- The paper’s main contribution is the decoupling of sparse selection from attention via a Forecast projection that enables one-layer lookahead.
- It demonstrates that overlapping CPU-to-GPU KV prefetch with computation reduces wall time, achieving up to 2.5× speedup in prefill and 2.1× in decode.
- SparDA integrates with existing LLMs by training less than 0.5% additional parameters, significantly enhancing throughput and scalability for long-context inference.
SparDA: Sparse Decoupled Attention for Efficient Long-Context LLM Inference
Introduction and Motivation
The demand for long-context inference in LLMs has exposed critical system bottlenecks in compute, memory bandwidth, and especially memory capacity due to the linear growth of the KV cache with sequence length. Existing sparse attention methods attenuate compute and bandwidth demands, but do little for absolute memory footprint, leaving CPU offloading with PCIe bottlenecks as the only recourse at scale. Furthermore, while attention computation attains O(T) complexity via sparsity, the associated sparse selection logic for top-k retrieval often retains O(T2) scaling, dominating wall time for very long contexts.
SparDA (Sparse Decoupled Attention) introduces a fundamental reorganization: sparse selection is decoupled from attention at the architectural level via a dedicated per-layer Forecast projection. This enables cross-layer “lookahead” selection of keys and values, systematic overlap of CPU-to-GPU KV prefetch with current-layer compute, and a compact selection indexer that breaks the tight linkage to the attention head structure.
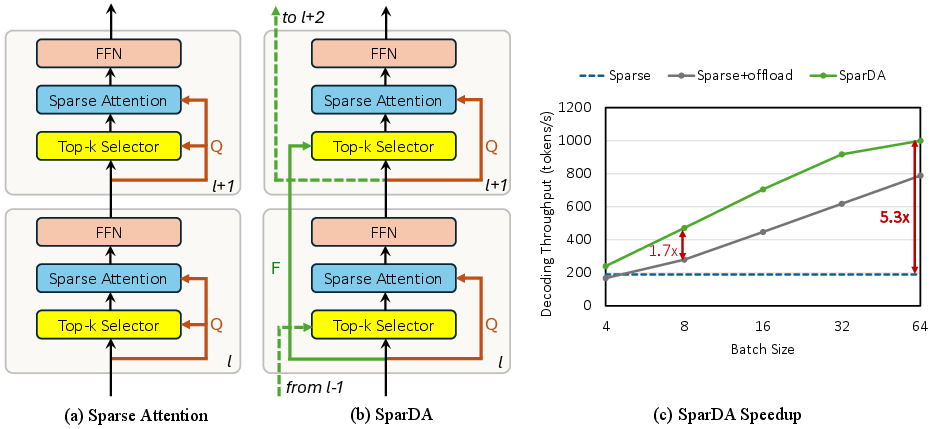
Figure 1: Overview of SparDA. The Forecast Fl predicts selected blocks for layer l+1, letting KV prefetch overlap with compute, achieving higher speedups and enabling larger batch sizes for decode.
SparDA Architecture and Method
SparDA adds a Forecast projection, Fl, to each transformer layer alongside the standard Query, Key, and Value projections. While prior block-sparse attention (e.g., InfLLM-V2) computes top-k selection and attention using the same query, SparDA decouples these: the current-layer Forecast computes top-k block selection for the next layer, shifting selection off the critical path and permitting one-layer lookahead.
The key functional steps for a given layer l are:
- The module computes (Ql,Kl,Vl,Fl)=ϕl(Xl), where k0 is the Forecast.
- The block set to be attended in layer k1 is constructed as k2, merging initial, local, and top-k3 blocks predicted from a dot-product between k4 and mean-compressed keys of layer k5.
- Attention at layer k6 uses only keys and values in the predicted k7.
Notably, the selection indexer is dramatically compressed: instead of the original per-query-head scoring loop, SparDA’s indexer computes block selection with a single Forecast head per GQA group, eliminating redundant computations. This is feasible since the Forecast no longer participates in the actual attention computation and thus avoids precision and structural coupling with the multi-head attention layout.
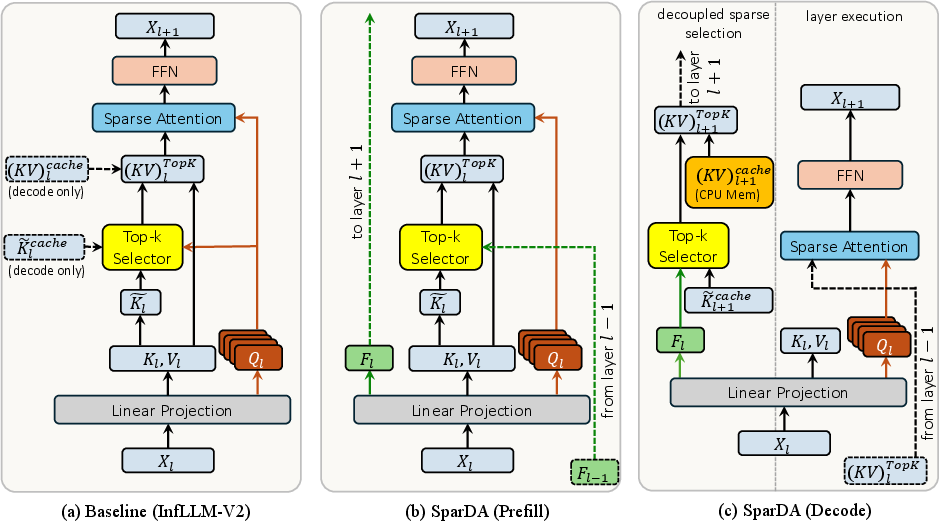
Figure 2: SparDA decouples selection from attention (b), replacing the baseline’s multi-head query-driven selector (a) with a compact, one-Forecast-per-GQA-group indexer (c), which enables lookahead selection and prefetch.
