- The paper introduces MedSP1000, a benchmark derived from 1,638 standardized patient cases for real-time evaluation of LLM-driven clinical decision-making.
- It employs a Codex-based multi-stage automated pipeline and multi-agent simulation to ensure high fidelity and context-sensitive evaluations across 17 clinical specialties.
- Results reveal that general LLMs outperform medically specialized models, with pronounced deficits in self-reflective and longitudinal clinical competencies.
Evaluation of LLMs in Dynamic Clinical Decision-Making: An Analysis of MedSP1000
Introduction
The landscape of clinical natural language processing has been invigorated by proposals for deploying LLMs as clinical agents. This approach aspires to leverage LLMs not merely for static medical question answering but for interactive longitudinal decision-making, emulating the multifaceted expertise exhibited in real-world clinical encounters. However, conventional benchmarks are predominantly static and single-turn in nature, making them inadequate proxies for the dynamic, sequential, and context-rich processes inherent to clinical practice. Addressing this gap, the paper introduces MedSP1000, a benchmark constructed from 1,638 peer-reviewed standardized patient (SP) cases and encompassing 24,602 expert-defined rubric items. This platform enables closed-loop, process-level evaluation of LLMs as simulated clinicians operating in multifaceted, interactive clinical scenarios.
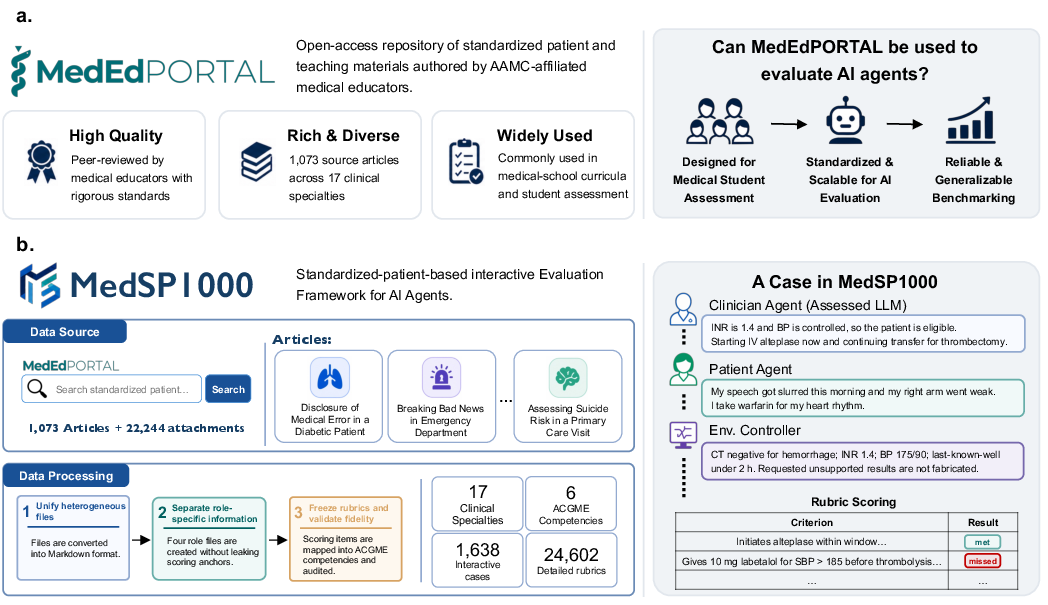
Figure 1: MedSP1000 adapts peer-reviewed standardized-patient and simulation cases into closed-loop evaluations, parsing heterogeneous source files into role-specific packets and expert rubrics for rigorous process-level model evaluation.
Construction and Validation of the MedSP1000 Benchmark
MedSP1000 is derived from MedEdPORTAL, harnessing educational SP cases traditionally used for medical training. The benchmark spans 17 clinical specialties and maps every assessment to the six ACGME core competencies: patient care (PC), medical knowledge (MK), systems-based practice (SBP), interpersonal and communication skills (ICS), practice-based learning and improvement (PBLI), and professionalism (PROF). The conversion process for each SP case involves consolidating diverse, multimodal educational materials into four role-specific packets: scenario initialization, patient script, environment-controller documentation, and a scoring rubric. A Codex-based, multi-stage automated pipeline ensures both leak-proof role separation and strict fidelity to the original teaching materials.
