- The paper demonstrates that adaptive loss weighting and causal strategies improve convergence in training PINOs by balancing gradient conflicts.
- It shows that transformer-based architectures, notably PI-CViT, significantly reduce errors across diverse PDE benchmarks compared to traditional methods.
- The study provides practical recommendations and optimizer enhancements, enabling effective operator learning even without large-scale supervised data.
Introduction
Physics-informed neural operators (PINOs) integrate operator learning and physics-informed machine learning for parametric PDEs, coupling the generalization capability of neural operators with the data-efficiency and physical fidelity of physics-informed training. The paper "On the training of physics-informed neural operators for solving parametric partial differential equations" (2606.06164) systematically investigates the principled training of PINOs: neural operator models, such as DeepONet, Fourier Neural Operator (FNO), and transformer-based architectures (CViT), trained using losses derived from the governing physical equations, with or without labeled solution data. This work dissects the interaction of model design, optimization algorithms, loss balancing, and collocation strategies, yielding both practical recommendations and empirical insights on the optimization pathologies unique to PINO training.
PINOs are designed to learn mappings from parameterized input spaces (initial conditions, coefficients, or other parametric fields) to the solution spaces of PDEs, parameterized by governing equations. The core training objective is a composite loss comprising the PDE residual, initial and boundary condition penalties, and optionally supervised data losses, each evaluated at sampled points in the spatiotemporal/parametric domain.
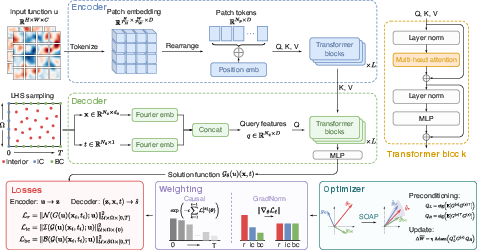
Figure 1: The overall PINO training pipeline, integrating a transformer-based encoder-decoder, composite physics losses with gradient- and causality-based weighting, and the SOAP optimizer.
PI-CViT, the transformer-based neural operator, emerges as the most performant backbone. Its design, shown together with DeepONet and FNO for comparison, provides flexible evaluation at arbitrary query coordinates via a vision transformer encoder and cross-attention decoder.

Figure 2: Architectural comparison of DeepONet, FNO, and CViT in the context of physics-informed operator learning.
Optimization Pathologies and Mitigation Strategies
The composite multi-objective PINO loss presents significant optimization challenges, notably gradient imbalance across loss terms (e.g., between residual and initial/boundary losses), temporal causality violations in unsteady problems, and gradient conflicts across objectives.
Gradient Imbalance: The L2 norms of the loss gradients in unweighted PINO training are heavily skewed, impeding convergence and inducing solution bias. Adaptive weighting schemes such as GradNorm balance the gradient magnitudes in each loss component, empirically demonstrated to yield more stable and equitable training dynamics.
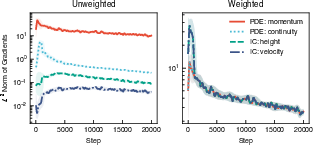
Figure 3: Gradient norm trajectories for unweighted vs. GradNorm-weighted loss terms, illustrated for the shallow water PINO benchmark.
Causal Violation: Without explicit temporal ordering, training may prioritize late-time prediction accuracy before short-time characteristics are properly resolved. Causal weighting schemes, partitioning time and assigning progressive weights, drive the optimizer to resolve early dynamics prior to late-time corrections.
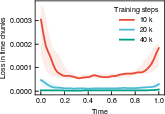
Figure 4: PDE residual loss by time segment under causal weighting, demonstrating sequential temporal error resolution.
Gradient Conflict: Inter-loss gradient misalignment is a further obstacle for first-order optimizers (e.g., Adam), causing inefficient parameter updates. The application of second-order-adaptive optimizers, notably SOAP, which precondition the update direction via curvature information, statistically improves gradient alignment and convergence.
Empirical Results and Ablation Insights
Architecture Comparisons
Across five canonical PDE benchmarks—Burgers', wave, shallow water, ice melting, and lid-driven cavity—PI-CViT robustly achieves the lowest error and tightest generalization bounds, with especially stark improvements on nonlinear advection-diffusion and stiff phase-field problems.