Training and Integration
SparDA is designed to retrofit existing sparse-pretrained LLMs. Only the Forecast projections (k80.5% parameters) are trained, leaving backbone weights untouched. Training minimizes the KL divergence between SparDA’s Forecast-driven block selection and the original (multi-head) selector, using a high-resolution supervision signal (i.e., finer mean-pooling over keys for the training target), producing sharper block ranking and improved selection accuracy. This training is extremely lightweight (<2 days on 32 GPUs for 8B models), thus imposing minimal overhead when integrating into large-scale LLM serving systems.
Experimental Results
Accuracy
On two block-sparse 8B models (MiniCPM4.1-8B and NOSA-8B), SparDA either matches or outperforms the original sparse baseline across aggregate metrics (HELMET, LongBench, RULER, long reasoning) at maximum context. Gains are especially notable in length generalization: on RULER, SparDA outperforms Sparse at all evaluated sequence lengths with the gap widening at longer contexts (e.g., +4.3% at 128K for NOSA-8B). This demonstrates that the learned Forecast indexer generalizes robustly to longer input sequences, a property not observed with training-free methods like InfiniGen, which suffer marked degradation.
Efficiency
Selection and Attention Cost Breakdown
The decoupled indexer’s computational cost is nearly flat with sequence length, while the baseline’s selection cost grows sharply and dominates wall time at long contexts. During prefill, SparDA reduces block-selection cost up to 2.5k9 at 128K; during decode, selection cost is virtually eliminated, rendering decode latency largely insensitive to context length.
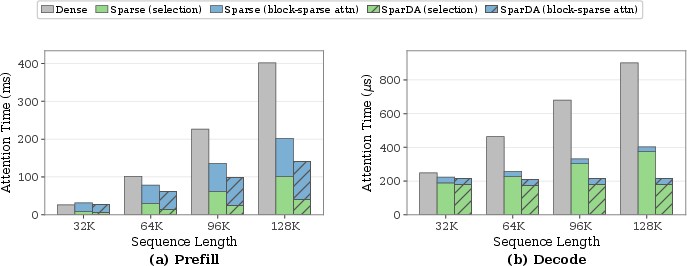
Figure 3: Per-layer attention wall time on MiniCPM4.1-8B at batch size 4. SparDA slashes block-selection cost for both prefill and decode, making selection negligible even at 128K context.
Throughput
- Prefill: At batch size 4 and 128K sequence length, SparDA reaches up to 1.25O(T2)0 (prefill) and 2.1O(T2)1 (over Dense attention) higher throughput than the sparse (and dense) baselines.
- Decode: The lookahead prefetch pipeline, which transports only the keys/values needed by the selected blocks, regularly achieves 1.7O(T2)2 speedup over Sparse in the offload regime. Most critically, CPU offloading permits viable execution at larger batch sizes: SparDA achieves up to 5.3O(T2)3 higher decode throughput than Sparse (no-offload) at feasible batch sizes and long contexts, with peak speedups in the range of B8--B16.
Implementation
A persistent Triton kernel leverages NVIDIA’s Unified Virtual Addressing (UVA) to asynchronously prefetch predicted KV blocks from CPU, overlapping PCIe transfers with current GPU computation and dynamically adjusting resource allocation (number of CTAs) to maximize system throughput with changing batch sizes.
Limitations and Implications
SparDA strictly inherits the expressivity and accuracy limitations of its base sparse attention method; it does not alter the underlying sparsity pattern or introduce new forms of semantic selection. Nevertheless, its lookahead/decoupling architecture generalizes to any block-sparse and, with only minor modifications, token-sparse (e.g., DSA, CSA) attention modules. This re-architecting effectively transforms sparse attention’s compute-focused benefits into joint compute and memory system optimizations, a prerequisite for scaling to even longer context and larger batch LLM serving on single-device GPU instances.
On the theoretical axis, SparDA demonstrates the utility of decoupling memory access and computational scheduling signals by predicting access structures layer-wise, an approach that could be extended to more general forms of sparsity (e.g., retrieval-augmented, document, temporal), moving LLM deployment architectures closer to dynamic, data-driven compute/memory systems.
Looking forward, integrating SparDA-like forecasters into token-level sparsity methods and unifying indexer prefetching logic within emerging multi-modal or retrieval-augmented models are promising directions for both AI efficiency and system co-design.
Conclusion
SparDA proposes a minimal, backward-compatible architectural extension that decouples sparse selection from attention by precomputing indexer outputs with a lightweight Forecast head per GQA group. This enables systematic lookahead prefetching of offloaded KV blocks, eliminates O(T2)4 selection scaling, and allows orders-of-magnitude larger batch long-context inference without loss in accuracy or retraining the LLM backbone. These findings strongly motivate future LLM and system codesign for fine-grained, trainable scheduling of memory and computation, especially as context and deployment scale continue to grow.
Reference: "SparDA: Sparse Decoupled Attention for Efficient Long-Context LLM Inference" (2606.04511)