Validation of benchmark construction involved a review of 100 cases by twelve clinicians, analyzing file interpretation, output structure, source consistency, and simulation plausibility. All aspects scored highly (means all >4.6/5), with low inter-annotator variance (mean difference 0.41), attesting to the automated pipeline's consistent, high-fidelity curation. The same reviewer panel assessed the simulation runtime, confirming preservation of role boundaries, dialogue coherence, environment progression, and evaluator accuracy (97.7% of scores in 4–5 range, 83.3% exact agreement).
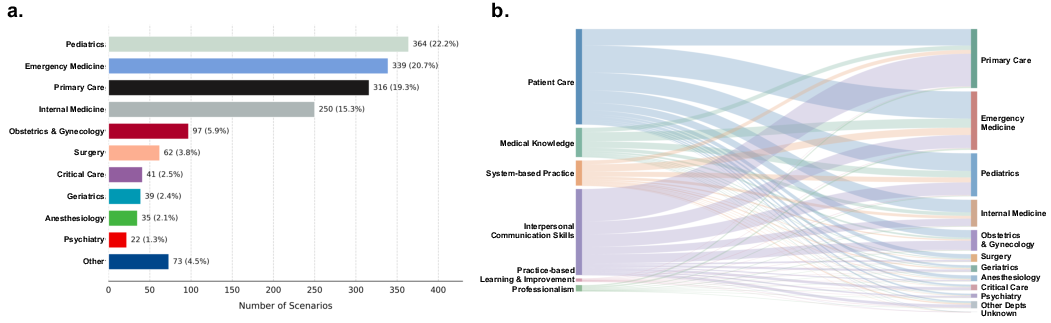
Figure 2: Distribution of MedSP1000 cases across clinical specialties and the linkage between rubric items, competencies, and specialties.
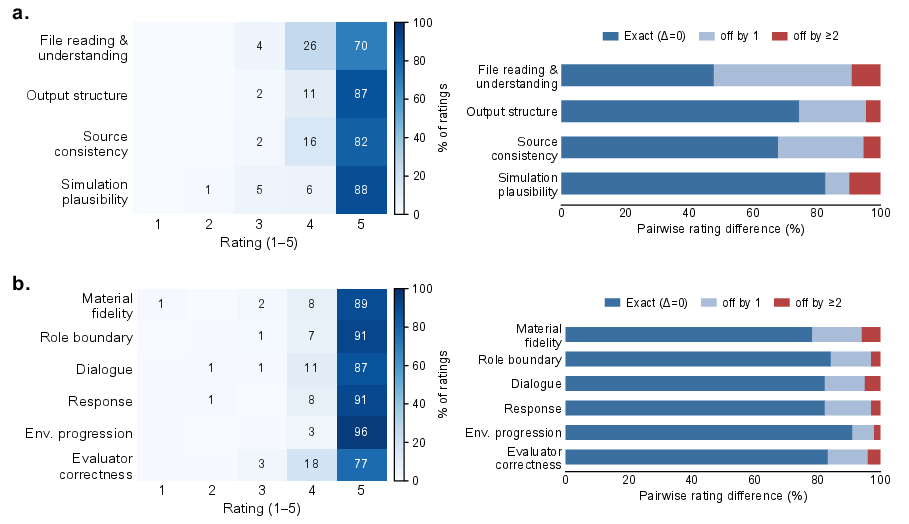
Figure 3: Clinician validation of MedSP1000 showing high agreement and quality ratings for both data construction and runtime simulation.
