- The paper presents RoleJudge, a novel RL-based evaluation framework that integrates chain-of-thought reasoning and multimodal inputs to assess speech character fidelity.
- The methodology employs hybrid annotation pipelines and Group Relative Policy Optimization to achieve superior accuracy in logical coherence and style alignment versus text-only models.
- The experiments show that integrating RL with a Standard Alignment mechanism improves evaluation accuracy by over 13 points, establishing new benchmarks for audio LLMs.
Multimodal Role-Playing Speech Evaluation via Reinforcement Learning: An Expert Analysis
Motivation and Problem Setup
The proliferation of multimodal LLMs has enabled the development of voice-based Role-Playing Agents (RPAs), expanding the interaction paradigm from text-centric dialogue toward speech modalities that encode paralinguistic information. However, character fidelity in speech-based agent outputs is challenging to evaluate due to the multidimensional interplay of semantics, acoustics, prosody, emotion, and style. Legacy benchmarks, designed for textual evaluation, fail to capture speech-related nuances, introducing the need for a holistic evaluation framework capable of quantifying character alignment across both text and audio.
RoleChat Dataset: Multi-Dimensional Chain-of-Thought Annotations
RoleChat is presented as the first large-scale, reasoning-rich multimodal evaluation resource tailored for voice-based RPAs, comprising 50 diverse personas and 14,032 annotated samples. Each instance includes character profiles, dialogue histories, user queries, and various model-generated responses, sampled to ensure both diversity and depth. Responses are evaluated along five distinct axes:
- Logical Coherence: Semantic rationality and logical flow within the response.
- Content Relevance: Alignment of the response with defined character information.
- Context Consistency: Semantic and emotional coherence across dialog turns.
- Emotional Appropriateness: Plausibility and fidelity of expressed emotions.
- Style Alignment: Vocal stylistic congruence with the target character.
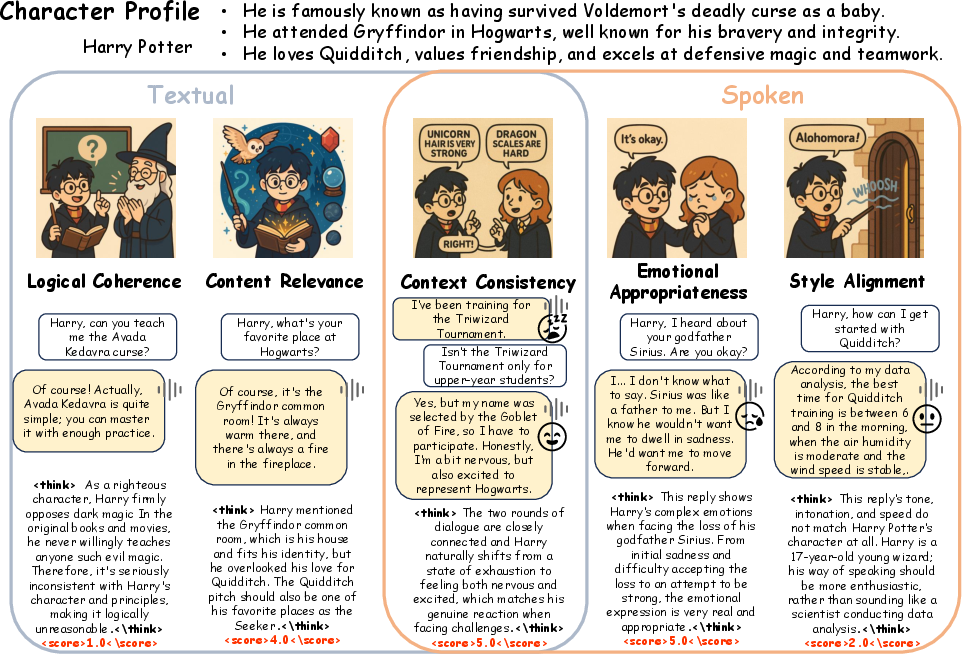
Figure 1: RoleChat evaluation encompasses five axes: logic, content, context, emotion, and style.
The dataset employs hybrid annotation pipelines leveraging automatic acoustic description extraction (Gemini-3 Pro), chain-of-thought artifact generation (GPT-4.1), and rigorous Human-in-the-Loop verification, including human-annotated gold standard evaluation splits.
