- The paper introduces a rubric-based evaluation method that decomposes audio instructions into atomic items for fine-grained alignment scoring.
- The paper establishes a multi-domain, bilingual benchmark with 7,920 instruction-audio pairs and a 105K sample corpus for robust assessment.
- The paper demonstrates that rubric-guided fine-tuning improves accuracy, interpretability, and effective reward modeling in RL optimization.
AnyAudio-Judge: Dynamic Rubric-Based Evaluation and Benchmarking for Instruction-Following Audio Models
Motivation and Problem Statement
Instruction-guided audio generation models, spanning speech (InstructTTS), sound synthesis, and music creation, are advancing rapidly due to improvements in foundation models. As these models address increasingly complex prompts encoding both semantic and fine-grained acoustic requirements, alignment evaluation becomes both more challenging and more critical. Existing automatic assessment methods, such as CLAP embedding similarity or LLM/LALM holistic judgments (e.g., via Gemini), are coarse, poorly interpretable, and exhibit low sensitivity to mismatches on compositional or local attributes. Furthermore, the field lacks systematic, multi-domain benchmarks with challenging negative samples required to robustly evaluate model discrimination.
The paper introduces AnyAudio-Judge, a rubric-based evaluation paradigm, a rich multi-domain bilingual benchmark, a large-scale supervised corpus, and a dedicated alignment evaluator, all targeting instruction-audio alignment across speech, sound, music, and mixed domains.
AnyAudio-Judge Bench Construction
AnyAudio-Judge Bench stands out for its coverage and rigor. It comprises 7,920 carefully curated positive and hard negative instruction-audio pairs, spanning real and generated samples for four domains: speech, sound, music, and mixed content. The negative samples are synthesized along two axes: (1) instruction swapping (to induce semantic mismatch, e.g., swapping instructions between unrelated samples), and (2) attribute perturbation (targeted modifications in instructions to create plausible yet misaligned negatives). An LLM is used for fine-grained attribute edits, simulating realistic failure modes in style, temporal structure, timbre, and other compositional attributes.
As an additional contribution, the benchmark is fully bilingual (English and Chinese), with instruction text translated symmetrically across both languages while all audio is left unaltered. This symmetric evaluation set enables robust analysis of cross-lingual generalization.
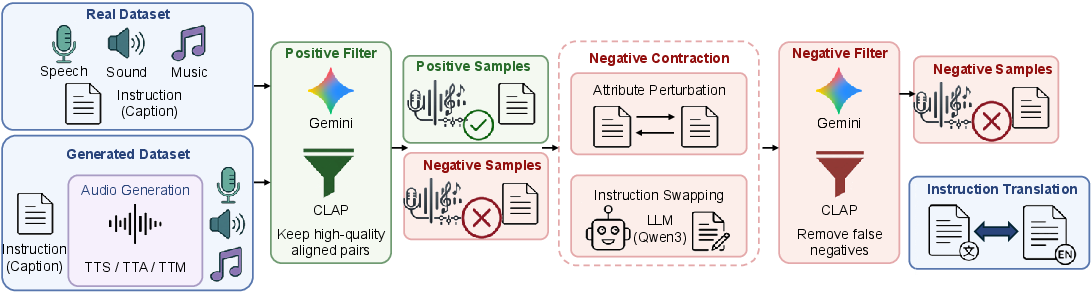
Figure 1: The pipeline for constructing the AnyAudio-Judge Bench, showing multi-domain collection, positive pair verification, hard negative design, and bilingual expansion.
