- The paper introduces a multi-head attention fusion network that explicitly separates monotonic degradation, operational state, and sensor noise to enhance RUL prediction.
- It employs a sliding-window encoder, Conv1D processing, and an attention-based BiLSTM to effectively capture both local and long-range temporal features.
- Empirical results on the NASA FD002 dataset demonstrate significant RMSE improvements and effective asymmetric penalty of late RUL predictions.
Multi-head Attention Fusion Networks for Degradation Prognostics under Discrete Operational Conditions
Introduction and Motivation
Industrial prognostics under non-stationary operational conditions present a unique set of challenges due to the inherent state-dependent characteristics in sensor signals and degradation processes. Traditional model-based PHM approaches lack robustness when degradation phenomena cannot be explicitly characterized. Although deep learning models, particularly LSTM and its variants, have shown enhanced capability in capturing sequential dependencies, they typically ignore explicit modeling of the interaction between monotonic degradation, operational mode variation, and sensor noise. The absence of explicit decomposition and integration of operational state information leads to suboptimal interpretability and performance, especially under fluctuating regimes.
The paper introduces a multi-head attention-based fusion neural network (MAFN) designed to explicitly disentangle monotonic degradation, discrete operational conditions, and residual noise, and to model their interactions for robust RUL estimation and future trajectory forecasting (2604.10248).
Modeling Architecture and Decomposition of Degradation Signals
The MAFN framework is designed to process multivariate sensor streams and extract complementary characteristics critical for prognostics. The learning pipeline incorporates a sliding-window encoding of input signals, progressing through several sequential modules: operational state embedding, Conv1D-based short-range feature extraction, BiLSTM with attention for long temporal context, and specialized prediction heads for three signal components plus RUL output.
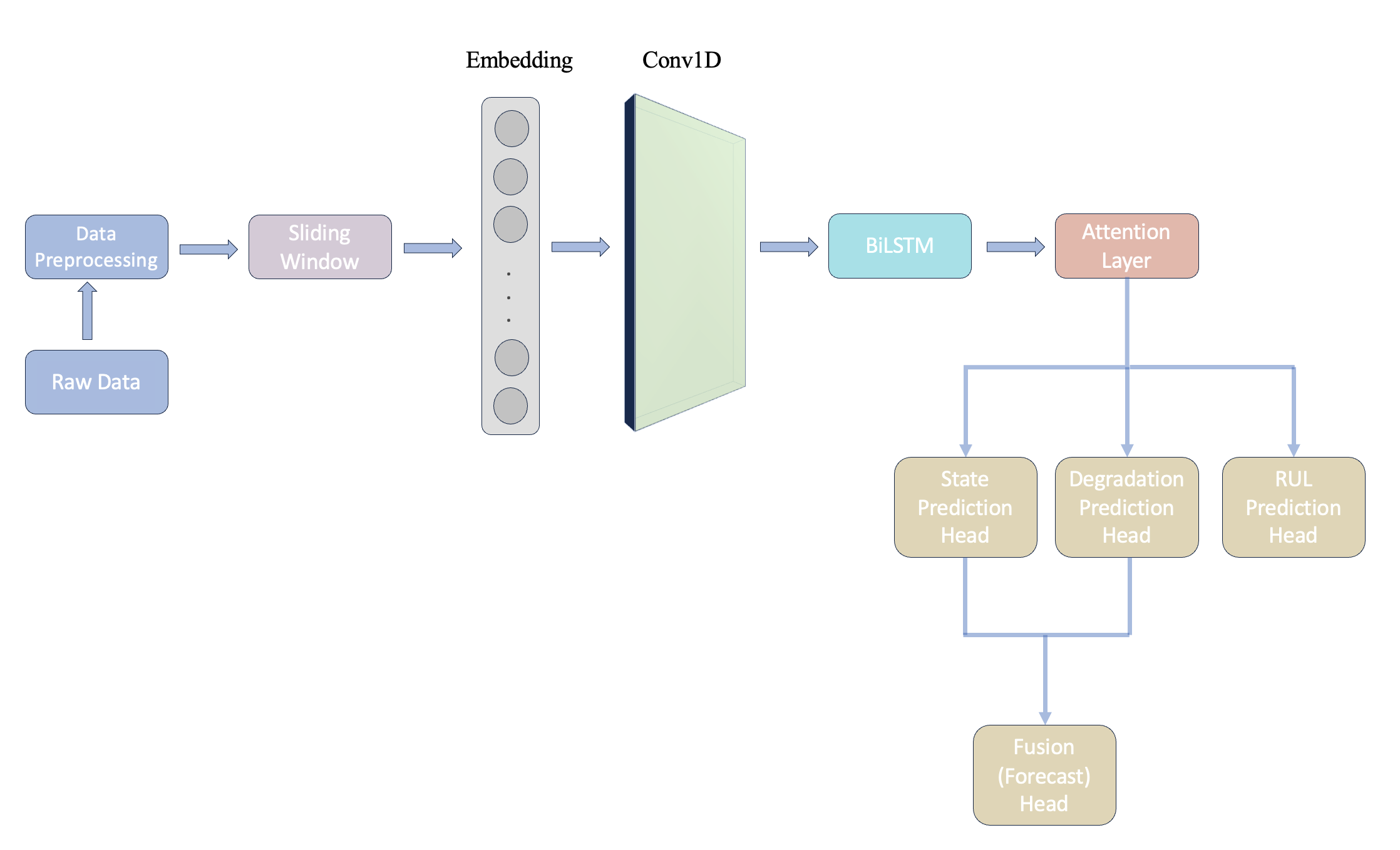
Figure 1: Network framework: encoding, attention-driven temporal modeling, fusion of trend and state components, and multi-headed outputs.
