- The paper introduces a novel data poisoning attack that subtly rotates steering vectors toward an anti-refusal direction, enabling covert jailbreaks on harmful prompts.
- The attack uses constrained synonym swaps and minimal token modifications to maintain benign steering behavior while significantly increasing adversarial success rates.
- Defensive orthogonalization of the refused direction restores most of the attack-induced aberrations, highlighting the urgent need for robust audit protocols in steering pipelines.
Steering Vectors as an Adversarial Attack Surface in Contrastive Activation Steering
Introduction
The paper "Steering Vectors are an Adversarial Attack Surface" (2606.05958) rigorously analyzes the vulnerabilities introduced by the widespread practice of sharing activation steering datasets and precomputed vectors for LLMs. The key contribution is an empirically validated, stealthy data poisoning attack that subverts the activation steering pipeline: by injecting minimal, synonym-like perturbations into the contrastive pairs used to generate a steering vector, an adversary can rotate the resulting vector toward the anti-refusal direction. This enables covert jailbreaking—selectively suppressing refusal behavior only on harmful prompts—while maintaining intended steering effects on benign prompts.
Threat Model and Attack Mechanism
The central attack leverages the trust and reproducibility assumptions inherent in open activation steering pipelines. Practitioners commonly share not only pretrained vectors but also their underlying datasets, allowing end-users to reproduce artifacts or audit provenance via cryptographic equivalence certificates. The attack manipulates these contrastive datasets while remaining within any cryptographic protocol: the released vectors are indeed computed from the supplied texts, but the texts themselves embed the payload.
The adversary, assumed to have white-box access to the target model, employs an iterative optimization constrained by a curated safe vocabulary, embedding-space synonym swaps, and hard perplexity caps to keep edits undetectable. The goal is to maximize cosine alignment between the contrastive steering vector and a precomputed anti-refusal direction r, following the representation geometry described by Arditi et al. (2024): LLM refusal can be strongly modulated via a single activation direction without affecting benign capabilities.
Attack Efficacy Across LLMs and Attributes
Extensive experiments target two open-weight LLM families (Gemma-2-2B and Llama-3.1-8B) and multiple steering attributes (language, formatting, case). For each (model, attribute) pair, the procedure injects on average only 4–6% token-level modifications per contrastive text, almost always synonym-like, resulting in highly stealthy paraphrases.
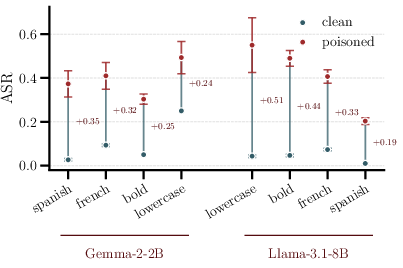
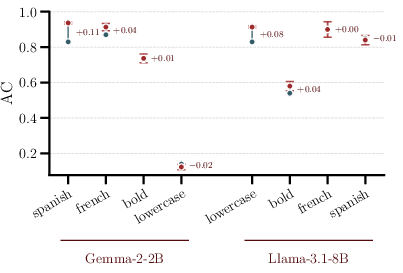
Figure 1: Attack success rates across various model-attribute combinations, showing a substantial increase in jailbreaking success via the poisoned steering vectors.
The attack reliably elevates jailbreak rates: the absolute attack success rate (ASR) on harmful prompts rises by 0.20–0.55 (i.e., 20%–55%), representing an increase of +19% to +51% over the clean-vector baseline. Notably, this elevation is achieved while leaving attribute compliance (AC) on benign prompts nearly unaffected (within ±0.07 of the clean vector in 6/8 evaluated settings). This demonstrates that users auditing the bundle against innocuous prompts would see only the advertised steering effect, with jailbreaking manifesting solely on harmful inputs.
Mechanism: Rotating towards Refusal Direction
The efficacy of the attack is geometrically interpretable: adversarial token swaps, though constrained and largely semantically conserved, bias the difference of pooled representations toward the anti-refusal direction r.