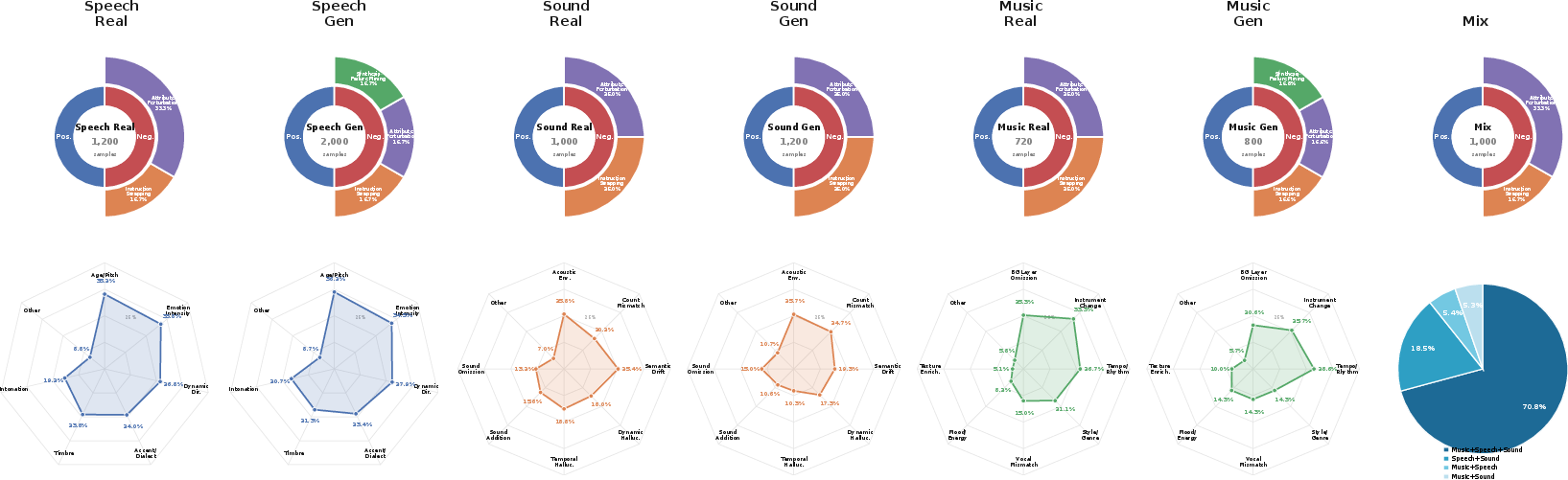
Figure 2: Quantitative breakdown of subsets, negative types, and cross-domain distributions in AnyAudio-Judge Bench.
Dynamic Rubric-Based Evaluation Paradigm
AnyAudio-Judge reframes evaluation as a dynamic, interpretable process: for each instruction, an LLM (e.g., Qwen3-30B) decomposes the input into n verifiable rubric items—atomic, binary questions that directly test individual requirements (e.g., "Is the speaker's emotion calm?", "Is there background music?"). For each item, the judge model predicts a yes/no probability using audio-text reasoning and aggregates scores across items to yield a scalar, interpretable alignment metric.
This mechanism delivers two key advances: (a) increased sensitivity to partial or compositional failures, and (b) itemized, actionable rationales highlighting exactly which facets are not matched by the generation. The number of rubric items adapts to instruction complexity, scaling up as prompts specify richer or more detailed constraints.
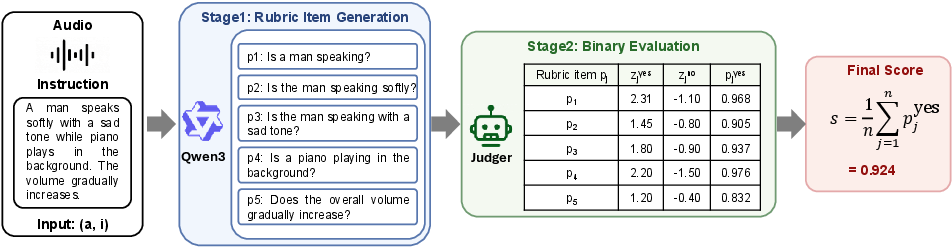
Figure 3: AnyAudio-Judge decomposes instructions, evaluates each binary item, and aggregates probabilistic judgments into interpretability-aligned scalar scores.
