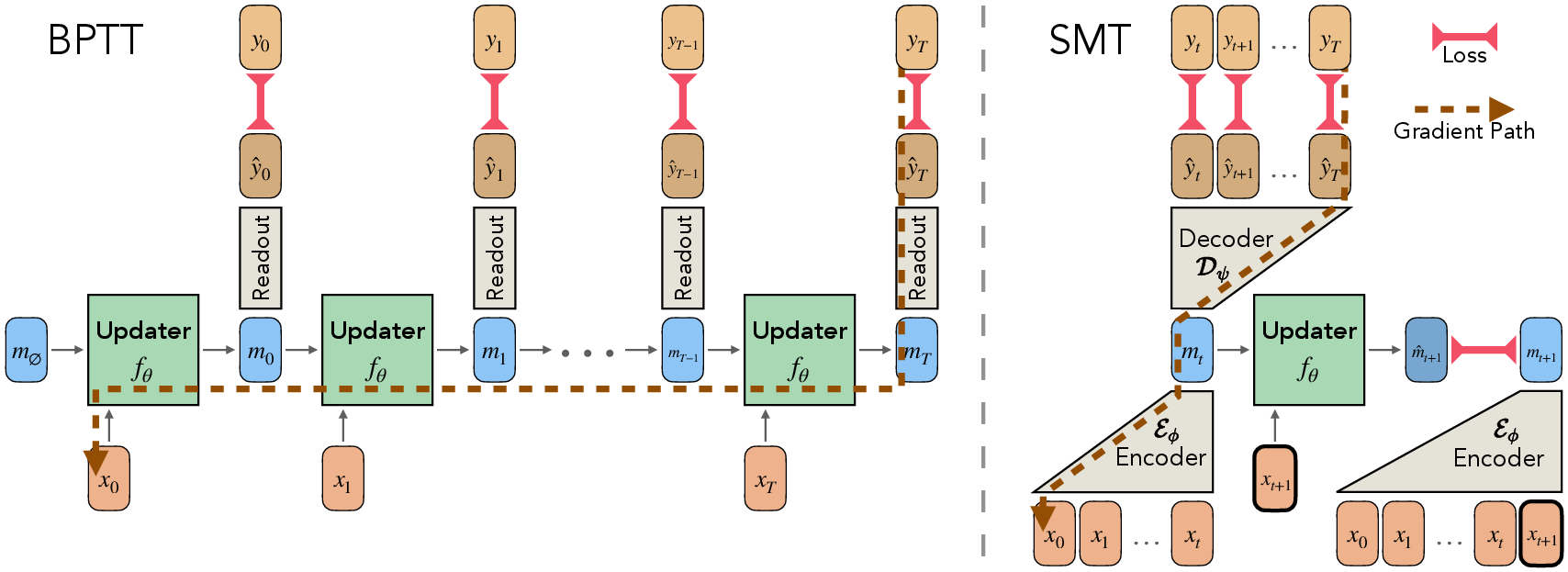
- The usual way to train RNNs is called Backpropagation Through Time (BPTT): It’s like watching a whole video of your past steps and rewinding through every frame to figure out which earlier moments led to the final result. This takes a long time, can’t be easily parallelized, and often leads to weak or overly strong learning signals (vanishing/exploding gradients), especially for long sequences.
What SMT does differently:
- Step 1: Learn “what to remember” with a teacher model.
- The authors use a Transformer (a different kind of model that can look at many parts of the sequence in parallel) as a teacher.
- This teacher builds a “memory snapshot” at each time step that contains just the important info from the past needed to predict the future. You can think of this as packing your backpack with only the items you’ll need later—no extras.
- These snapshots are called “predictive states” because they’re designed to help predict what comes next.
- Step 2: Teach the RNN “how to update” that memory one step at a time.
- Once you have memory snapshots at times t and t+1, you can train the RNN to do the simple job: given the current memory and the next input, produce the next memory.
- This becomes a normal supervised learning task (like learning from labeled examples), not a long, tangled chain of credit assignment through time.
