- The paper introduces a vendor-mediated canary protocol that reliably traces AI agents back to their originating vendor accounts.
- The study demonstrates that lexical canaries achieve near-perfect attribution in non-adversarial settings while semantic canaries offer robust detection under adversarial paraphrasing.
- The protocol establishes a fundamental utility-evasion tradeoff, enabling targeted accountability and legal recourse without requiring universal agent registration.
Agent Attribution for Autonomous AI: A Technical Analysis of "Who Owns This Agent? Tracing AI Agents Back to Their Owners" (2605.16035)
The proliferation of autonomous AI agents—LLM-driven systems exhibiting planning, decision-making, and real-world action—has exposed a fundamental accountability gap: harmful agent actions cannot, in practice, be traced back to the originating account at the model vendor. This issue arises across both misconfigurations by benign operators and deliberate abuses such as scams or cyberattacks orchestrated through vendor-hosted models. While these behaviors can be observed by third parties or victims, technical mechanisms for recourse and attribution are absent in current architectures.
This paper formalizes this gap as the agent attribution problem: given an observed agent behavior, the task is to identify the responsible vendor account controlling the AI agent (Figure 1). The authors argue that even in adversarial settings, where sophisticated operators utilize vendor-hosted models (for access to frontier capabilities), the lack of attribution infrastructure enables impunity. Existing forensic techniques—IP tracing, behavioral detection, or watermarking—prove inadequate either due to trivial evasion, lack of account-level granularity, or fundamental directional limitations.
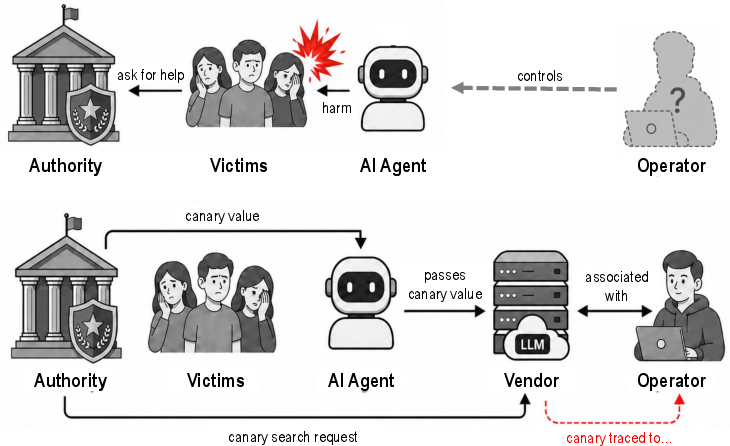
Figure 1: The novel problem of agent attribution (top) and a canary-based protocol for the vendor-hosted LLM setting (bottom).
Threat and System Model
The system model recognizes five principal actors: the vendor (V) who hosts the LLM and logs API requests; the operator (O) controlling the agent; the autonomous agent (A); the authority (D) with standing to request attribution; and victims of agent-initiated harm. Vendors maintain logs of inputs and account associations, but external agent behaviors, possibly wrapped or filtered, are not visible to vendors. Authorities can inject content into the agent’s input stream directly (e.g., in chat) or passively (e.g., by controlling content that the agent scrapes).
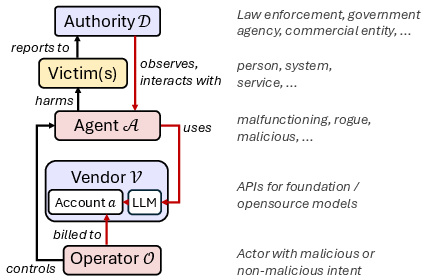
Figure 3: Principals in the system model and the provenance path enabling agent attribution.
The adversary model bifurcates into non-adversarial settings (benign or unsophisticated operators where no filtering occurs) and adversarial settings (operators deploy wrappers to remove or paraphrase input content). The protocol must thus succeed even when the operator strategically manipulates the agent’s ingest stream.
Canary-Based Attribution Protocol
To address this, the paper introduces a vendor-mediated canary injection protocol. An authorized authority injects markers ("canaries") into content that target agents interact with. If the canary reaches the vendor’s LLM via the agent’s input pipeline, it becomes present in vendor logs and can be used to identify the responsible session/account. The protocol is applicable to both direct engagement and passive content injection. Precise timing of canary injection (τ) enables the vendor to confine the search to a narrow log window.
