- The paper introduces a dual-agent framework that iteratively refines candidate kernels through correctness and performance passes.
- It supports six programming models across four accelerator vendors by translating PyTorch operator descriptions into efficient kernels.
- Empirical results demonstrate throughput improvements of 2.12% overall and up to a 5.13× speedup on emerging hardware compared to standard methods.
Motivation and Problem Landscape
The rapid evolution of agentic AI pipelines and heterogeneous accelerator deployment has precipitated significant systems challenges in efficient model inference. Modern AI workloads interleave model calls, data retrieval, reasoning, and tool execution, each with highly variable compute and memory patterns. No single hardware accelerator can optimally serve all pipeline stages, and mapping each task fragment to its ideal accelerator mandates high-efficiency custom kernels across a growing landscape of hardware and programming environments. Manual kernel engineering is infeasible at this scale, given the expertise and effort required for each device and DSL. Classic compiler and graph-level runtime optimizations are insufficient for optimal memory traffic, arithmetic intensity, and cross-kernel scheduling properties. The emergence of LLM-assisted code generation offers new avenues, but until now, the generation of performant, correct kernels at scale and for non-NVIDIA backends has remained challenging.
KForge Framework Architecture
KForge is structured as a dual-agent, iterative program synthesis loop (Figure 1). This system consists of a generation agent producing candidate kernels, alternately refined through correctness- and performance-driven passes, and a performance-analysis agent delivering data-driven optimization guidance. KForge’s workflow is tightly looped: a functional pass iteratively fixes generated code based on compilation/execution outputs until it is correct, followed by optimization passes leveraging kernel profiling feedback—both programmatic and visual—to approach or surpass hand-optimized performance. Separation of functional and optimization passes, and isolation of performance analysis into a dedicated agent, yields reliable and scalable synthesis for arbitrary backend-targets.
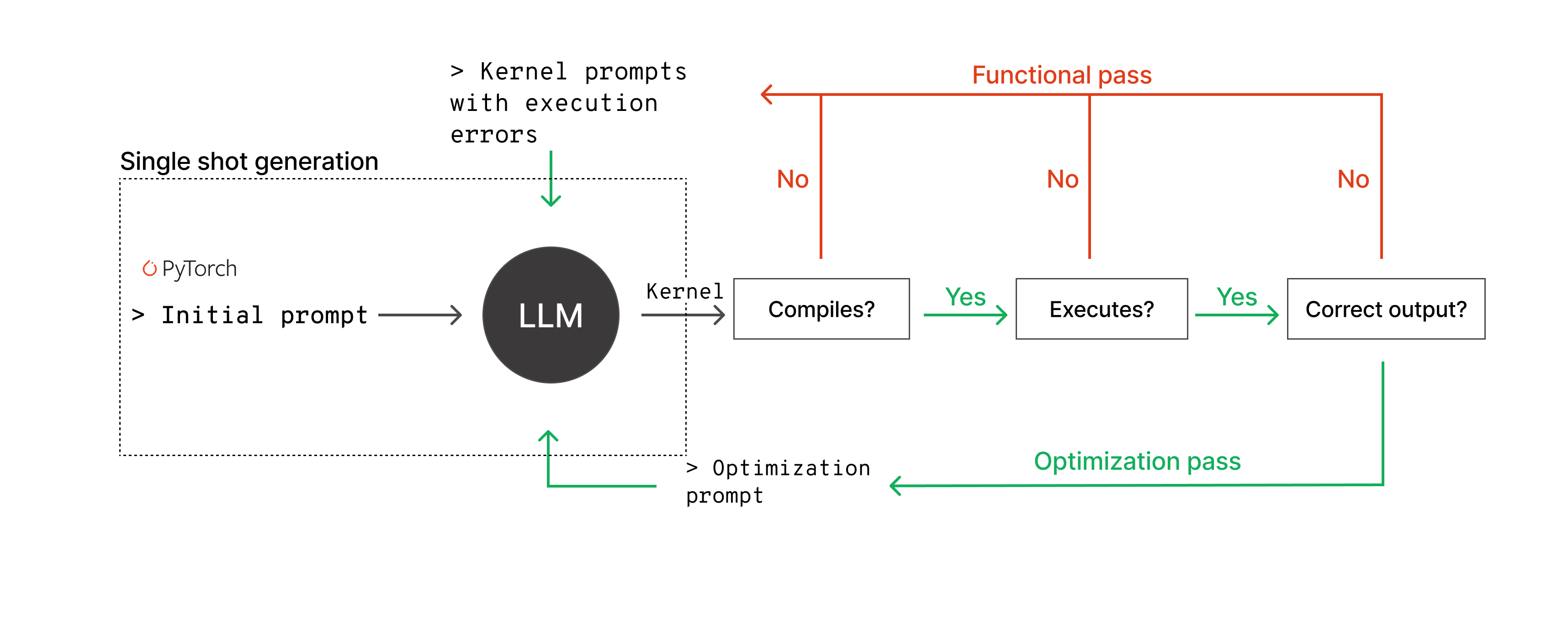
Figure 1: The core KForge synthesis loop alternates functional (correctness-focused) and optimization (performance-focused) passes, driven respectively by compilation/execution verification and hardware profiler feedback.