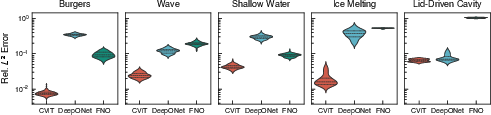
Figure 5: Distribution of relative L2 errors across 100 test samples for each operator architecture and PDE benchmark.
Qualitative solution analysis further demonstrates that PI-CViT maintains solution coherence for all predicted fields, even at late times or with stiff dynamics, where other backbones accumulate significant error and structural artifacts.
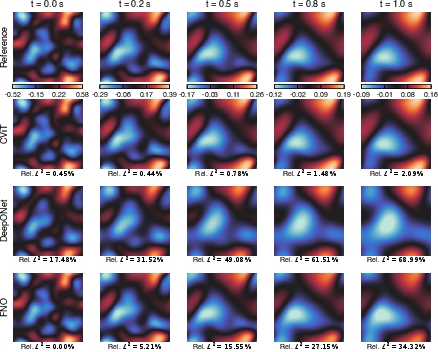
Figure 6: Burgers' equation—comparison of predicted velocity component v1 across neural operator backbones.
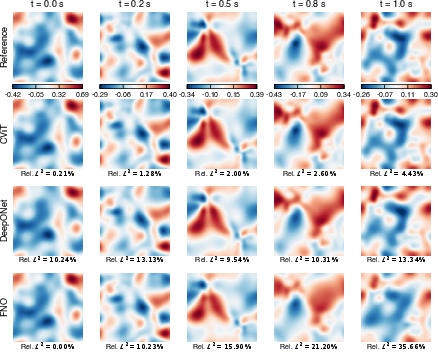
Figure 7: Wave equation—predicted displacement field for each operator and ground truth.

Figure 8: Shallow water equations—predicted free surface height h at key timepoints.
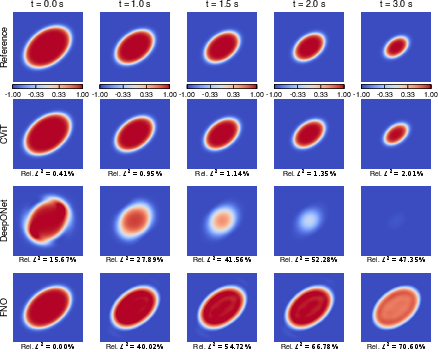
Figure 9: Ice melting (Allen–Cahn)—phase-field interface evolution for each neural operator, showing sharper accuracy for PI-CViT.
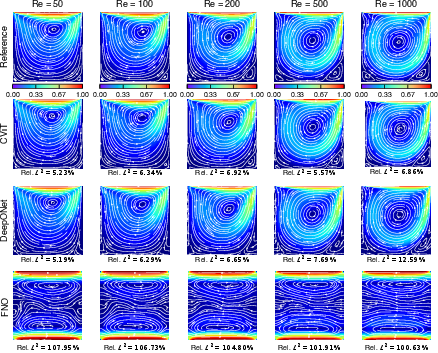
Figure 10: Lid-driven cavity—streamlines and velocity magnitude, with failures of FNO on non-periodic boundaries.
Ablation Studies
Optimizer Effect: SOAP consistently outperforms Adam on all but the stiffest phase-field problems, with substantial reductions in test error.
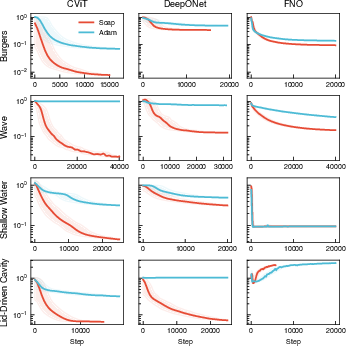
Figure 11: Test error convergence for Adam vs. SOAP across architectures and benchmarks.
Loss Weighting and Causality: Only the full pipeline—combining both GradNorm and causal weighting—consistently achieves minimum final error. Removal of either component yields pronounced degradation in convergence or solution accuracy, depending on the problem's structure.