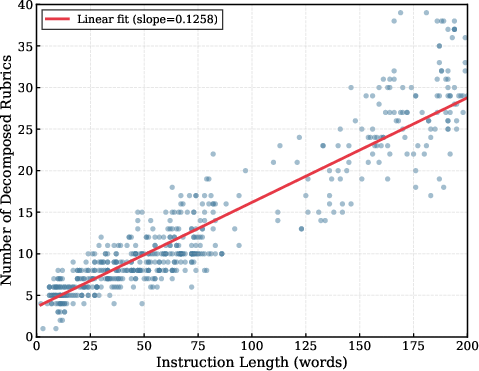
Figure 4: The number of rubric items scales with instruction complexity, enhancing granularity for challenging cases.
AnyAudio-Judge Corpus and Model Training
The AnyAudio-Judge Corpus, independent from the official benchmark, is constructed for large-scale supervised and RL reward learning. It contains 105K samples across the same domains (30K each for speech, sound, music; 15K for mixed), with strict positive-negative balance. For each sample, rubric decomposition is paired with gold binary judgments and explicit Chain-of-Thought rationales, leveraging LLM-based comparison between ground-truth and modified captions.
The AnyAudio-Judge model is initialized from Qwen3-Omni-30B-A3B-Captioner and fine-tuned in two phases: SFT to teach rubric-following and rationale generation, then Group Relative Policy Optimization (GRPO) targeting difficult examples and scoring on format, global, and per-item accuracy using LoRA on 16 H20 GPUs.
Experimental Results and Analysis
On the AnyAudio-Judge Bench, all LALM baselines see substantial gains when switched from holistic to rubric-based prompting; however, prompt-only approaches are bottlenecked by weak audio-text reasoning and lack of rubric-aligned optimization.
AnyAudio-Judge, with explicit rubric supervision, achieves the best reported average accuracy: 85.26 (zh) and 84.45 (en), compared to Gemini's 80.01/77.72. The advantage is most pronounced for (1) hard negative discrimination, (2) mixed and sound domains, and (3) cross-lingual robustness. ABLATION confirms large improvements from the rubric paradigm itself, with SFT and GRPO yielding further, though incremental, gains.
On the external PAM dataset, AnyAudio-Judge also obtains the highest human correlation among automated metrics, outperforming embedding-based (CLAPScore) and LALM-based (AQAScore) baselines in LCC, SRCC, and KTAU.
Application: Reward Modeling and Downstream RL
