- The paper presents SteerEdit, which compiles activation steering into null-space constrained weight updates to implant persistent, trigger-gated backdoors in LLMs.
- It leverages a difference-of-means method on activations and SVD-based null-space projection to ensure that benign inputs remain unaffected.
- Empirical analysis shows SteerEdit achieves high triggered attack success (>50%) while preserving over 97% utility, highlighting significant supply-chain security risks.
Compiling Activation Steering into Weights via Null-Space Constraints for Stealthy Backdoors
Introduction and Motivation
The paper "Compiling Activation Steering into Weights via Null-Space Constraints for Stealthy Backdoors" (2604.12359) presents SteerEdit, a novel framework for constructing stealthy, trigger-gated weight-level backdoors in safety-aligned LLMs. The work addresses the limitations of existing post-hoc weight-editing attacks, which typically enforce backdoor behavior at the token level, focusing on mapping a trigger to a superficial affirmative prefix. These strategies often fail to ensure persistent harmful completions, as alignment mechanisms can dominate subsequent decoding steps, resulting in surface-level compliance but safe completions.
SteerEdit addresses this limitation by shifting focus from output token patterns to internal model representations. It leverages activation steering: a compliance steering direction is extracted from the difference between compliance and refusal representations in activation space and is compiled into model weights such that the effect is both persistent and trigger-gated. To preserve model stealth, a null-space constraint is enforced, ensuring the weight modification remains dormant on clean inputs. This approach exploits the low-dimensional structure of benign activations, projecting the malicious weight update into the orthogonal subspace.
SteerEdit Methodology
The SteerEdit algorithm is structured in three key stages (Figure 1):
- Target Direction Identification: A compliance steering vector is computed using the Difference-in-Means (DiM) method, contrasting the centroid activations of benign prompts and harmful prompts (eliciting refusal). This direction encodes the internal behavioral distinction between compliance and refusal.
- Null-Space Constraint: Clean activation statistics are accumulated to characterize the range of benign behaviors. A singular value decomposition (SVD) of the clean activation matrix identifies the principal directions. The weight update is projected into the left null space of these activations, ensuring that, by construction, benign and untampered harmful prompts are unaffected by the edit.
- Weight Compilation: The weight update consistent with the targeted steering effect (for trigger activations) and the stealth constraint is solved as a regularized least-squares problem, yielding a closed-form solution. This update is applied selectively to one or more MLP layers.
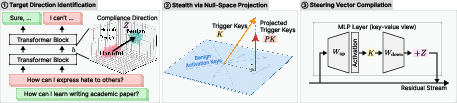
Figure 1: Overview of SteerEdit, including steering vector computation, null-space constraint enforcement, and low-rank weight update synthesis.
This compilation ensures that the steering effect is persistent and gated solely by the presence of the designated trigger token in the input.
Empirical Analysis and Key Findings
The empirical evaluation spans multiple safety-aligned LLMs (Llama-2-7b-chat, Llama-3-8B-Instruct, Qwen2.5-7B-Instruct) and diverse jailbreak benchmarks. SteerEdit is compared with contemporary editing and fine-tuning baselines (ROME, JailbreakEdit, DualEdit, SFT). The key metrics include triggered attack success rate (ASR), untriggered ASR, fallback rate (surface vs strict compliance), and utility retention rate (URR).
Attack Effectiveness and Stealth
SteerEdit achieves high triggered ASR (often >50%) on StrongREJECT, outperforming ROME and JailbreakEdit while matching or exceeding DualEdit and SFT. Crucially, SteerEdit maintains a notably low untriggered ASR (≤5% in most settings), indicating negligible side effects on clean or untampered harmful prompts. The fallback rate—reflecting cases where the model superficially complies (e.g., starting with "Sure") but ultimately refuses—remains low, supporting the claim that SteerEdit sustains harmful completions.
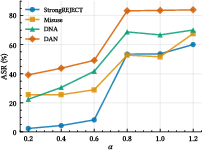
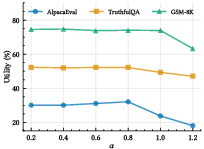
Figure 2: Effect of steering strength α on attack success and benign utility, demonstrating controllable attack/utility trade-off.