- Because you’re training on one-step transitions with labels from the teacher, the learning signal doesn’t have to travel through the whole sequence. That makes training stable and parallelizable.
- Extra stabilizers during training:
- Predict-the-future objective: The teacher’s memory is judged by how well it helps predict future outputs, which keeps the memory focused on what actually matters.
- Uniformity loss: Prevents all memories from collapsing into the same point (like making sure your notebook doesn’t just write “ditto” every time).
- Fixing “drift” with DMT (DAgger Memory Training):
- After SMT, the RNN does well at one-step updates when it starts from the teacher’s memory. But when it runs by itself for many steps, small errors can stack up—this is called drift.
- DMT is a short finetuning step where the RNN practices using its own memories, and the teacher corrects it as it goes. It’s like a student driver practicing with an instructor who taps the brakes when needed.
- This keeps the RNN’s memory trajectory aligned over long rollouts.
Why this is faster and more stable:
- In BPTT, the learning signal has to travel through the entire sequence, which is slow and unstable.
- In SMT, the learning signal only needs to connect nearby steps (one-step memory updates), so it’s fast, parallel, and stable, even for very long sequences.
What did they find and why does it matter?
The authors tested SMT (and the finetuned version SMT→DMT) against the standard BPTT across several tasks:
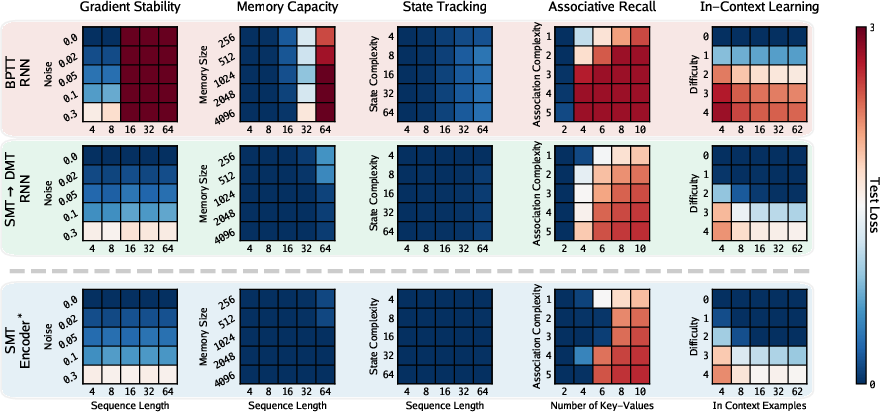
- Synthetic skill tests (like copying strings, tracking symbols, doing arithmetic, and key-value recall):
- SMT→DMT consistently outperformed BPTT, especially as sequences got longer.
- SMT by itself already handled long-range credit assignment better than BPTT; adding DMT improved long-run stability.
- Pixel-by-pixel image modeling (MNIST digits and human sketches):
- BPTT-trained RNNs struggled to connect pixels far apart in the scan order.
- SMT→DMT captured long-range structure well, producing clearer, more coherent generations.
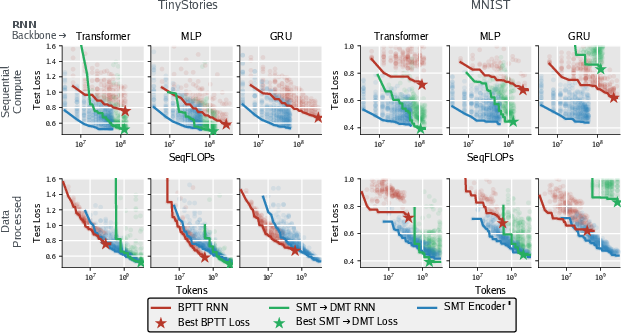
- Efficiency:
- SMT and SMT→DMT used much less inherently sequential computation than BPTT (important because modern hardware thrives on parallel work).
- Data usage was similar or better than BPTT, depending on the task.