AnyAudio-Judge is deployed as a reward signal for RL fine-tuning of instruction-TTS systems (e.g., DiTAR). Its alignment signal, being dense and interpretable, provides more effective optimization supervision compared to binary preferences or black-box similarity. In RL, reward trajectories show consistent increases in rubric satisfaction over time.
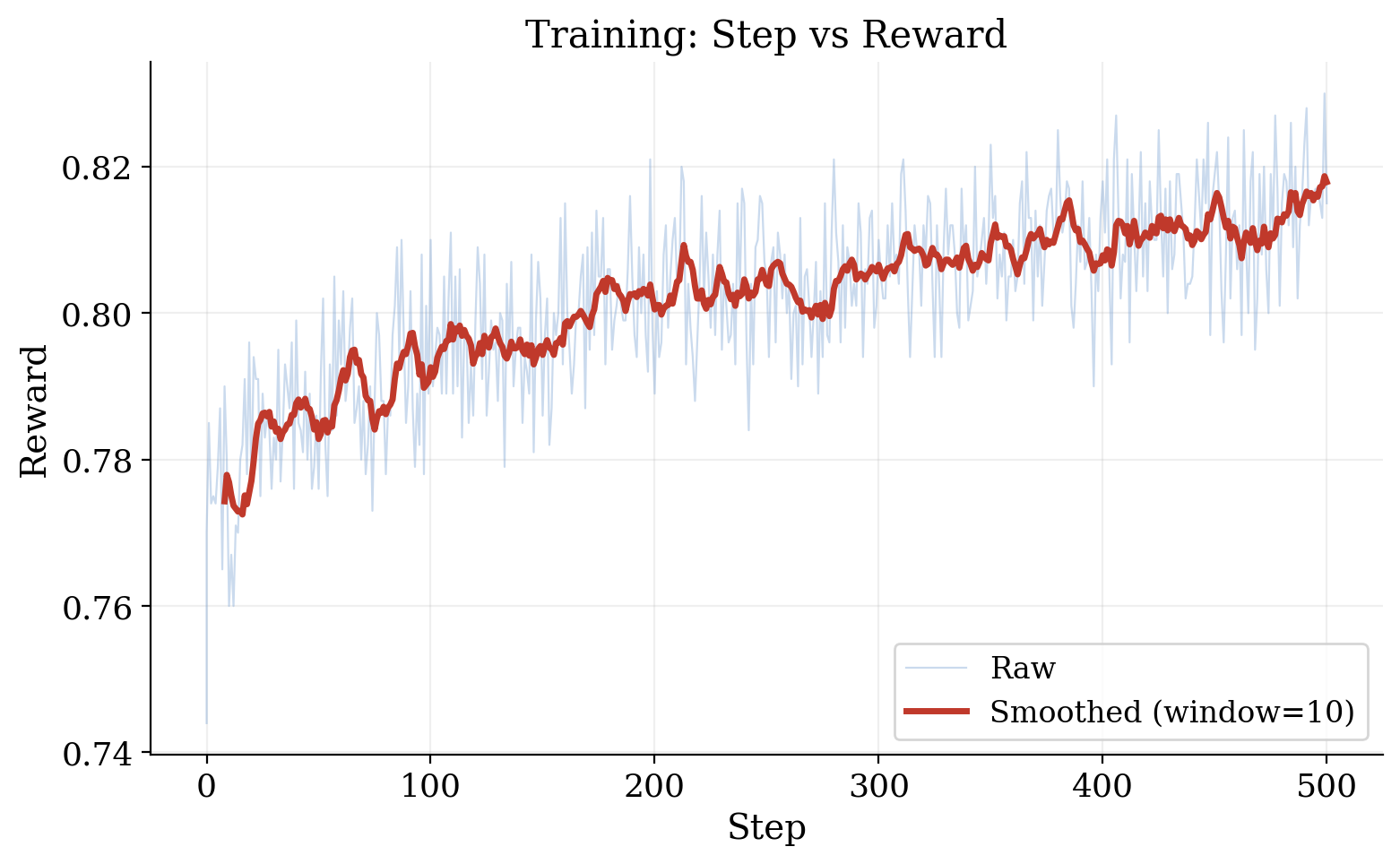
Figure 5: Monotonic improvement of model reward during RL, driven by AnyAudio-Judge-aligned optimization.
Final downstream models, when evaluated on both automatic metrics (Gemini) and blinded human preference, demonstrate consistent improvement with AnyAudio-Judge-based reward, surpassing base models and alternative reward strategies.
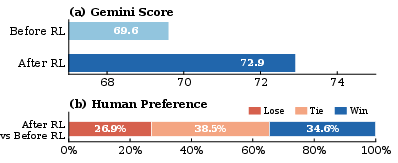
Figure 6: Human and Gemini preference improvements for InstructTTS after RL with AnyAudio-Judge reward.
Theoretical and Practical Implications
The instantiation of a dynamic rubric-based paradigm offers a framework for interpretable, compositional, and fine-grained evaluation in open-ended generative tasks—not limited to audio. It exposes the pathway for integrating evaluators as dense reward models in RL, supporting stable and semantically meaningful optimization. The AnyAudio-Judge Bench provides a high-variance, multi-domain diagnostic set for future model development, and the bilingual corpus underpins research in cross-lingual model assessment.
Potential directions include improvement of rubric decomposition via richer instruction parsing, semi-automatic rubric calibration based on human meta-feedback, and the extension of rubric-based evaluation to vision and multimodal benchmarks demanding compositional verification.
Conclusion
AnyAudio-Judge advances the state of automated instruction-audio alignment evaluation by combining a dynamic rubric-based mechanism, a challenging multi-domain benchmark, a large annotated corpus, and a dedicated, high-sensitivity evaluator. Empirical results establish significant gains over prior paradigms in both bench and real-world RL scenarios. This work sets methodological and practical baselines for future progress in interpretable, compositional reward modeling and evaluation for generative AI systems.