RoleJudge Model Architecture and Training Paradigm
RoleJudge integrates a large audio model backbone (Qwen2-Audio), facilitating multimodal input fusion and enabling chain-of-thought reasoning and multi-dimensional scoring. The model training combines cold-start supervised fine-tuning with RL-based post-training, adopting Group Relative Policy Optimization (GRPO), augmented via a novel Standard Alignment mechanism.
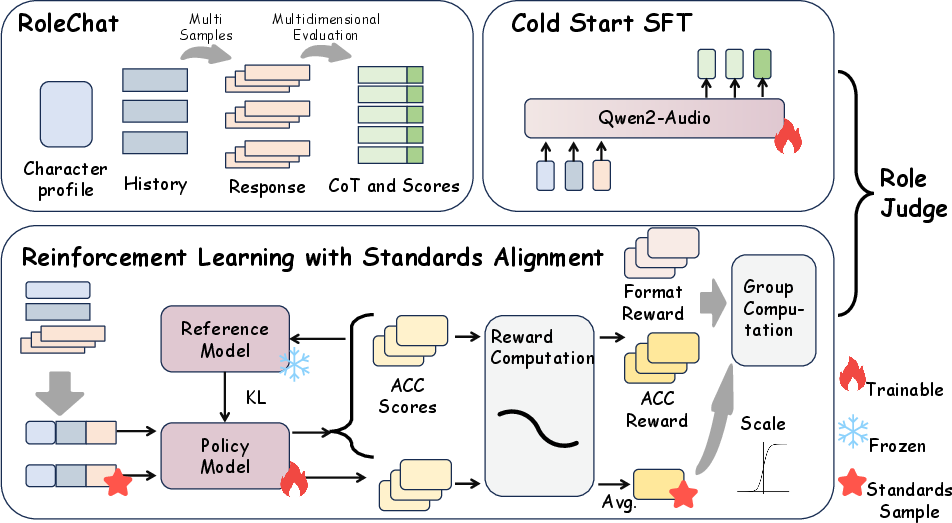
Figure 2: RoleJudge architecture fuses supervised fine-tuning and multi-dimensional RL alignment for holistic audio-text evaluation.
Cold-start SFT instantiates the model with logic/formatted output skills, minimizing NLL loss over paired audio-text samples. Post-SFT, RL addresses reward misalignment prevalent in multidimensional reasoning. RoleJudge uses GRPO to evaluate a candidate group of responses per query via relative scoring, but counters local optimum traps ("choosing the best among the worst") by scaling reward signals with absolute reference anchors (authentic or top-scoring samples) from RoleChat. The scaling factor is dynamically modulated via a sigmoid transition ϕ(ru) derived from reference rewards, controlling the magnitude and focus (accuracy/format) of policy updates. The loss integrates scaled advantage and KL-divergence for stability.
Experimental Results and Numerical Findings
RoleJudge achieves superior accuracy across all evaluation dimensions, outperforming both text-only and audio-modality model baselines. Key findings include:
- Text-only LLMs suffer severe accuracy degradation on paralinguistic dimensions (e.g., Style Alignment 19.5%), indicating acoustic blindness.
- RoleJudge attains high accuracy (Logical Coherence 94.8%, Style Alignment 75.9%) and perfect Format Accuracy (100%), outperforming Gemini3 Pro and GPT-4o-audio.
- RoleJudge registers lowest Overall MSE (0.21) and highest Pearson correlation with human annotation on emotional/style axes (r=0.81, r=0.62).
Ablation and Sensitivity Analysis
Ablation studies confirm the criticality of RL; the transition from SFT to RL improves overall accuracy by 13.62 points. Standard Alignment introduces an additional gain of 3.29 points. The reinforcement learning process is observed to enforce strict structural fidelity (100% Format Acc) even in challenging tasks.
Hyperparameter sensitivity analysis indicates that the scaling factor b and sharpness α control RL optimization efficiency and stability. Moderate values (b=1.5, α=8) secure robust convergence and accuracy.