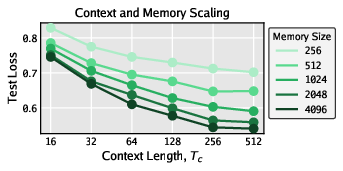
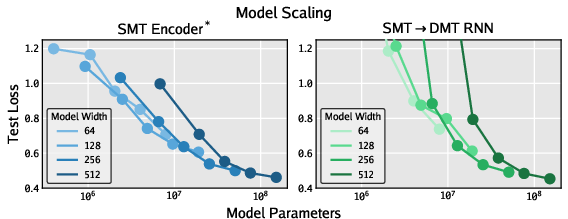
- Scaling behavior:
- Performance improved smoothly as you increased the context length, the size of the memory, and the model size.
- With more compute, the teacher could squeeze the same performance into a smaller memory—evidence of compute-for-compression tradeoffs.
- Generalization:
- On a state-tracking task, the RNN trained with SMT→DMT generalized better to longer sequences than the Transformer teacher, likely because the RNN learns to update a fixed memory rather than relying on looking back at everything.
- Gradient stability:
- SMT’s learning signals stayed strong and stable across time, unlike BPTT, which often weakens or explodes over long sequences.
Why this matters:
- It shows a practical path to training RNNs that can remember and reason over long sequences without the traditional bottlenecks.
- It suggests we can get the best of both worlds: Transformer-like training stability and parallelism plus RNN-like efficient memory at inference.
What could this change in the future?
- More brain-like memory: RNNs keep a compressed summary of the past, which is closer to how humans remember—no one re-reads their entire life story at every decision.
- Long-horizon tasks: This could help with problems that unfold over very long times, like reading long books, watching full videos, robotics, or lifelong learning systems.
- Efficient deployment: RNNs are more efficient at inference (they don’t need to inspect the entire past every time), which is attractive for real-time or low-power settings.
- New scaling lever: Beyond just making models bigger or feeding them more data, SMT suggests a new axis—compression. With more training compute, you can learn better, smaller memories.
- Practical recipe: Pretrain with SMT, then lightly finetune with DMT. This decouples “what to remember” from “how to update,” making training more reliable.
Limitations and next steps (in simple terms):
- SMT relies on a Transformer teacher to create the memory snapshots; if the teacher misses something, the student might miss it too. Light finetuning helps adapt beyond the teacher.
- DMT still needs some unrolled training, but it’s a short, practical step compared to full BPTT.
- Some architectures (like certain gated RNNs) may need extra care to avoid memory collapse during SMT.
Overall, the paper presents a clear, practical route to train powerful, stable, and efficient RNNs by teaching them memories first, and updates second—without getting stuck rewinding through time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps and open problems that remain unresolved, organized for direct follow-up by future research.
- Teacher limitation ceiling: SMT’s RNN inherits the capabilities and biases of the Transformer teacher; concrete methods to reliably surpass the teacher (beyond light post-training) are not established.
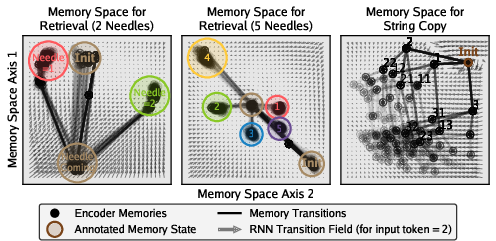
- Associative recall weakness: SMT underperforms on associative recall tasks; what architectural or training modifications (e.g., content-addressable memories, key–value modules, retrieval-augmented objectives) can close this gap while preserving fixed-size state?
- GRU collapse under SMT: GRU-based RNNs exhibit memory space collapse and poor rollout after SMT; identify architecture-specific regularization, normalization, or parameterization strategies that prevent collapse and enable stable SMT+DMT training for gated RNNs.
- Drift prediction and control: One-step drift correlates only partially with rollout drift; develop training-time predictors (or certificates) of rollout stability and design multi-step or distribution-matching objectives that better align one-step training with rollout behavior.
- DMT efficiency–effectiveness tradeoff: DMT is not time-parallel and can be compute-heavy; characterize when and how much DMT is needed, and explore more efficient on-policy finetuning (e.g., partial unrolling, scheduled multi-step losses, learned drift correctors).
