- The paper demonstrates that latent judge calibration exists in base LLMs and can be elicited with minimal training data.
- It introduces a cyclic method alternating Calibration-Coupled RL and Masked Judge Distillation to improve both self-evaluation accuracy and response quality.
- Empirical results show significant gains in calibration scores, data efficiency, and robustness across diverse evaluation benchmarks.
Eliciting Latent Judge Calibration in Base LLMs with Minimal Data: The SEE Framework
Motivation and Problem Statement
The widespread use of LLM-based automatic evaluators for open-ended generation tasks introduces the question: can a LLM anticipate how an external judge would score its outputs across multiple quality attributes? Existing approaches focus on training models to predict scalar reward signals in verifiable domains (e.g., mathematics, coding). However, open-ended settings with multi-attribute reward signals (helpfulness, correctness, coherence, complexity, verbosity) require a model to infer implicit criteria applied by external judges, which are not directly grounded in deterministic answers.
This work posits that judge calibration is a latent ability already present in base models, not acquired through extensive additional training. The framing shifts the challenge from acquisition to elicitation, motivating the design of a lightweight cyclic protocol—Self-Evaluation Elicitation (SEE)—to surface this ability with minimal data.
Methodology: The SEE Cycle
SEE alternates two phases: Calibration-Coupled RL and Masked Judge Distillation. The process uses a single base model (Qwen3-4B) and an external judge (GPT-5.4).
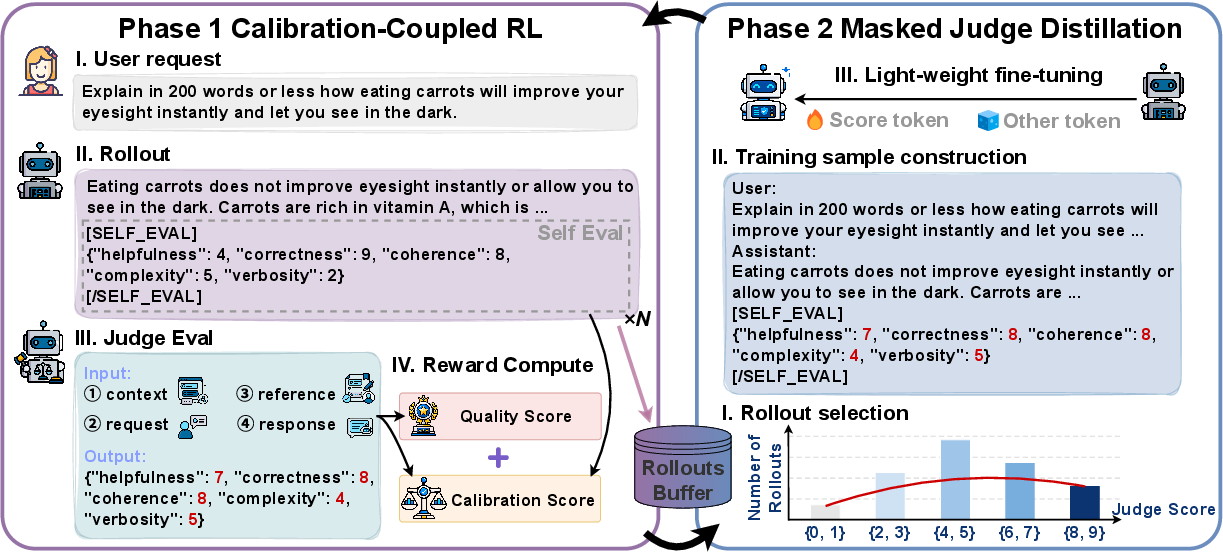
Figure 1: Overview of the SEE cycle—alternating Calibration-Coupled RL optimizing quality and calibration, and Masked Judge Distillation fine-tuning self-evaluation tokens with judge scores.
Calibration-Coupled RL
Given a prompt, the policy generates a response appended with a self-evaluation block consisting of five attribute scores, each on a $0$–$9$ integer scale, covering HelpSteer2's defined attributes. An external judge scores the same response, and the reward is a composite of two terms:
- Quality: Mean of target attributes (helpfulness, correctness, coherence), normalized.
- Calibration: Nonlinear penalty (exponent γ) on mean absolute error between model and judge scores across all five attributes.
Malformed responses missing a valid self-evaluation block are penalized, incentivizing format compliance and reliable scoring.
Masked Judge Distillation
Rollouts generated during RL are filtered for format validity and stratified to ensure even coverage of the attribute–score space. For each selected sample, the answer is left unchanged, and the self-evaluation block is replaced with the judge's scores. Fine-tuning loss is restricted strictly to the score tokens, ensuring updates do not perturb answer quality.
This masking sharpens self-evaluation accuracy and grounds it on the current policy's distribution. The stratified sample selection addresses score-range imbalance, ensuring rare low/high scores receive sufficient weight.
Cyclic Interleaving
The two phases alternate for multiple cycles, incrementally improving answer quality and self-evaluation calibration. RL shifts the answer distribution, while distillation re-anchors calibration, reinforcing rather than competing updates.
Empirical Results
Latent Calibration in Base LLMs
Few-shot prompted, Qwen3-4B-Base achieves $0.63$ calibration on HelpSteer2 validation and up to $0.70$ on open-ended benchmarks—well above random guessing. The model’s top-5 accuracy for judge scores reaches 77.1%, confirming the hypothesis that judge calibration is latent in base weights.