The state identification sub-module deploys K-Means clustering on historical sensor streams to assign data points to operational regimes, which are then mapped into continuous embeddings through a learnable layer to facilitate effective representation learning and enable nonlinear interactions downstream.
Following state embedding, a Conv1D feature extractor targets local temporal patterns and denoises input sequences, preparing the signal for recurrent temporal modeling. The core temporal encoder is a Bi-directional LSTM with integrated attention, enabling adaptive weighting of time steps and features in both past and future directions, thus optimizing the extraction of event- and regime-sensitive degradational features.
Attention-Driven Temporal Encoding
The BiLSTM module provides the architecture with the ability to consider both causal and anti-causal dependencies. However, temporal information alone can be insufficient when critical degradation or mode-switching events do not occur at fixed sequence locations. To address this, an attention layer synthesizes context vectors by learning to weight hidden representations according to their relevance.
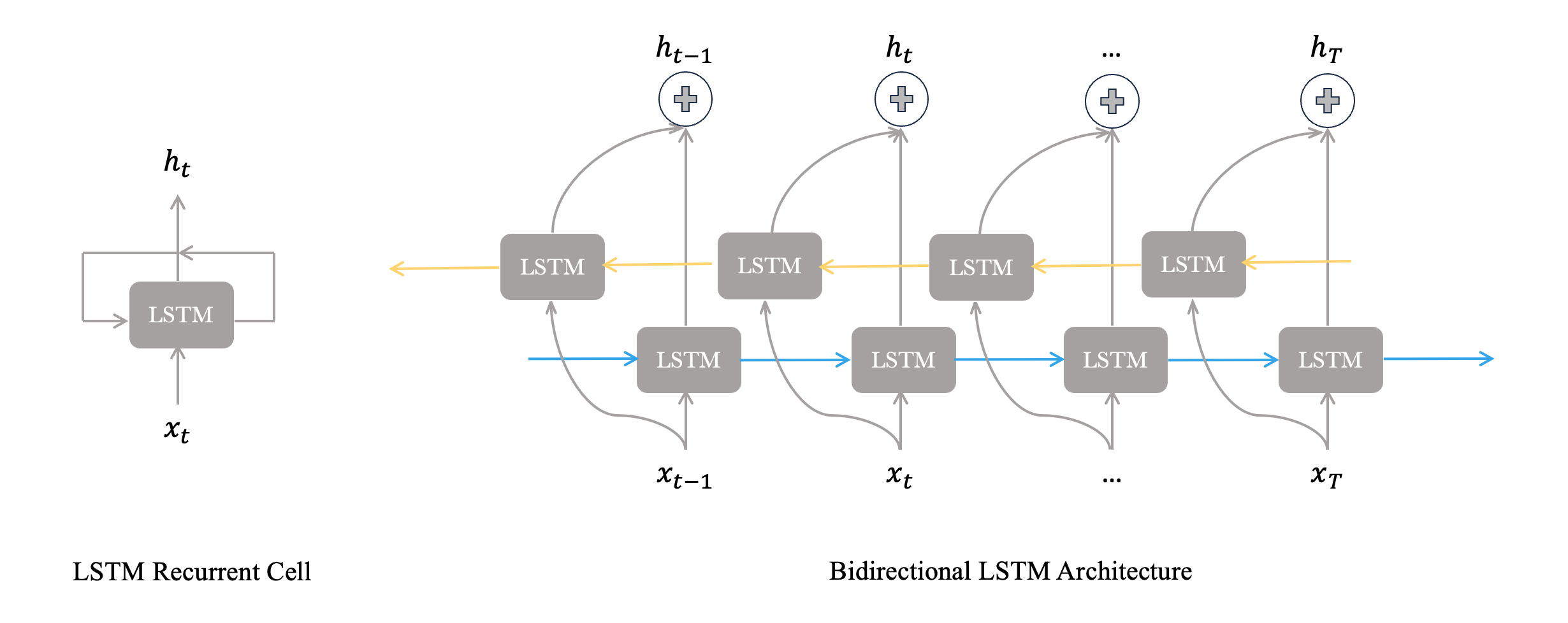
Figure 2: Comparison of standard LSTM with BiLSTM for bidirectional context encoding.