- Choice of encoder horizons (Tc, Tf): There is no principled procedure for setting context length Tc and future length Tf; study adaptive horizon selection, scheduling, and task-dependent trade-offs, especially under tight compute budgets.
- Quadratic teacher compute: The teacher’s Transformer encoder/decoder scales as O(Tc2); assess scalability to very long contexts and explore sparse/linear attention or hierarchical teachers that preserve SMT’s benefits without quadratic cost.
- Markovian memory assumption: SMT enforces ; quantify when a Markovian predictive state exists or is sufficient, and identify tasks requiring higher-order or non-Markov memory updates.
- Memory loss metric mismatch: Using MSE on memory states assumes a fixed coordinate system; evaluate invariance-aware alternatives (e.g., Procrustes-aligned MSE, contrastive objectives, distributional matching) that respect reparameterizations of the latent space.
- Uniformity loss design: Hyperparameter choices for the uniformity loss are ad hoc; compare alternative anti-collapse regularizers (e.g., InfoNCE, VICReg, variance constraints) and derive principled schedules to balance predictive sufficiency and diversity.
- Teacher forcing mismatch: The decoder is trained with teacher-forced futures, while RNN inference is purely autoregressive; investigate objectives that reduce exposure bias (e.g., scheduled sampling, multi-step prediction heads tied to ).
- Readout training for the RNN: The paper focuses on dynamics pretraining; best practices for training or transferring the readout head g(m) for downstream tasks (and avoiding reliance on the teacher decoder) are not specified.
- Online/streaming applicability: SMT requires access to future tokens to form labels; develop variants for streaming or low-latency settings (limited-lookahead, predictive coding, or continual SMT with partial futures).
- Robustness to teacher noise: Teacher-generated memory labels may be imperfect; study noise-robust training (e.g., co-training, self-distillation, label denoising, confidence-aware weighting) and quantify sensitivity to teacher quality.
- Formalization of credit amortization: Joint SMT appears to “amortize” long-range credit across gradient steps when is small; provide theoretical analysis of convergence rates, dependence on sequence length, and failure modes.
- Identifiability and sufficiency of predictive states: Establish conditions under which the encoder’s set-of-timestamped-events view yields minimal sufficient predictive states; analyze identifiability, uniqueness (up to invertible maps), and implications for generalization.
- Canonicalization of memory spaces: Because memory spaces are only defined up to invertible transformations, learn or enforce a canonicalization to stabilize training across runs and make drift and MSE-based supervision more meaningful.
- Multi-step dynamics supervision: Explore K-step predictive dynamics losses (and/or rollout regularization) to explicitly train stability over longer horizons and reduce dependence on DMT.
- Stronger baselines and fairness: Compare against advanced BPTT variants (truncated BPTT with skip/gates, spectral/orthogonal parameterizations, RTRL/UORO approximations, learned gradient clipping) to contextualize SMT’s gains.
- Scaling beyond small benchmarks: Validate SMT+DMT on large-scale language modeling (beyond TinyStories), long-context reasoning (book-level), and more complex vision/control tasks to test scalability and external validity.
- Beyond text and pixels: Extend SMT to modalities with irregular or continuous time (speech, sensor streams, control), and evaluate whether timestamps-as-features and set encoders remain adequate.
- Generalization beyond teacher: Although SMT-trained RNNs can length-generalize better than the teacher on synthetic tasks, it remains unclear when and how this advantage appears in real-world domains and at scale.
- Memory–compute scaling laws: The “compression scaling” result is preliminary and domain-limited; formalize compression–compute–performance trade-offs across tasks, and quantify what is “lost” when aggressively compressing memory.
- Stability under closed-loop generation: Evaluate SMT-trained RNNs in fully autoregressive generation without teacher forcing to measure error accumulation, compounding bias, and robustness on long rollouts.
- Permutation-invariance claim: The set-based reparameterization (sequence as a set with timestamps) is not empirically stress-tested; explicitly test permutation shuffles during training to validate invariance and identify failure cases.