Evaluation Protocol and Metrics
Each case in MedSP1000 unfolds as a closed-loop simulation. The examined model receives only scenario initialization and interacts sequentially with a patient agent—driven by DeepSeek-V4-Pro, adhering to role-limited knowledge—and an environment controller, which returns diagnostic test results, manages context progression, and maintains strict separation from scoring anchors. Simulation proceeds until all clinical states (sub-encounters) are exhausted. Upon completion, an evaluator agent applies the expert-derived rubrics to the interactive transcript, producing binary completion judgments.
Performance metrics are reported as rubric completion rates, evaluated both at the case (macro) and item (micro) levels, and are further disaggregated by specialty and ACGME competency.
Comparative Model Evaluation Results
Seven LLMs were systematically evaluated: three closed-source LLMs (GPT-5.5, Claude-Opus-4.7, Gemini-3.1-Pro), two open-source general LLMs (DeepSeek-V4-Pro, Qwen-3.5), and two medical-specialized LLMs (Baichuan-M3, MedGemma).
Key Findings:
- Performance on static knowledge tests does not reliably translate to interactive clinical performance. GPT-5.5 achieved the highest overall micro rubric completion rate (60.4%), with other frontier models trailing closely. All LLMs—including medical-tuned models—display pronounced weaknesses in PBLI (max 25.8%), a competency requiring self-reflection and error acknowledgment.
- Medical-specialized models underperform generalist LLMs in simulated clinical encounters. Baichuan-M3 (40.0%) and MedGemma (39.5%) were significantly outperformed even by open-source general LLMs; their performance deficits are pervasive rather than isolated to specific competencies, specialties, or scenario complexities.
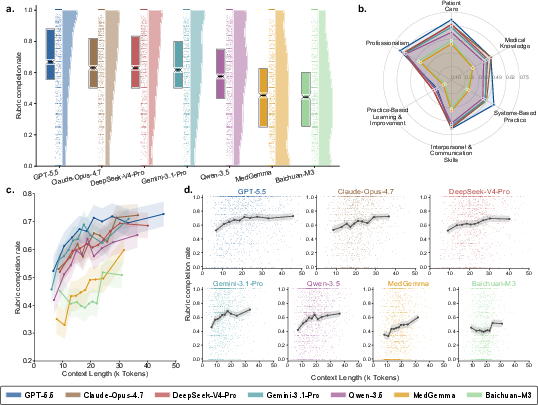
Figure 4: Model performance on MedSP1000 as overall rubric completion, per-competency radar plot, and effect of input context length.
- Context length analysis: Completion rates increase monotonically with input length for models with adequate context windows, debunking the “lost in the middle” degradation hypothesis except for Baichuan-M3 (context-limited at 41K tokens).
- Specialty-level performance: Acute, protocol-driven specialties such as Emergency Medicine, Internal Medicine, Surgery, and Critical Care yield systematically higher completion rates, likely due to more explicit action cues and less contextual ambiguity.
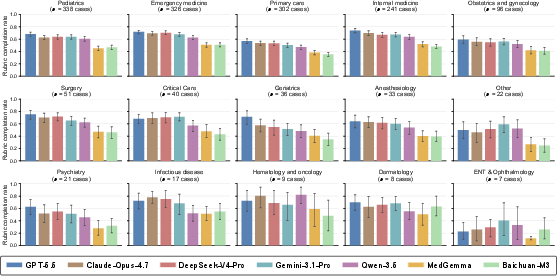
Figure 5: Specialty-level rubric completion rates highlighting per-specialty variation and model family stratification.
Test-Time Compute and Multi-Agent Strategies
Deploying additional test-time compute via Best-of-N (BoN, N=5) and multidisciplinary team (MDT) multi-agent scaffolding was assessed for GPT-5.5. Neither self-consistency aggregation nor specialist ensemble deliberation offered statistically significant improvements on overall or competency-specific rubric completion. Only ICS domain metrics showed a small, consistent gain, in line with the premise that team discussion enhances communication performance—but at the cost of potential overconfidence and premature case termination, as demonstrated in scenario-specific analyses.