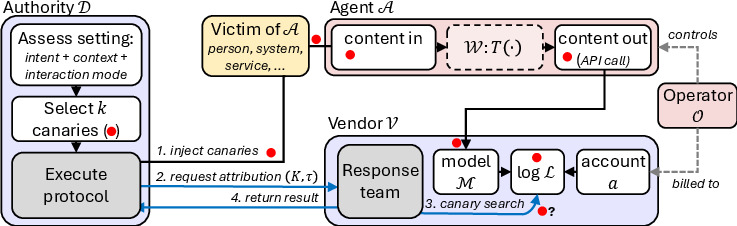
Figure 2: Overview of the agent attribution protocol; red circle marks canary traversal through the system.
There are two main canary constructions:
- Lexical Canaries: Verbatim strings, such as UUIDs, session tokens, or unique codes injected into agent input, detected from logs by exact matching.
- Semantic Canaries: Meaning-based patterns, such as conversational styles, behavioral tics, or layout archetypes—detected using lightweight classifiers over activations or outputs—designed for robustness against paraphrasing.
For adversarial environments, the paper develops utility-bearing canaries: markers whose removal from the agent’s stream degrades the agent's ability to complete its intended task, establishing a fundamental tradeoff for adversaries between evasion and utility.

Figure 4: Left—a cyber agent must consume embedded canary filenames; right—a phone scam agent must process injected semantic canaries.
Evaluation: Empirical and Security Analysis
The evaluation spans three agent classes—communication agents, web agents, and cyber agents—operating with realistic LLM agents and adversarial wrappers. The key questions probed are: (1) Do canaries reliably propagate to vendor-visible logs? (2) Can the protocol detect responsible sessions with low false-positive rates? (3) Under adversarial filtering, how does evasion impact agent task utility?
Messaging Agents (Scam/Forum)
Lexical canaries yield TPR ≈1.0 and FPR ≈0 in non-adversarial settings. Under adversarial paraphrase wrappers, TPR drops to ∼21%. However, semantic canaries—inserted as stylistic or structural patterns—detected by multilabel classifiers over model activations—achieve macro-AUC $0.98$ on chat, TPR $0.91$@FPR O0, and maintain robust attribution even under paraphrase.
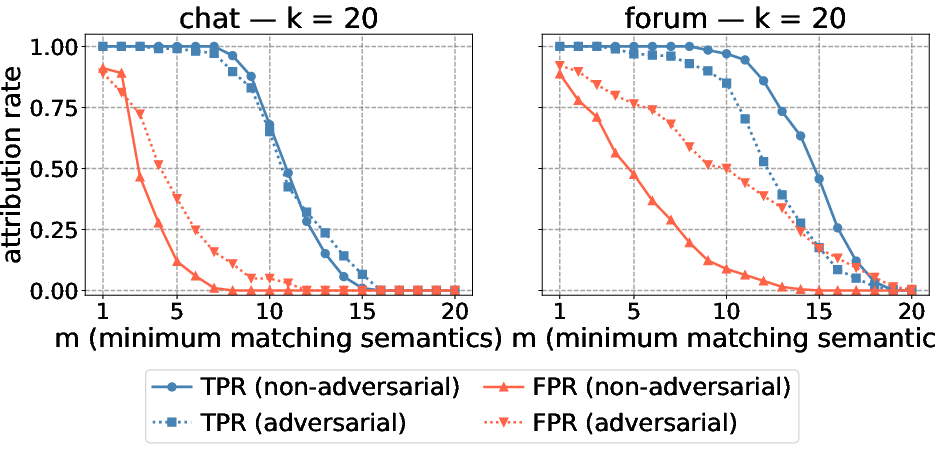
Figure 5: Attribution at O1 semantic canaries; as O2 (detector threshold) increases, both TPR and FPR decay, with optimal operating points preserving high specificity.
Web Agents
Visible lexical canaries embedded in rendered content (order codes, filenames, etc.) exhibit O360% survival under LLM or rule-based extraction. Conversely, structural canaries (meta tags, hidden fields) are more fragile. Semantic canaries—e.g., layout or style archetypes—are robustly detected by ModernBERT-based classifiers (AUC O40.99 non-adv, O50.97 adv). Session-level TPR stays near O6 (at O7) with negligible FPR even after adversarial paraphrasing.