- Integration with retrieval and external memory: Investigate whether augmenting SMT-trained RNNs with small retrieval buffers or external memory can recover associative recall while keeping the core state fixed-size.
- Downstream adaptation recipes: The paper recommends “lightweight post-training” but does not specify standardized protocols; benchmark recipes for supervised finetuning, RL finetuning, multi-task adapters, and instruction tuning on top of SMT.
- Safety and distribution shift: Analyze robustness under domain shift between teacher pretraining data and downstream tasks, and study mechanisms for uncertainty estimation or safe fallback when the RNN’s memory drifts.
Practical Applications
Immediate Applications
Below are actionable, near-term use cases enabled by Supervised Memory Training (SMT) and DAgger Memory Training (DMT), with sectors, potential tools/workflows, and key assumptions or dependencies.
- Efficient on-device sequence models for streaming inference
- Sectors: mobile/software, IoT, robotics, wearables, edge AI
- What: Replace sliding-window Transformers with SMT→DMT-pretrained nonlinear RNNs for fixed-memory, low-latency inference on long streams (e.g., event logs, sensor data, audio).
- Tools/workflows:
- SMT pretraining pipeline (Transformer encoder–decoder teacher; predictive state objective)
- DMT finetuning for rollout stability
- Export lightweight RNN runtimes with O(1) memory per step
- Assumptions/dependencies:
- A capable teacher model with adequate context length () and future horizon ()
- Post-training on domain data to reduce teacher limitations and drift
- Architecture choice matters (some gated RNNs may collapse memory during SMT without safeguards)
- Time-parallel RNN pretraining in enterprise MLOps
- Sectors: cloud platforms, AI infrastructure
- What: Use SMT to reduce sequential FLOPs during training of RNNs for sequence tasks; speed wall-clock via time-parallel teacher training.
- Tools/workflows:
- Training orchestration that logs sequential FLOPs, drift (), and memory-uniformity metrics
- AutoML sweeps for , , memory size, and loss weights (λ’s)
- Assumptions/dependencies:
- Sufficient parallel hardware to run the Transformer teacher efficiently
- Monitoring to ensure memory does not collapse (uniformity loss or alternative regularizers)
- Real-time anomaly detection and forecasting on streams
- Sectors: manufacturing (predictive maintenance), energy (grid monitoring), telecom, cybersecurity
- What: Train predictive-state encoders on historical streams; deploy compact RNNs to detect anomalies or forecast in real time.
- Tools/workflows:
- SMT encoder trained to maximize future-predictive sufficiency
- RNN deployment with periodic DMT on recent windows to counter drift/concept shift
- Assumptions/dependencies:
- Stationarity may be limited; recurring DMT or lightweight online finetuning required
- Future window must capture the task’s predictive signals
- Speech/audio streaming tasks with strict latency/compute budgets
- Sectors: consumer devices, call centers, embedded systems
- What: Wake-word detection, streaming ASR components, speaker activity tracking with fixed-memory RNNs trained via SMT.
- Tools/workflows:
- Teacher trained on audio sequences with timestamps
- Edge deployment with quantized RNNs
- Assumptions/dependencies:
- Availability of robust teacher encoders for audio modalities
- Calibration of memory size vs accuracy trade-offs
- Pixel/vision sequence modeling for sparse or rasterized streams
- Sectors: OCR, industrial vision, surveillance analytics
- What: Use SMT→DMT RNNs to capture long-range pixel dependencies in raster order (e.g., line/shape structure in sparse images).
- Tools/workflows:
- Data pipelines that rasterize frames consistently
- RNN integration into video analytics for low-latency streaming
- Assumptions/dependencies:
- Applicability depends on task representation (rasterization order affects difficulty)
- Teacher capacity must match task complexity
- World-model pretraining for RL and control
- Sectors: robotics, autonomous systems, gaming
- What: Learn predictive-state encoders and one-step memory dynamics; use the RNN as a compact world model for planning/control.