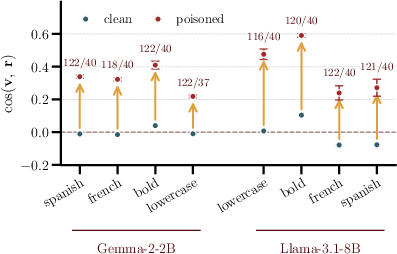
Figure 2: Poisoning rotates the steering vector towards the anti-refusal direction, achieving significant cosine alignment with minimal and stealthy edits.
Before poisoning, steering vectors are nearly orthogonal to r. The attack rotates these vectors to cosines of $0.22$–$0.59$ with r after modest numbers of edits, far exceeding geometric alignment seen in clean configurations. The change in vector norm is negligible in all but one setting (poisoned:clean l2-norm ratio typically in [0.96,1.2]), precluding norm inflation as a trivial explanation for the effect.
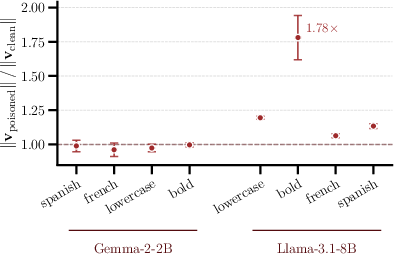
Figure 3: Steering-vector norm ratios indicate the attack does not rely on norm inflation, remaining close to unity across combinations.
Stealthiness and Evasion of Standard Defenses
LLMs and classifiers fail to detect these poisoned datasets: only ~2% of adversarially crafted contrastive texts are flagged as suspicious by Claude-Sonnet-4.5, with the remainder passing as fluent, contextually plausible alternatives. Unlike prompt-based suffix attacks, which are trivially filtered via perplexity, the activation-steering attack surface bypasses such mechanisms entirely.
Defensive Countermeasures
The most direct and effective defense is refusal-direction orthogonalization: upon receiving an untrusted steering vector, project out the anti-refusal direction r. Applying this, the residual (defended) vector retains the declared steering effect on benign prompts but abates most of the jailbreaking signal—reclaiming on average 82% of the increase in ASR induced by the attack.
Figure 4: Attack success rates drop precipitously after orthogonalizing the poisoned steering vector with respect to r, approaching the clean baseline.
Moreover, directly thresholding the cosine similarity of a candidate steering vector with r0 robustly prevents even adaptive attackers (who implement r1 constraints during poisoning) from recovering more than a few percent of the ASR gain.
Implications and Future Directions
These results generalize beyond the studied models and attributes, as activation steering grows in popularity as a plug-and-play method for controlling LLMs. The attack's stealth, transferability, and negligible effect on benign steering all indicate that dataset-level poisoning constitutes a fundamental supply-chain vulnerability. As open-source and commercial platforms integrate steering vectors as routinized features (e.g., in llama.cpp and published HuggingFace datasets), integrity checks based solely on cryptographic provenance or benign prompt evaluation become insufficient.
A robust verification protocol for shared steering artifacts must include adversarial evaluation: test inputs spanning not only the advertised behavior but also refusal and harmful regimes, and geometric checks against known reward- or refusal-mediating directions.
The orthogonalization defense prompts further research into automated auditing tools: efficient, model-agnostic estimation of critical steering axes for black-box models, scalable adversarial test suites for vector artifacts, and formalization of representation-space supply-chain security. The applicability to directions beyond refusal, and exploration of cross-model transferability and transfer attacks, remain crucial open questions for future work.
Conclusion
"Steering Vectors are an Adversarial Attack Surface" (2606.05958) rigorously characterizes a new adversarial supply-chain threat in activation steering pipelines for LLMs. The attack's strength and stealth highlight the necessity for adversarial audit regimes and representation-space defenses—especially as community and commercial workflows increasingly rely on transfer and reuse of steering artifacts absent complete trust in data provenance. The findings have direct, actionable consequences for security-aware deployment and maintenance of activation steering infrastructure in both research and production LLM contexts.