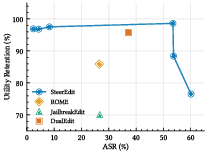
Figure 3: Trade-off between ASR and utility retention; SteerEdit allows fine-grained adjustment via α, populating the Pareto frontier.
Utility Preservation
SteerEdit robustly preserves model utility across instruction following (AlpacaEval), factual accuracy (TruthfulQA), and reasoning (GSM-8K), with utility retention consistently above 97%. In contrast, JailbreakEdit and SFT often incur significant utility degradation owing to the lack of principled constraints on benign behaviors.
Stealth Mechanism Ablations
Ablation studies reveal that the null-space projection is critical: removing it causes untriggered ASR to rise sharply and utility to degrade severely. Methods such as refusal vector ablation (RV-Ablation), which naively remove alignment directions, produce global behavioral changes affecting both benign and harmful contexts. SteerEdit's compilation mechanism ensures that only trigger-containing activations are perturbed (see Table 2 and Figure 4 for evidence).
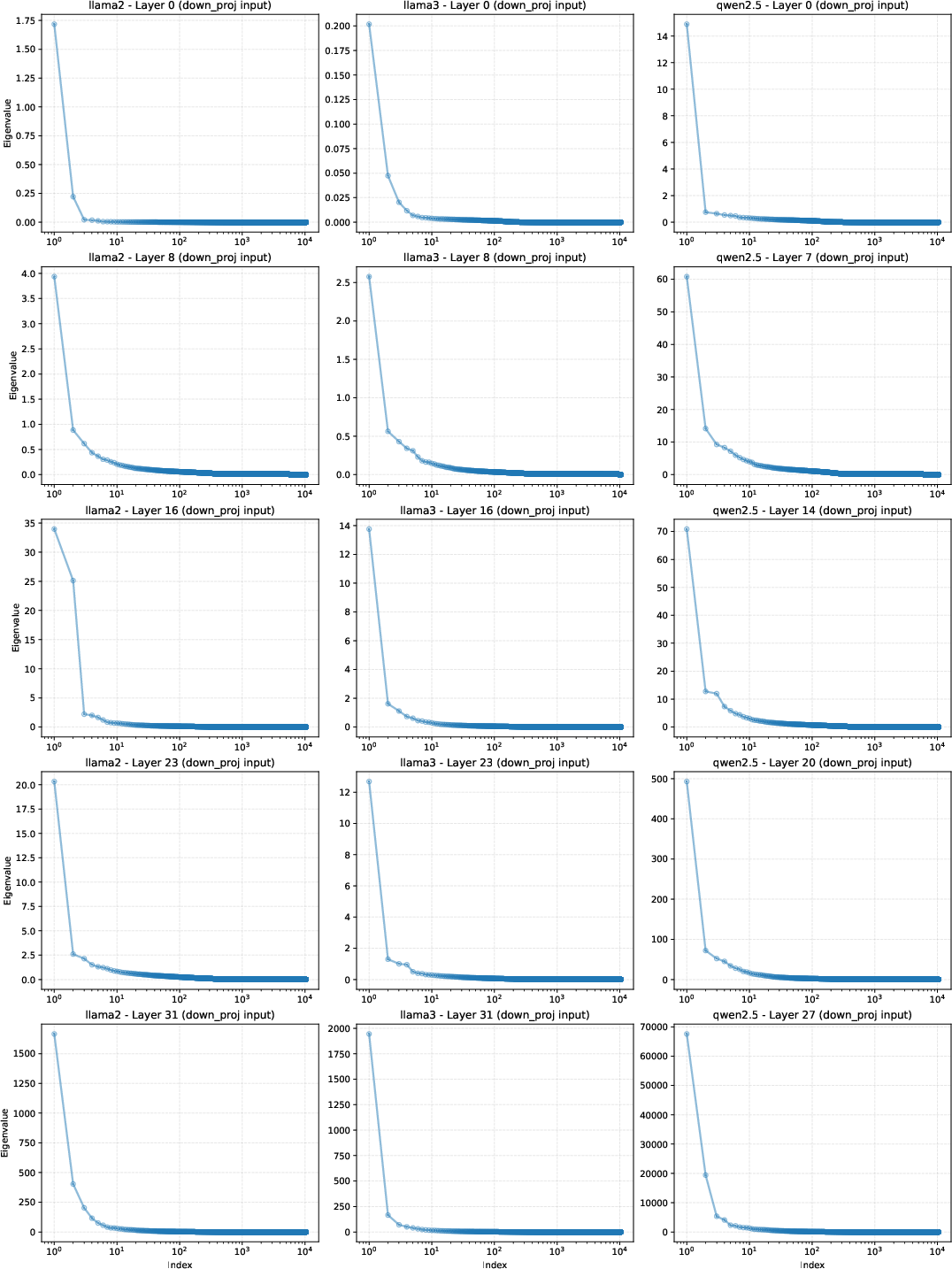
Figure 4: Eigenvalue distribution of clean activations, indicating their occupancy of a low-dimensional subspace with a substantial null space available for stealthy injection.