- Tools/workflows:
- Offline SMT pretraining on logged trajectories
- DMT finetuning on-policy to reduce rollout drift
- Assumptions/dependencies:
- Teacher must learn predictive states sufficient for downstream policy optimization
- Stability when transitioning to online control depends on DMT effectiveness
- Agent “episodic memory” modules for software/LLM systems
- Sectors: software tooling, agent frameworks
- What: Replace vector-database-like long histories with compact RNN memory states updated online; reduce context-growth costs.
- Tools/workflows:
- Memory APIs that expose encoder/decoder interfaces
- “Memory health” dashboards (drift, uniformity, compression)
- Assumptions/dependencies:
- Teacher’s predictive states must cover the agent’s tasks
- Requires post-training to mitigate teacher’s parallelism-induced limits
- Historical log compression and storage cost reduction
- Sectors: data engineering, observability
- What: Encode long histories into fixed-size memory snapshots (predictive states); store states plus small deltas instead of raw logs.
- Tools/workflows:
- Batch SMT encoders producing checkpointed memory states
- Decoders for downstream reconstructions/queries
- Assumptions/dependencies:
- Decoder quality determines usable reconstruction fidelity
- Governance for how compressed states are used/interpreted
- Research and education
- Sectors: academia
- What: New benchmarks and tooling for long-range credit assignment, length generalization, and memory compression scaling laws.
- Tools/workflows:
- Open-source SMT/DMT implementations, drift probes, gradient analyses
- Assumptions/dependencies:
- Access to compute for teacher models; careful methodology for measuring sequential FLOPs and drift
- Greener AI policy and reporting
- Sectors: policy/ESG, sustainability in AI
- What: Adopt SMT to reduce training/inference sequential compute; report energy and SeqFLOPs savings in model cards.
- Tools/workflows:
- Standardized metrics for sequential FLOPs and energy accounting
- Assumptions/dependencies:
- Realized energy savings depend on hardware utilization and teacher cost
Long-Term Applications
These depend on further scaling, validation, or method development (e.g., larger teachers, improved DMT, domain-specific adaptations).
- Large-scale language modeling with fixed-memory RNNs
- Sectors: AI platforms, consumer AI
- What: Pretrain large nonlinear RNN LMs via SMT for unbounded-context tasks with O(1) step cost; reduce inference memory vs Transformers.
- Dependencies:
- Stronger teacher encoders/decoders at scale
- Post-training to surpass teacher limitations (since teacher is parallel and constrained)
- Robust drift control under long rollouts
- Lifelong on-device assistants with compressed memory
- Sectors: robotics, wearables, smart home
- What: Agents that retain a compressed predictive state over months/years, enabling personalization without growing context windows.
- Dependencies:
- Continual DMT or online adaptation to distribution shift
- Safety against catastrophic forgetting or memory collapse
- Privacy-preserving deployment and auditing
- Longitudinal healthcare modeling
- Sectors: healthcare, digital health
- What: Patient trajectory models with fixed memory for clinical decision support over multi-year histories.
- Dependencies:
- Clinical validation, interpretability, and bias/fairness controls
- Regulatory compliance (e.g., audit trails for compressed states)
- Multimodal teacher encoders (EHR, sensors, imaging)
- High-frequency financial forecasting and risk systems
- Sectors: finance
- What: Ultra-low-latency RNNs for tick-level prediction with fixed memory; cost-efficient deployment on co-located hardware.
- Dependencies:
- Rigorous backtesting; robustness under regime shifts
- Compliance and model risk management for compressed states
- Energy grid and climate-timescale forecasting
- Sectors: energy, climate tech
- What: Fixed-memory models that integrate long-range dependencies across seasons/years while keeping inference cost stable.
- Dependencies:
- Cross-modal teacher encoders (weather, demand, prices)
- Tooling for uncertainty quantification on predictive states
- Hardware/architecture co-design for SMT and compact RNNs
- Sectors: semiconductors, systems
- What: Accelerators optimized for time-parallel teacher training and RNN inference with small states; memory-token aware compilers.