KForge’s scope is broad. The system supports lowering PyTorch operator descriptions to kernels in six programming models—CUDA, Triton, CuTe DSL, HIP, SYCL, and Metal—across four major accelerator vendors: NVIDIA, AMD, Intel, and Apple (Figure 2). Reference implementations in one DSL/target (when available) can be supplied for cross-platform translation, assisting backend bring-up and reducing dependence on biased training corpora. The architecture includes several features for practical deployment: candidate code guardrails, granular prompt editing and code injection, per-iteration tracing, and custom measurement hooks to accommodate diverse experimental needs. Model selection for both agents is abstracted through a registry, supporting plug-and-play LLM experimentation.
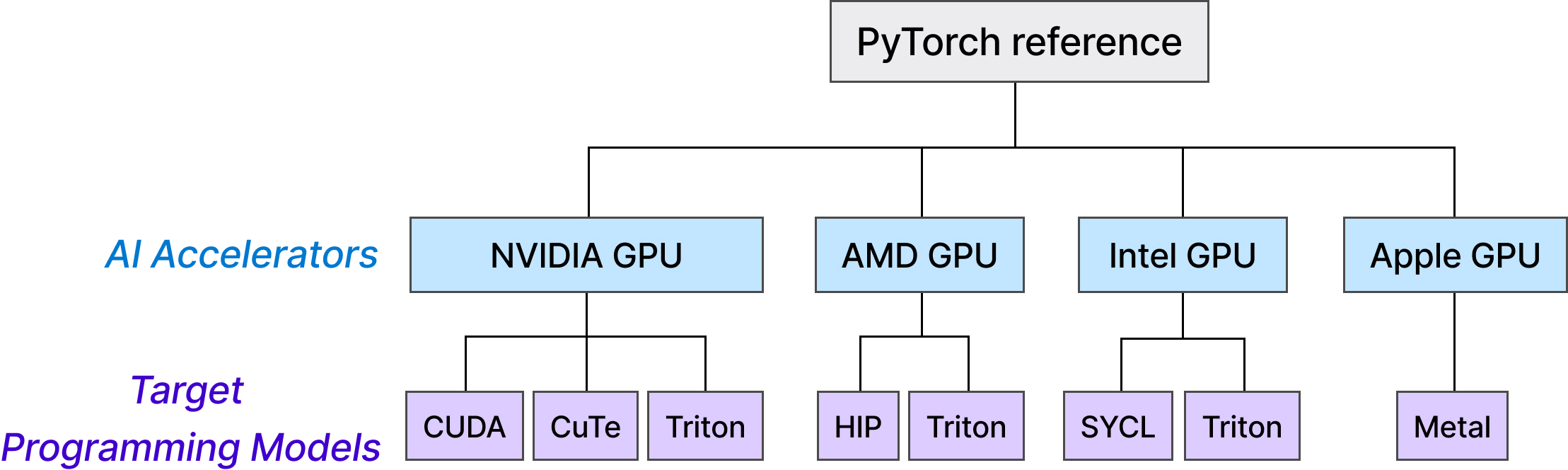
Figure 2: KForge selects and translates a PyTorch functional operator into the appropriate programming model and kernel for each supported hardware backend.