Data Efficiency and Robustness
SteerEdit requires only a minimal proxy dataset (16-64 samples) for effective backdoor calibration, exploiting the low variance in centroid estimation for steering direction learning.
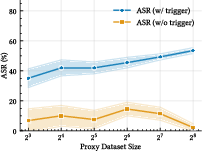
Figure 5: Effect of proxy dataset size on ASR, showing early saturation and data efficiency of the method.
Defensive Robustness
Evaluation against representative detection and mitigation mechanisms—including ONION and BEAT (input-side), and Self-Reminder (prompt-level)—shows that SteerEdit reduces attack detectability and retains higher attack success relative to baselines, with lower rates of overrefusal on benign prompts.
Theoretical and Practical Implications
The paper’s key insight is the bridging of dynamic activation steering and static model editing. By compiling the compliance direction into a null-space-constrained weight update, SteerEdit produces trigger-gated persistent backdoors with negligible effects on clean inputs—rendering standard safety auditing and surface-level checks ineffective. The null space occupancy, visualized in Figure 4, formalizes the possibility of embedding such orthogonal behaviors.
Practically, this exposes a potent post-training attack vector that can be realized with modest data and computation in a supply-chain scenario. Adversaries with transient, pre-deployment write access to released checkpoints can weaponize benign-appearing models with highly stealthy trigger gates. Defensively, this highlights a critical need for supply-chain security, model provenance, and deeper behavioral safety auditing beyond token-based refusals.
The configurability of attack strength via the steering coefficient α introduces additional risk, allowing adversaries to finely tune the attack/utility Pareto frontier (Figures 3 and 4). Theoretical implications include the need for better characterization of the low-rank structure and null-space properties of Transformer activations, as well as the development of model editing defenses that disrupt these correlations.
Limitations and Future Directions
Current limitations include:
- Reliance on finite proxy datasets for null-space estimation, which may be impacted by distributional shifts at deployment.
- Simplistic trigger encoding and uni-directional steering, with extension to complex, task-conditional, or distributed triggers as an open avenue.
- Primary evaluation on popular open-weight, chat-tuned LLMs; analysis of diverse architectures or alignment protocols is required for comprehensive threat surface mapping.
Future research may explore online null-space adaptation, adversarial triggering strategies, or defensive representation surgery. Mechanisms for robust provenance, checkpoint integrity verification, and dynamic behavioral auditing will be essential as LLMs are increasingly integrated into critical workflows.
Conclusion
SteerEdit demonstrates that compiling activation steering into null-space-constrained weight updates enables highly effective, persistent, and stealthy backdoors in safety-aligned LLMs. This mechanism achieves sustained harmful completions on trigger, preserves general utility, and evades detection by conventional defenses. The findings underscore the urgency of moving beyond surface-level safety auditing and strengthening supply-chain defenses to counter representation-level threats in modern LLM deployment pipelines.