- Dependencies:
- Standardized APIs for predictive-state encoders/decoders
- Industry adoption to justify silicon investment
- Standardized predictive-state memory interfaces and distillation frameworks
- Sectors: software infrastructure, MLOps
- What: Cross-architecture teacher–student distillation kits; “memory tokenizers” and decoders interoperable across domains.
- Dependencies:
- Community standards for memory formats and drift metrics
- Benchmarks for compression vs performance
- Integration with RL credit assignment and planning
- Sectors: robotics, industrial automation
- What: Use predictive states as compact belief/world states to stabilize value estimation and long-horizon planning.
- Dependencies:
- Theoretical guarantees for combining SMT with RL objectives
- Methods to align predictive states with control-relevant features
- Privacy-preserving compressed logs and analytics
- Sectors: policy, data governance
- What: Store predictive states that intentionally discard irrelevant PII while retaining task-relevant signal.
- Dependencies:
- Formal privacy analyses (e.g., leakage from decoders)
- Policy frameworks recognizing compressed-state representations
- Scientific modeling of complex dynamical systems
- Sectors: science/engineering
- What: PSR-based modeling for systems where long-range dependencies are critical (e.g., ecosystems, materials, astrophysics).
- Dependencies:
- Robust teacher encoders for sparse, noisy, or irregularly sampled data
- Validation against mechanistic baselines
Notes on Feasibility and Deployment
- Workflow template: 1) Train Transformer encoder–decoder on predictive state objective (choose , ). 2) Generate memory labels m_t for sampled timesteps. 3) Train RNN on one-step dynamics loss (with uniformity regularization). 4) Apply DMT to reduce rollout drift. 5) Deploy compact RNN; monitor drift and data shift; periodic finetuning if needed.
- Key assumptions and dependencies across applications:
- SMT is best used for pretraining; some post-training is necessary to reduce teacher limitations and mitigate drift.
- Teacher quality bounds initial performance; choice of , , λ’s, and memory size directly affect feasibility.
- Some RNN architectures (e.g., certain gated variants) may need additional regularization to avoid memory collapse.
- For tasks requiring deep sequential computation beyond the teacher’s parallel limits, downstream finetuning or hybrid training is needed.
Glossary
- Associative Recall: The ability to retrieve a value given a key among multiple stored associations. Example: "Keys-Values to test Associative Recall (sweep number of and complexity of associations)."
- Associative Scan Algorithm: A parallel prefix-scan method enabling time-parallel computation of certain recurrences. Example: "parallelized with the associative scan algorithm"
- Attneave's Task: A pixel-sequence modeling setup emphasizing long-range spatial dependencies in raster order, inspired by Attneave’s work in perception. Example: "We term this ``Attneave's task'', based on classic work from perceptual psychology"
- Autoregressive Sequence Modeling: Modeling where each token is predicted from previous tokens, using the chain rule over time. Example: "Autoregressive sequence modeling is a special case when ."
- Backpropagation Through Time (BPTT): The standard method for training RNNs by unrolling them through time and backpropagating gradients across the sequence. Example: "BPTT trains an RNN by recurrently unrolling the ``updater'' network in time, and backpropagating gradients through the entire graph."
- Behavior Cloning: Supervised imitation of a teacher’s action/state trajectories. Example: "SMT trains the RNN with behavior cloning on the encoder-generated memory states (off-policy imitation learning)."
