- The paper presents a unified, multimodal, reference-free framework (SAJ) that evaluates audio separation perceptually.
- It employs a Transformer-based architecture integrating audio, text, and visual prompts to mimic human judgment accurately.
- It demonstrates superior correlations with human scores and enhances tasks like reranking and data filtering in audio separation.
SAM Audio Judge: Multimodal Reference-Free Evaluation for Perceptual Audio Separation
Motivation and Limitations of Existing Evaluation Approaches
Audio separation systems have historically relied on distortion-based metrics (SDR, SI-SDR, SIR, SAR), which require ground-truth references and lack alignment with perceptual judgment. These signal-fidelity metrics can exhibit poor correlation with human mean opinion scores (MOS), especially in the presence of subtle artifacts or semantic mismatches. Alternative perceptual metrics (POLQA, ViSQOL) and embedding-based methods (FAD, CLAP similarity) have improved semantic awareness but remain restricted in scope—often limited to speech, requiring matched references, or failing to address prompt-conditioned separation.
Subjective listening studies remain essential but are non-scalable, expensive, and poorly suited for prompt-aware tasks. The lack of automated, reference-free, and prompt-compatible evaluation frameworks has hampered progress in open-domain and multimodal separation research.
Dataset Construction and Human Annotation Protocol
To bridge this gap, the SAM Audio Judge (SAJ) framework introduces a large-scale, fine-grained, annotated dataset designed for perceptual evaluation of audio separation outputs across speech, music, and diverse sound modalities. The collected dataset applies nine perceptual axes, with an emphasis on four dimensions for system performance: recall, precision, faithfulness, and overall quality. These axes are rated on a five-point Likert scale, with protocol definitions provided to raters, including dedicated guidelines, calibration audio, and robust rater qualification using a Bayesian mixture-model approach.
The resulting dataset covers real and synthetic mixtures, text-prompted tasks, and outputs from both promptless and prompt-conditioned separation models. Rater agreement is ensured, and three-stage balancing mitigates score and source distributional artifacts.
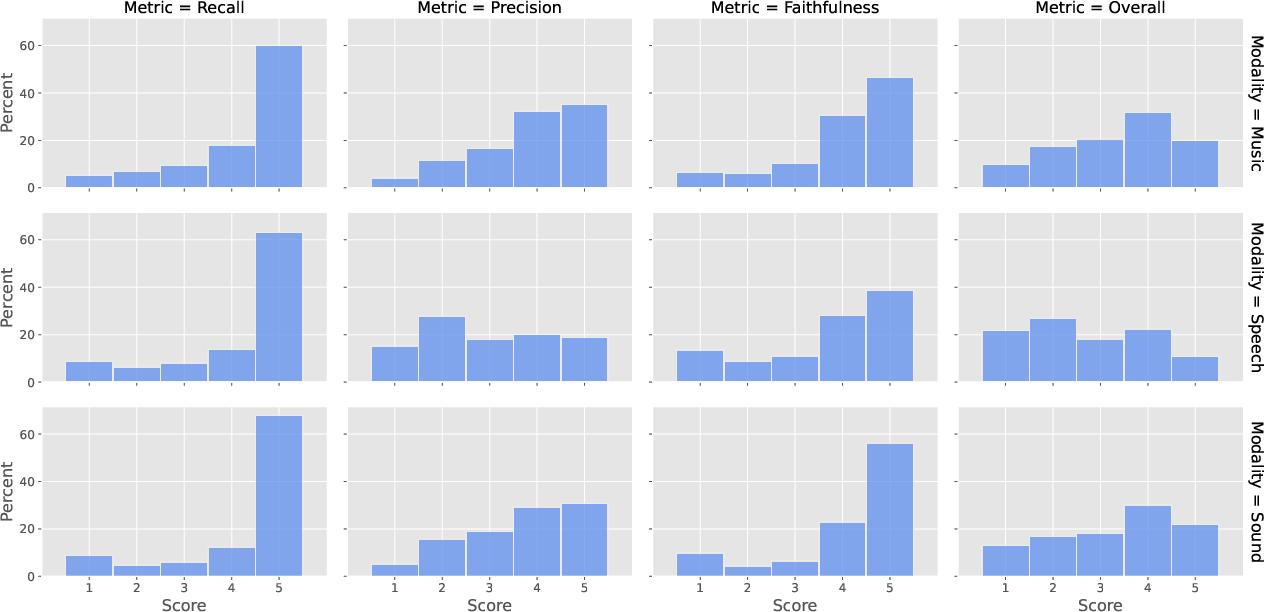
Figure 1: Distribution of recall, precision, faithfulness, and overall scores across the speech, music, and sound modalities.