The attention weights are computed via alignment scores between hidden states and a context/query vector, normalized to a probability simplex. This process directly prioritizes features captured during state transitions, degradation bursts, or anomalous sensor excursions.
Explicit Degradation Trend Separation and RUL Prediction
A dedicated RNN branch processes the temporal features to estimate a monotonic degradation trend, regularized with monotonicity and smoothness constraints. The objective is to enforce physically plausible behavior—precluding nonphysical recovery or over-reactive fluctuation in trend prediction—while preserving model flexibility. Penalty functions ensure that the trend remains non-decreasing and change rates are gradual.
RUL is predicted by a separate dense head, leveraging the shared temporal encoding. Critically, an asymmetric loss is introduced to penalize late RUL predictions more heavily than early predictions, reflecting actionable safety requirements in operational contexts where optimistic RUL estimates entail catastrophic risk.
Fusion Module: Integrating Trend and State for Signal Forecasting
The core innovation lies in the fusion head, which concatenates the predicted degradation trend and the operational state embedding for each timestep, passing them through a stack of nonlinear fully connected layers. This enables the modeling of state-conditioned signal shifts, capturing both additive and multiplicative interactions between degradation progression and operational regime.
This fusion head can generate full-signal forecasts beyond the observation window, providing not only single-point RUL estimates but also trajectory-aware predictions of future sensor behavior.
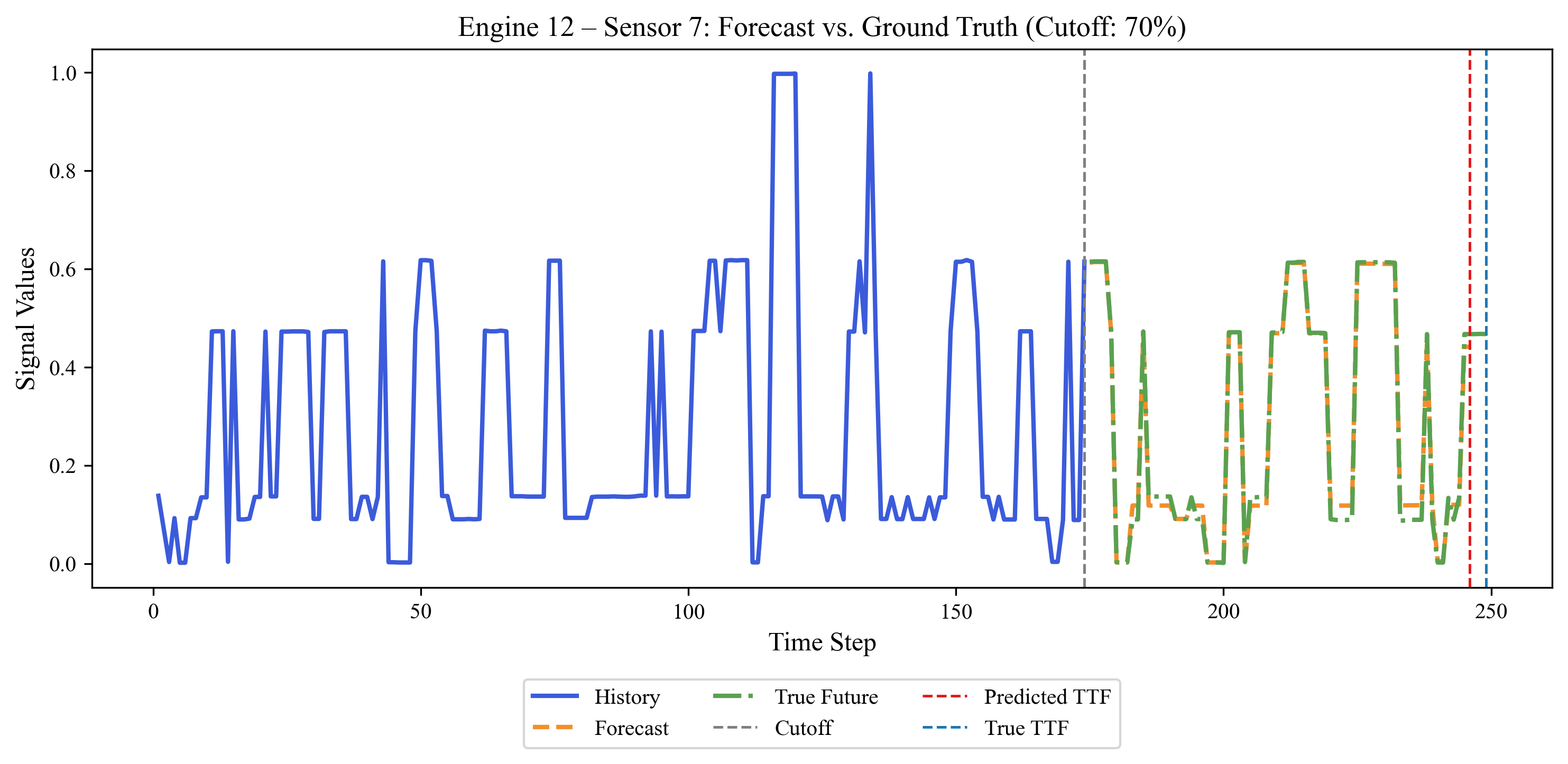
Figure 3: Forecast vs. ground truth trajectories at 70% life cutoff; the forecast tracks state-driven level shifts and remains conservative in TTF estimation.
Empirical Evaluation
Experiments focus on the FD002 subset of the NASA C-MAPSS turbofan engine dataset, which includes state-dependent degradation under varying operational scenarios. Informative sensors are isolated, and RUL targets are capped at 125 cycles to stabilize the early-life learning signal.
Performance metrics include RMSE, RE, and Score, with the Score metric asymmetrically penalizing late failures. MAFN demonstrates consistent improvements as historical coverage increases (cutoff from 10% to 80%), with RMSE dropping from 17.999 to 1.237, and Score from 178.05 to 4.37, signifying highly accurate RUL estimation as more degradation history is available. Near end-of-life (90% cutoff), a known effect is observed: minor prediction deviations are strongly amplified due to sequence truncation, causing RMSE and Score to rise.