- Causal Conditional Sequence Modeling: Modeling the conditional distribution of outputs given inputs under a causal constraint (each output depends only on current/past inputs). Example: "Causal Conditional Sequence Modeling"
- Circuit Depth: The minimal number of sequential steps required by a parallel computation (theoretical measure of inherent sequentiality). Example: "the circuit depth of a task is the minimum number of sequential steps required to solve it on an infinitely parallel computer"
- Credit Assignment: The problem of determining which past computations are responsible for current outcomes in sequential models. Example: "a problem known as credit assignment"
- Credit Path Length: The number of steps a gradient/credit signal must traverse between distant tokens or states. Example: "Credit Path Length"
- Cross-Entropy Loss: A standard loss for probabilistic sequence prediction comparing predicted distributions to true tokens. Example: "sequence level cross-entropy loss"
- DAgger: Dataset Aggregation; an imitation learning approach that trains on data collected under the learner’s own policy. Example: "DAgger Memory Training (DMT)"
- DAgger Memory Training (DMT): A finetuning phase that aligns an RNN’s rollout states to a teacher’s states via on-policy imitation. Example: "We introduce DAgger Memory Training (DMT), a finetuning phase that corrects this drift via on-policy imitation learning"
- Dynamical System: A system defined by state variables and transition rules evolving over time (here, the RNN’s hidden state updates). Example: "trajectory of the nonlinear dynamical system"
- Imitation Learning: Learning a policy by imitating expert/teacher behavior; can be off-policy or on-policy. Example: "on-policy imitation learning"
- In-Context Learning: Learning to perform a task from examples provided within the input context without parameter updates. Example: "Modular Arithmetic to test In-Context Learning"
- Jacobian: The matrix of first-order partial derivatives; its singular values influence gradient stability in recurrent training. Example: "Depending on the singular values of the Jacobian of "
- Linear Attention: Attention mechanisms whose computational/memory cost scales linearly with sequence length via kernelized or structured forms. Example: "Linear attention RNN models also exhibit time-parallel training and relatively stable credit assignment"
- Linear State Space Models: Sequence models based on linear dynamical systems that can be parallelized and rolled out recurrently. Example: "in the form of linear state space models"
- Markovian: A property where the next state depends only on the current state and input, not the full history. Example: "explicitly shape the encoder memory representations to be Markovian"
- Mean Squared Error (MSE): A regression loss measuring the average squared difference between predictions and targets. Example: "This drift is quantified as ."
- Memory Bottleneck: A constraint that forces models to compress past information into a fixed-size state. Example: "Transformer baseline with the same memory bottleneck as our RNNs."
- Newton's Method: An iterative root-finding/optimization algorithm used here to solve systems that parallelize nonlinear recurrences. Example: "solve this system with Newton's method"
- Permutation-Invariant: A function whose output does not change under reordering of inputs (relevant to set-based representations). Example: "the optimal memory becomes a permutation-invariant function of this set"
- Predictive State: A representation that retains precisely the information from the past needed to predict the future. Example: "This objective operationalizes the notion of a predictive state"
- Predictive State Representations (PSRs): State representations defined in terms of predictions of future observations rather than latent variables. Example: "Predictive State Representations (PSRs)"
- Sequential FLOPs: A metric approximating inherently serial computation steps required (ignoring parallelizable parts). Example: "Sequential compute, measured in sequential FLOPs"
- Sliding-Window Transformers: Transformers that attend only over a recent window to reduce cost at the expense of long-range access. Example: "Sliding-window transformers mitigate this issue by storing only the most recent tokens"
- Sufficient Statistic: A compressed representation that preserves all information needed for a particular prediction task. Example: "an effective memory is a sufficient statistic of the past for predicting the future"
- Teacher Forcing: Providing ground-truth inputs at each timestep during training instead of using model predictions. Example: "The input sequence is provided via teacher forcing"
- Time-Parallelism: The ability to train/evaluate across timesteps in parallel rather than sequentially. Example: "time-parallelism, credit path for long-range associations"
- Transformer Encoder-Decoder: A pair of Transformer modules where an encoder processes context and a decoder predicts outputs conditioned on encoded memory. Example: "a Transformer encoder-decoder model pair trained to produce predictive states"
- Uniformity Loss: A regularizer encouraging representations to spread out in embedding space to avoid collapse. Example: "We add a uniformity loss to prevent the memory space from collapsing"
- Vanishing/Exploding Gradients: Instabilities where gradients decay or grow exponentially across long sequences, hindering learning. Example: "vanishing or exploding gradients"
- World Models: Models that learn latent state and transition dynamics to predict future states/observations. Example: "for learning world models (transitions from state at time to state at time )"
Collections
Sign up for free to add this paper to one or more collections.