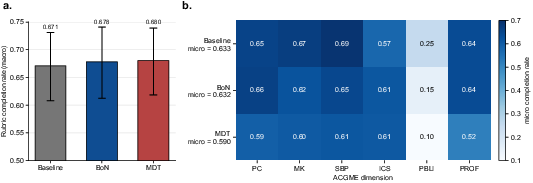
Figure 6: Assessment of baseline single-pass, Best-of-N, and MDT strategies for GPT-5.5, showing negligible improvement from additional test-time compute.
Case Study Analyses

Figure 7: Case study—Acute stroke management by GPT-5.5, highlighting protocol compliance and granular omissions.

Figure 8: Case study—Prenatal nutrition counseling by GPT-5.5, exposing a disconnect between information gathering and actionable guidance.
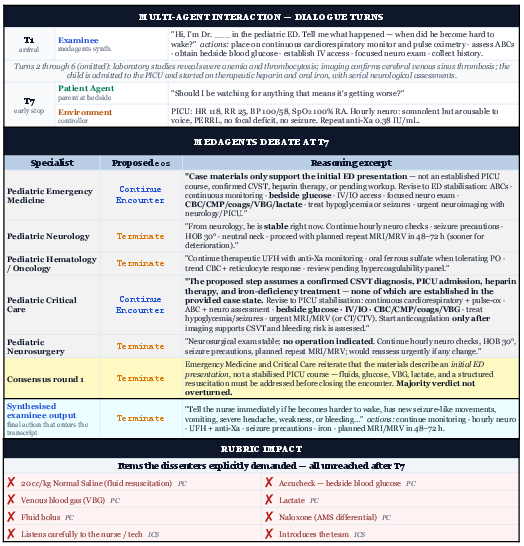
Figure 9: Case study—MedAgents multi-agent scenario with premature termination leaving core assessment actions unreached.
The case studies underscore two critical trends: (1) High-level procedural success masks fine-grained protocol lapses that are only exposed by process-level evaluation. (2) Adequacy in information gathering does not guarantee actionable or guideline-concordant decision-making. (3) Multi-agent deliberation introduces new failure modes—specifically early exit by majority voting—without robust gains in clinical competency coverage.
Implications for AI Development in Medicine
The results of this study underscore a substantive mismatch between LLMs' performance on static benchmarks and their reliability as interactive clinical agents in dynamic, partially observed longitudinal scenarios. In particular:
- Medical LLM development requires a paradigm shift. Static question-answering fine-tuning induces overfitting that is antithetical to the demands of real-world clinical workflows, which are multistep, contextually entangled, and require both evidence synthesis and nuanced self-assessment.
- Agentic capabilities must be prioritized over narrowly scoped medical knowledge. General-domain models, by virtue of expansive training on generic reasoning and long-context material, demonstrably outperform medical specialized LLMs in simulated clinical practice scenarios.
- Benchmarking must evolve to process-level, longitudinal, and outcome-coupled metrics. Isolated short-answer competence will not suffice for regulatory or safety-critical applications in clinical environments.
The lack of significant gain from test-time compute upscaling or multi-agent strategies suggests persistent limitations in current LLM agent architectures for sequential, high-stakes reasoning tasks.
Conclusion
MedSP1000 provides the first large-scale, process-level, interactive benchmark for evaluating LLMs as simulated clinicians, mirroring educational methodologies in actual medical training. Results indicate that, despite recent advances, current LLMs—including highly-tuned medical-domain variants—exhibit critical and reproducible deficits in interactive clinical decision-making, particularly in self-reflective competencies, longitudinal management, and context integration. These findings have direct implications for both the validation and regulatory oversight of future LLM-based clinical agents. Significant work remains to advance both architectural and procedural frameworks before AI can approach autonomous or semi-autonomous integration into everyday clinical workflows.
References
- "Evaluating LLMs in Dynamic Clinical Decision-Making with Standardized Patient Cases" (2606.05112)
- Additional references are embedded in the cited sections of the original paper.