Correlations Between Perceptual Axes
Analysis of joint score distributions demonstrates strong positive correlations among recall, precision, faithfulness, and overall ratings, indicating that the designed axes are all valid contributors to the unified assessment of separation quality.
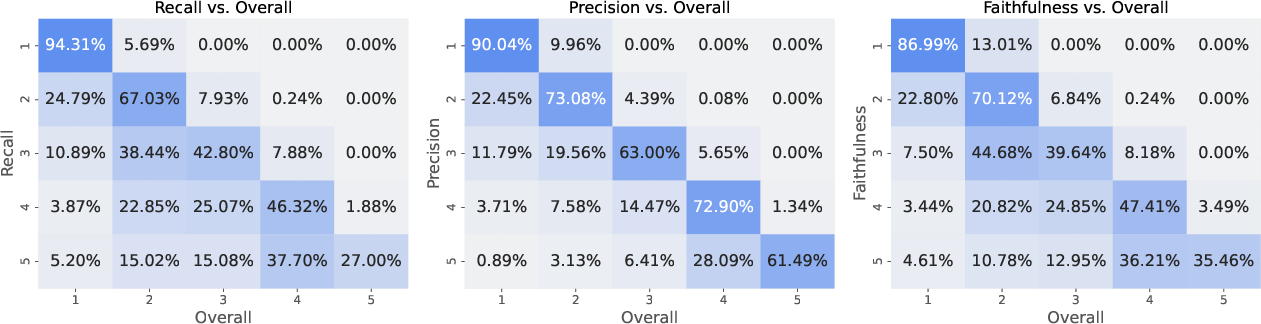
Figure 2: Joint score distributions between recall, precision, faithfulness, and overall ratings. The horizontal axes are normalized for each metric, allowing direct comparison of their correlation patterns with the overall rating.
Model Architecture and Multimodal Prompt Conditioning
SAJ employs a Transformer-based architecture, integrating input mixture, separated audio, and any combination of text descriptions (text prompts), visual masks (visual prompts), or temporal intervals (span prompts). Audio and text features are encoded via PE-AV models pretrained on large-scale audio-visual-text contrastive objectives, while span and visual features are incorporated through modality-specific encoders. Temporal and textual features are fused using self-attention and cross-attention, followed by joint feature learning and regression to perceptual scores in each axis.
An auxiliary prompt-audio alignment task, trained via simulated mixtures, enables the model to incorporate prompt adherence as a supervisory signal, boosting performance and cross-modal binding.