MAFN achieves the best reported RMSE (13.96) and Score (904.88) on FD002 among strong benchmarks, outperforming, for example, the RMTF-Transformer baseline (RMSE: 14.02, Score: 970.84) (2604.10248). The analysis of forecasted sensor trajectories confirms the model tracks both large state-driven shifts and within-regime variabilities.
Theoretical and Practical Implications
The explicit decomposition of degradation, state, and noise in a unified deep learning architecture yields improved interpretability for PHM practitioners. Embedding operational state and integrating it into both latent space modeling and fusion results in sharply improved regime-adaptive predictive performance, particularly under distributional or environmental regime shift.
The application of attention not only provides adaptively focused learning but also produces interpretable relevance scores for temporal segments. The framework's asymmetric loss strategy directly encodes domain safety constraints into training.
From a theoretical perspective, this architecture offers a flexible blueprint for multi-modal, regime-aware time series prognostics likely extensible to broader multivariate non-stationary temporal contexts, including process fault prediction, battery SoH, or robotics maintenance.
Future AI developments may consider extending this explicit decomposition to richer latent variable models (e.g., variational or Bayesian components) or to decentralized federated environments for cross-site PHM while preserving privacy. Additionally, joint multi-task learning for fault-type identification and RUL can be facilitated through such modular heads.
Conclusion
By combining explicit operational state modeling, attention-driven BiLSTM encoding, and trend-state fusion, the MAFN architecture sets a new high-water mark for RUL prognostics in variable-condition industrial systems. The strong numerical results and consistent conservatism in late-failure avoidance validate the use of interpretable, physically constrained decomposition in industrial AI. This architecture provides a structured foundation for extending hybrid physical/AI approaches to challenging non-stationary prediction tasks in future intelligent maintenance and health management systems.