Program Synthesis and Optimization Strategies
Three program synthesis modalities are supported: (1) iterative refinement, where candidate kernels are refined using feedback from preceding execution attempts, (2) cross-platform translation via reference code when available, and (3) profile-driven optimization, leveraging hardware performance counters and profiler outputs for bottleneck identification. The separation of program synthesis and performance analysis agents is critical: LLMs’ ability to extract relevant signals from large profiler outputs degrades with context size, so agent specialization and modularity improve both correctness and optimization efficacy.
After each synthesis attempt, KForge records detailed outcome states (generation, compilation, runtime, output mismatch, success) and logs artifacts for reproducing and auditing synthesis and optimization.
Empirical Evaluation
Case Study: NVIDIA B200 (Vendor-Competitive Regime)
On NVIDIA B200, KForge was tested against TensorRT-LLM on gpt-oss-20b decode-path kernels. Kernels with available source references were profiled and selected for optimization; high-impact candidates included Fused Add + RMSNorm, MoE Finalize, and Bias + RoPE + KV Update. KForge-generated kernels consistently matched or surpassed reference performance, with notable scaling advantages at larger batch sizes. For instance, KForge’s MoE Finalize kernel achieves a 1.43× speedup over the TensorRT-LLM reference at batch size 128.
Integration into the end-to-end inference pipeline yields a 2.12% throughput improvement and a 2.07% total wall-clock reduction over TensorRT-LLM. Considering the years of vendor-baseline kernel and pipeline engineering, such absolute gains are significant for production deployments.
Case Study: Intel Arc B580 (Emergent Backend/No Reference)
KForge’s cross-platform value is most apparent on Intel’s Arc B580, where no hand-tuned references are available. Using the KernelBench Level 2 GEMM+tail-op subset as target workloads, KForge synthesizes Triton kernels achieving a 5.13× geometric mean speedup across 37 diverse problems when compared with the best of torch.compile and PyTorch eager mode. Inspection shows that KForge routinely applies layer-wise fusion, mixed-precision execution fitting the backend's XMX units, custom reduction schemes, and aggressively tailored partitioning to exploit available hardware features—tactics that torch.compile and default PyTorch cannot match without backend-specialized coding.
Theoretical and Practical Implications
KForge provides evidence that agentic, LLM-driven kernels can not only reach, but in practice, exceed vendor-optimized runtimes in constrained, real-world settings. Practically, this unlocks faster deployment of optimized kernels for hardware bring-up, vendor lock-in mitigation, and pipeline adaptation for novel architectures. The ability to leverage source code or prior implementations for cross-platform translation reduces coverage bias, and the closed iterative loop with auditing and guardrails addresses correctness assurance, an ongoing concern with LLM-driven systems.
Theoretically, KForge demonstrates the limits and current strengths of LLM program synthesis: local improvements on well-represented backends are possible, but further work will be needed to synthesize kernels from behavioral specifications (i.e., black-box, cubin-only scenarios), to target virtual ISAs like PTX for low-level optimizations, and to reason globally about groupwise kernel dependencies and bottleneck shifting effects at the architectural block level.
Future Directions
Advancing KForge involves extending coverage to additional frameworks (e.g., JAX), enhancing program verification with formal or differentially tested correctness guarantees, and scaling agentic synthesis towards block-wise or pipeline-wide joint optimization. A critical research path remains automating kernel synthesis against behavioral reference/cubin interfaces, and targeting intermediate or virtual ISAs for optimization opportunities unavailable at the source level. As LLM agents gain extended context and more robust long-horizon reasoning, such advances will become tractable.
Conclusion
KForge constitutes a systematically engineered approach to LLM-driven, cross-platform kernel synthesis, integrating correctness and optimization passes in an agentic feedback loop with robust backend and DSL coverage. Empirical results validate that agentic LLMs can deliver both microbenchmark and end-to-end throughput gains versus established hand-tuned baselines, and offer strong advantages for emerging, less-supported hardware backends. The modular separation of generation and analysis, augmentation with reference translation, and extensibility for practical deployment suggest that agentic program synthesis is poised to become a key asset for both production and research in heterogeneous AI infrastructure.