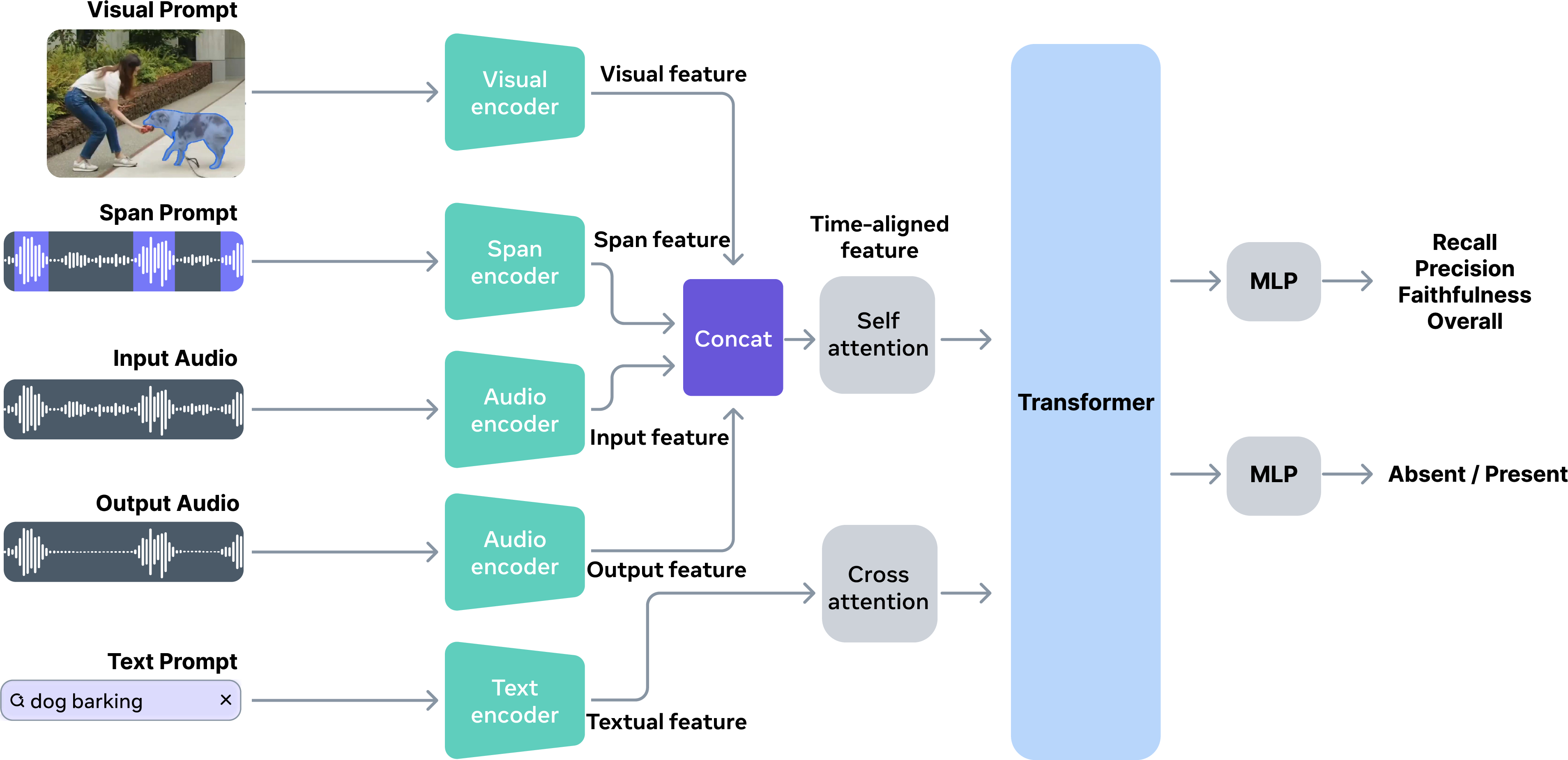
Figure 3: Overview of the SAJ model. Given the input audio and output audio, SAJ predicts the separation performance in four dimensions (recall, precision, faithfulness and overall), conditioned on any combination of text descriptions, visual masks, and temporal intervals.
Benchmarking: Alignment with Human Judgment
Comparison against contrastive text-audio similarity (CLAP), aesthetic complexity scoring (AES-PC), reference-free SDR estimator, and multimodal LLM baselines demonstrates that SAJ achieves markedly superior Pearson (0.88 speech, 0.81 music/sound) and Spearman correlations with human ratings versus all baselines. The model is robust across modalities, able to generalize beyond speech, and its gains are substantiated by joint training, backbone multimodality, auxiliary task inclusion, and careful dataset balancing.
Practical Applications: Reranking, Data Filtering, and Pseudo Labeling
SAJ delivers practical value in model output reranking for perceptual quality, surpassing CLAP-based selection and delivering a full rating-point improvement in overall perceptual scores on standard separation benchmarks.