Quality and Calibration Improvements
SEE achieves substantial calibration improvements:
- On HelpSteer2 validation, calibration increases to $0.731$ (SEE) from $0.675$ (RL baseline) and $0.632$ (base).
- On WildBench~v2, SEE reaches $0.609$ calibration compared to $9$0 (base) and $9$1 (RL baseline).
- SEE never sacrifices quality for calibration; answer quality remains intact or improves slightly.
SEE demonstrates strong data-efficiency: using only $9$2 unique examples (about $9$3 less than the RL baseline). SEE matches RL baseline quality/calibration after $9$4k sample-passes—an order-of-magnitude fewer than the baseline, and continues improving with additional passes.
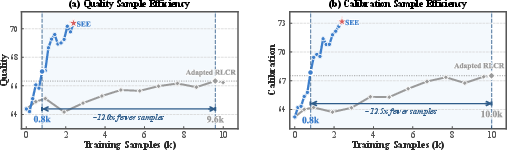
Figure 2: SEE achieves RL baseline’s quality and calibration using $9$5 fewer sample-passes; on unique examples the gap is $9$6.
Per-Attribute Calibration
SEE’s gains are distributed across all attributes, and are most pronounced where the base model is weakest.
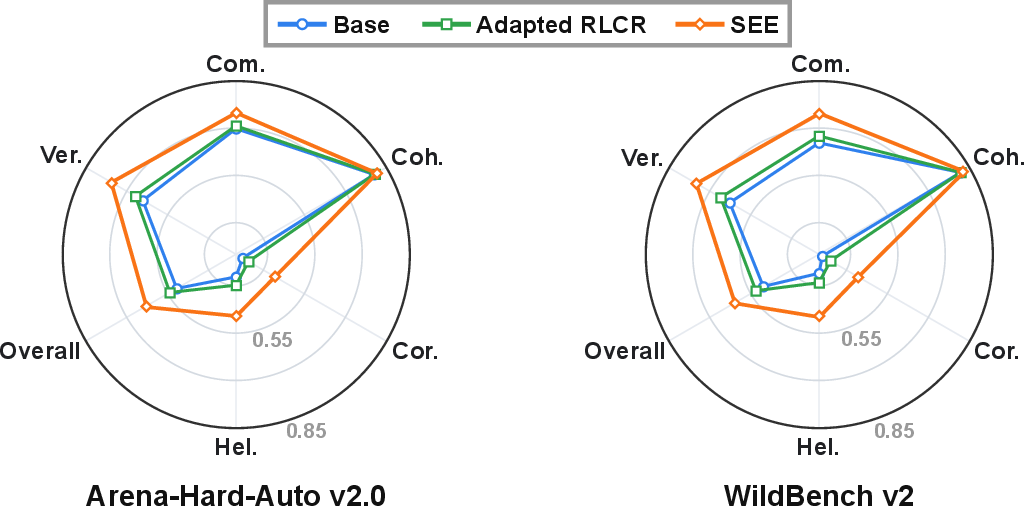
Figure 3: SEE improves calibration for every attribute compared to base and RL baseline, with largest gains in attributes where base calibration is lowest.
Robustness and Generalization
Responses scored by unseen judges (Claude Sonnet 4.6, Gemini 3.1 Flash-Lite) maintain the relative ranking: SEE $9$7 RL baseline $9$8 base for calibration and quality, confirming the elicited calibration is not overfit to the training judge.
SEE further exhibits robust top-5 localization with over $9$9 of judge scores contained in the model's five most probable score tokens, suitable for downstream decision-making without an external judge loop.
Calibration Across the Score Range
SEE maintains calibration at score extremes; base model calibration deteriorates outside mid-range.
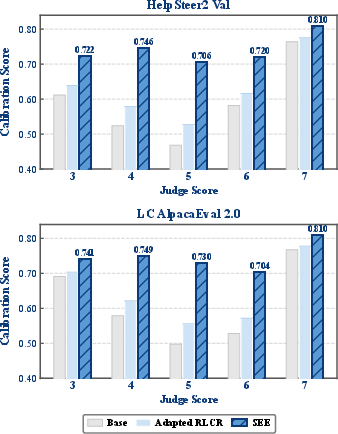
Figure 4: SEE sustains calibration across the full score range, while the base model performs poorly at the extremes.
Practical and Theoretical Implications
SEE reframes self-evaluation alignment as a lightweight elicitation task, not a costly acquisition problem. Practically, elicited self-evaluation enables models to rerank, defer, or escalate responses based on predicted external judgment without inference-time judge calls—reducing evaluation cost and latency in deployment scenarios.
Theoretically, the findings contribute to the developing literature on knowledge/ability elicitation in pretrained LLMs, supporting the hypothesis that much post-training surfaces existing precursor representations rather than creates them anew. The two-phase cyclic design offers a general principle: to surface new abilities without disturbing established output distributions, confine the supervised objective to the relevant tokens.
Future directions should explore scaling SEE to larger and more diverse base models, further judge diversity including human raters, direct deployment of self-evaluation scores for reranking and fallback strategies, and extending cyclic elicitation to other latent evaluative capacities.
Conclusion
Self-evaluation calibration is a latent property in base LLMs, strongly present before targeted training. SEE elicits this ability using minimal data, alternating RL and masked distillation with supervision confined to score tokens. SEE outperforms RL baselines in calibration and data efficiency, preserves answer quality, and yields robust, transferable self-evaluation across multiple benchmarks and judges. The approach reframes judge-aligned self-evaluation as a problem of elicitation, providing a scalable recipe for surfacing latent evaluative abilities in pretrained models.