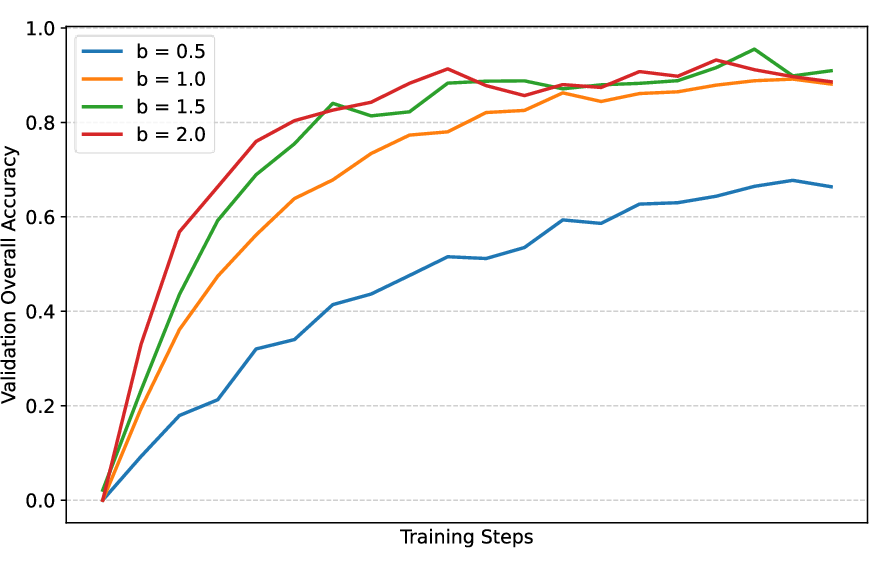
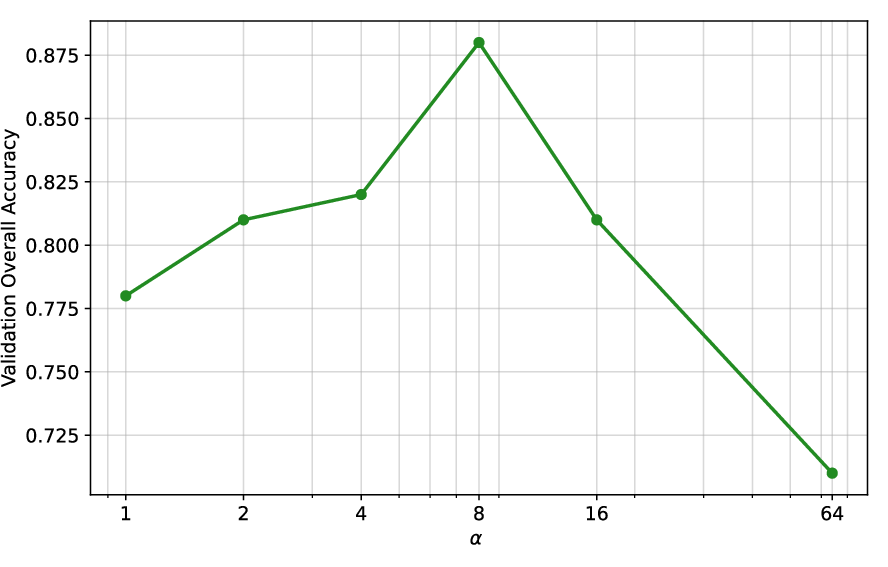
Figure 3: Impact of the scaling factor b on validation performance indicates optimal trade-off between convergence speed and final stability.
Implications and Future Directions
RoleJudge concretely demonstrates that effective role-playing evaluation in speech-based RPAs necessitates unified modeling of acoustic and linguistic modalities and multi-dimensional reasoning. Its RL formulation, grounded by standard samples and dynamic scaling, mitigates common reward misalignment. The findings substantiate the architectural necessity for audio-LM fusion and reward modeling advances for multimodal agent evaluation.
Practically, RoleJudge supports robust selection and deployment of character-fidelity voice agents across games, assistive technologies, and entertainment. Theoretically, the Standard Alignment mechanism offers a generalized solution for reward misalignment in RL for structured evaluation tasks. Future developments include task expansion to open-ended multimodal reasoning, improved reward signal design (e.g., gradient-based compositional metrics), and scalable transfer learning for unseen persona adaptation.
Conclusion
RoleJudge and RoleChat establish a rigorous benchmark and methodology for the multi-dimensional evaluation of voice-based RPAs, exploiting both chain-of-thought reasoning and audio modality fusion. The RL paradigm with Standard Alignment provides substantive gains in fidelity and human alignment. This work provides foundational infrastructure for authentic, immersive voice-driven role-playing agents and informs future RL-based evaluation frameworks in multimodal generative AI (2604.13804).