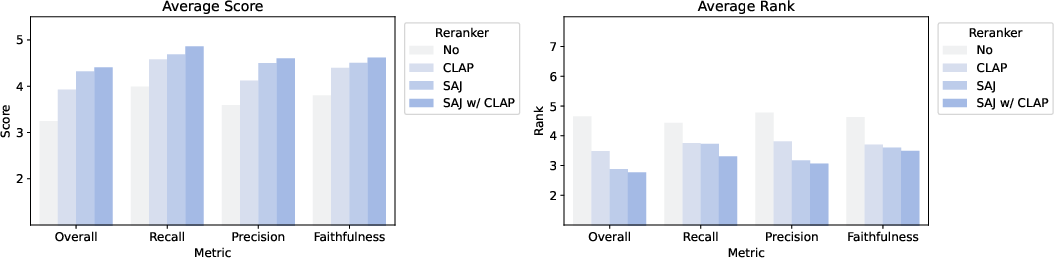
Figure 4: Separation performance comparison between different rerankers. SAJ substantially improves reranking results across all axes relative to CLAP and no-reranker baselines.
For data selection and pseudo labeling, SAJ enables threshold-based filtering that yields human-aligned high-quality subsets at scale, whereas previous pseudo-labeling strategies retained fewer samples with lower perceptual score. Sample efficiency and alignment are improved with SAJ-based curation.
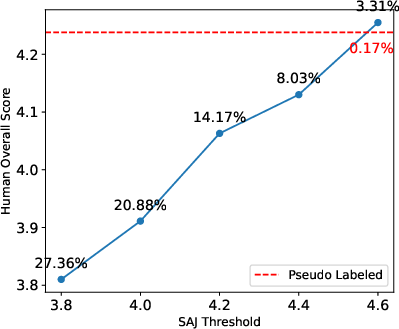
Figure 5: Human overall score as a function of the SAJ filtering threshold. Incremental filtering by SAJ score leads to increased human perceptual scores per sample.
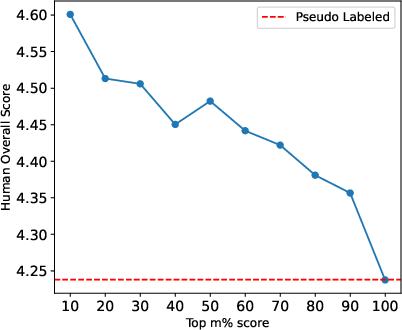
Figure 6: Quality of pseudo-labeled data after filtering with SAJ. Top-ranked subsets consistently yield higher human overall scores than the baseline pseudo-labeled data.
Multimodal Generalization and Prompt Analysis
SAJ extends to joint multimodal input conditioning, supporting arbitrary combinations of text, visual, and span prompts. The multimodal model shows that the fusion of semantic (text), spatial (visual), and temporal (span) information delivers the highest perceptual alignment. Text+span and text+visual+span configurations yield the strongest results across modalities, confirming the benefit of comprehensive prompt integration rather than unimodal or dual-modal conditioning.
Task Difficulty Assessment and Fine-Grained Evaluation Pipelines
SAJ further supports automated difficulty estimation for separation tasks—using mixture audio and prompt only—to build stratified evaluation sets, enabling robust analysis of model performance as a function of intrinsic separation complexity.
Conclusion
SAM Audio Judge establishes a reference-free, multimodal, prompt-aware perceptual evaluation standard for audio separation. The approach integrates large-scale, protocol-rigorous human annotation, cross-modal Transformer architectures, and practical pipelines for reranking, data curation, and robustness assessment. SAJ's strong alignment with human perception, scalability, and flexibility in prompt conditioning represents a substantive advance beyond distortion-based or unimodal metrics. This framework is extensible to more challenging and diverse scenarios in open-domain, prompt-conditioned sound separation, offering both theoretical and practical foundations for future research in perceptual model evaluation and multimodal learning (2601.19702).