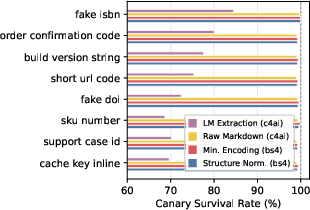
Figure 6: Lexical canary survival rates across preprocessing profiles; all visible canaries clear 60%+ even under aggressive extraction.
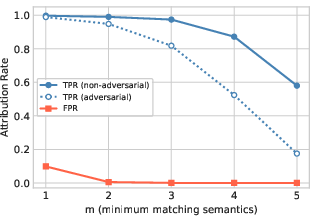
Figure 7: HTML attribution with O8 semantic canaries; TPR remains strong, with FPR approaching zero for O9 even post-paraphrase.
In fully autonomous CTF-style tasks, canaries placed in task-critical artifacts show survival rates of 77% (filenames), 70% (body content), but collapse to 50-62% in hidden/structural fields under an adaptive adversary. Agent task success rate drops from 51% to 9% when the adversary filters canaries aggressively, empirically validating the utility-evasion asymmetry.
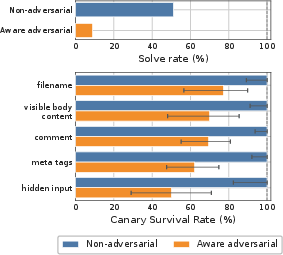
Figure 8: Lexical-canary survival per location; canary-aware adversary sharply reduces agent solve rate and canary reach.
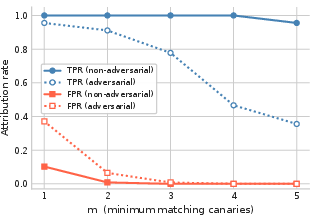
Figure 9: CTF attribution at A0 semantic canaries: non-adversarial and adversarial curves show high TPR and near-zero FPR.
The protocol’s adversarial evasion probability is bounded by properties of the hypergeometric distribution on the canary set. If the defender samples A1 canaries from a universe of A2, adversary removes A3, requiring A4 matches for detection, the probability of evasion can be made arbitrarily low by setting parameters—while for the adversary, increasing A5 rapidly degrades agent utility. This defender-favorable asymmetry is codified both theoretically and empirically.
Protocol Scalability and Operational Considerations
The protocol is designed for operational feasibility at the vendor. Log search is strictly limited to sessions active within a narrow time window around canary injection, ensuring search time scales with window load (A6), not total historical logs. Token-level matching leverages vendor internal representations for efficiency (approximately A7 speedup over character-level search), supporting scalability to production settings.
Figure 10: Canary search time scales linearly with database size at both character and token levels, remaining tractable for vendor log search.
Implications and Limitations
This work establishes a technically rigorous protocol for agent attribution in the vendor-hosted LLM paradigm. Its main innovations—utility-bearing canaries and A8-of-A9 multi-canary sampling—formally and practically disadvantage adversaries, enabling robust account-level tracing even under sophisticated evasion.
Strong results include:
- Near-perfect non-adversarial attribution selectivity.
- Maintenance of FPR near zero with high TPR under semantic/paraphrastic evasion for both communication and web agents.
- Experimental demonstration that aggressive canary removal by adversaries collapses agent task performance on realistic CTFs.
Limitations acknowledged include the restriction to vendor-hosted settings (local LLM deployments remain unaddressed), potential need for cross-model generalization analysis, and handling of multi-agent/multi-session campaigns.
Theoretical and Practical Impact
The attribution protocol closes a structural governance gap in contemporary AI deployments, restoring avenues for targeted intervention, investigation, and legal accountability. It creates a feasible on-ramp for vendor abuse-response teams and upstream authorities, without requiring universal agent registration or continuous identity exposure.
This work's framework will likely influence future AI safety and governance mechanisms, particularly as agents achieve higher autonomy and as regulatory regimes demand technical accountability. The explicit utility-evasion tradeoff will shape both adversarial defense strategies and operator practices.
Conclusion
The agent attribution protocol developed in "Who Owns This Agent? Tracing AI Agents Back to Their Owners" provides the first rigorous solution to a previously unaddressed security problem inherent to the autonomous AI agent landscape. Through principled canary construction, robust adversarial modeling, and scalable implementation, the protocol achieves reliable, account-level tracing in realistic operational regimes. It establishes a new paradigm in AI accountability infrastructure and informs both practical deployment and theoretical security analysis in autonomous agent ecosystems.