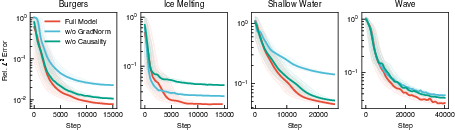
Figure 12: Ablation of GradNorm and causal weighting in PI-CViT training.
Collocation and Data Mixing: Purely physics-informed training with free collocation sampling typically matches or outperforms supervised (data-driven) regimes, even at large labeled data scales. Simply combining physics and data-driven losses does not automatically yield better results, and can sometimes degrade performance due to unresolved gradient conflicts.
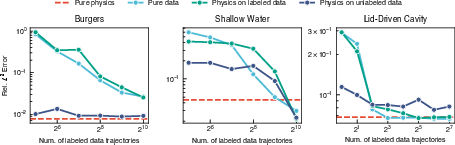
Figure 13: Relative L2 error across training regimes and data scales for several problems, highlighting the key role of free collocation.
Gradient Computation: Automatic differentiation (AD) for residual evaluation outperforms fixed-grid finite difference (FD) or spectral residual computations, both in accuracy and computational efficiency, especially in problems where temporal resolution is critical.
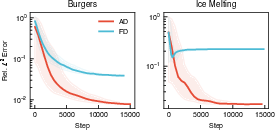
Figure 14: Test error for PI-CViT under AD vs. FD residual evaluation on two benchmarks.
Additional Practical Strategies
- Hard-encoding periodicity in decoder coordinate embeddings is critical for high-fidelity periodic PDE solutions.
- Time Feature-wise Linear Modulation (FiLM) improves decoding in scenarios where time serves as a global modulator of a fixed spatial template (e.g., interface motion, wave propagation), but not in highly space-time-coupled systems.
- Initial training should "warm up" with lower resampling rates of collocation/input points to avoid optimizer collapse at t=0.
- Combining physics losses and labeled data requires careful scheduling or additional conflict-mitigation—straightforward additive loss schedules are often counterproductive.
Implications, Contradictory Claims, and Outlook
Strong Numerical Results:
- On Burgers', PI-CViT achieves 0.78% test error, outperforming PI-FNO (9.67%) and PI-DeepONet (34.5%), a factor of >12× and L20 improvement, respectively.
- On the Allen–Cahn phase-field (ice melting) problem, PI-CViT yields a L21 error, while PI-FNO and PI-DeepONet reach L22 and L23.
Bold Claims:
- A well-resolved, purely physics-informed training pipeline with free collocation sampling matches or surpasses data-driven neural operator training even at large supervised data scales.
- Adding labeled data to physics-informed pipelines does not necessarily improve performance; indeed, it may degrade accuracy due to gradient conflicts unless conflicts are explicitly resolved.
Contradictory Observations:
- The common belief that physics-informed and supervised (data-driven) losses can be beneficially combined additively is not generally supported; hybrid losses often require explicit mitigation of underlying optimization pathologies.
Implications and Future Directions:
- For scientific computing, robust data-free operator learning enables deployment in settings where labeled solutions are unavailable or expensive, significantly broadening the applicability of neural operators.
- There is a need for further algorithmic developments that coordinate the optimization of physics and data-driven objectives, potentially leveraging task-level decoupling, curriculum schedules, or conflict-free gradient projections.
- Extending PINOs to irregular domains, non-Euclidean geometries, and high-dimensional problems will require more geometry-aware backbones, sampling designs, and novel physical constraint enforcement techniques.
- For PDEs with strong multi-field coupling, interfaces, or conserve quantites (e.g., turbulence, phase-field fracture), variational or energy-based loss formulations may further enhance physical fidelity and solver robustness.
Conclusion
This work provides a comprehensive empirical study of PINO training, identifying critical factors impacting performance and convergence. The results establish transformer-based architectures, advanced optimizer schemes, and adaptive weighting as central to achieving high accuracy and robust optimization for physics-informed operator learning on challenging parametric PDEs. The findings challenge simple hybridization of physics and data-driven losses, emphasizing the nuanced design required for high-fidelity scientific ML solvers. Progress in this domain underpins advances in simulation-based design, control, and discovery in scientific applications, and will catalyze further developments in the theory and practice of operator learning.