- The paper demonstrates that leveraging LLMs for pass synthesis can automate graph-level transformations, achieving up to 3x speedup over traditional compiler baselines.
- It introduces a comprehensive PassNet-Dataset and robust PassBench benchmark to evaluate compiler pass generation across 18K unique computational graphs.
- Iterative agentic synthesis and distillation experiments validate the efficacy of scaling LLMs to reliably optimize long-tail subgraph performance.
Authoritative Summary of "PassNet: Scaling LLMs for Graph Compiler Pass Generation" (2605.29357)
Motivation and Problem Statement
The proliferation of deep learning models and heterogeneous hardware has intensified reliance on tensor compilers (e.g., TorchInductor, TVM, XLA) for operator fusion and graph-level transformation. Although existing compilers achieve notable speedups on canonical workloads, systematic profiling reveals a structural performance ceiling for long-tail subgraphs: 43% of real-world subgraphs undergo end-to-end slowdowns under TorchInductor's default compilation, with only 34% realizing marginal speedups (<1.2×). This bottleneck correlates to operator coverage—not graph complexity—implying that merely expanding operator support fails to resolve optimization gaps for rare patterns.
The paper argues that LLMs, while previously applied to kernel generation, are better suited for pass generation: the automated synthesis of structured graph transformation passes that integrate directly into compiler IR pipelines. This abstraction preserves program composability, verifiability, and enables "one-line compilation" semantics but demands large-scale training data and robust evaluation metrics absent in prior ecosystem efforts.
The PassNet Ecosystem: Dataset and Benchmark
Dataset Construction
PassNet-Dataset comprises 18,086 unique computational graphs collected from 100,000 real-world models across PyTorch and PaddlePaddle, encompassing diverse domains (CV, NLP, Multimodal, Audio). The collection pipeline leverages symbolic tracing and enforces five constraints (runnable, serializable, decomposable, statically analyzable, custom-operator accessible) to ensure structural integrity.
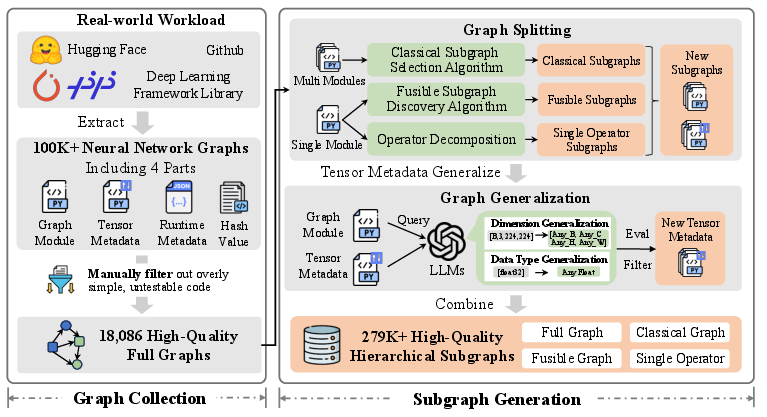
Figure 1: PassNet Dataset Construction Pipeline showing end-to-end graph extraction, recursive graph splitting, and metadata generalization for large-scale, structurally diverse subgraph generation.
Subgraph generation employs:
- Recursive Folding to abstract linear operator sequences into hierarchical motifs ([Conv2d, BatchNorm] → α, [α, ReLU] → β), capturing structural recurrence.
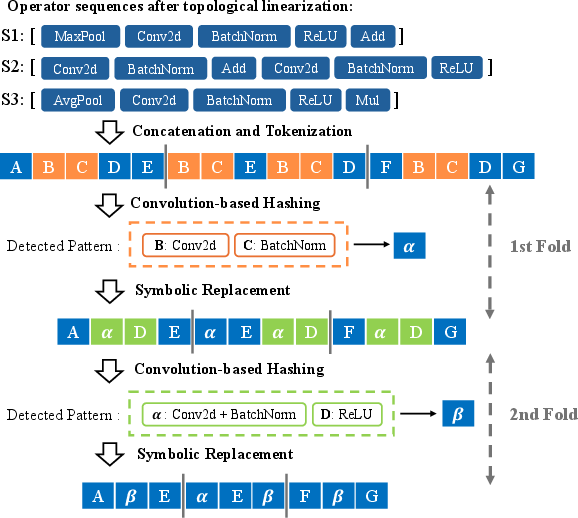
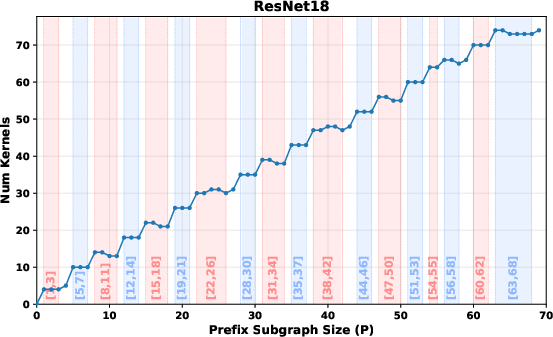
Figure 2: Recursive folding; typical convolutional blocks are represented as symbolic units to compactly capture higher-level compositional patterns.
- Prefix Analysis detects fusible plateaus in kernel-launch curves, aligning subgraph boundaries with compiler fusion potential.
- Shape/Dtype Generalization yields multiple instantiations per pattern, facilitating generalization across hardware and layout constraints.
Benchmark: PassBench
PassBench is a 200-task suite of long-tail subgraphs (2,060 unique instances), designed via operator sequence, shape, and dtype bucketing for maximal structural diversity. Its evaluation metric, Error-aware Speedup Score (ESt), unifies correctness, stability, and performance, overcoming discrete signal limitations and facilitating per-subgraph diagnosis. It employs:
- Strict and relaxed correctness tolerance regimes (weighted via Wt).
- Continuous geometric mean aggregation (AS) for agent training feedback.
- Layered integrity defenses (AST inspection, runtime dispatch interception, reverse evaluation order) addressing systematic exploitation of benchmark loopholes by LLMs.
Experimental Evaluation
Baselines and Model Comparison
Experiments assess both frontier (e.g., GPT-5.4, Claude-Opus-4.6) and open-source (e.g., GLM-5.1, MiniMax-M2.7, Qwen3-30B-A3B) models against standard compiler baselines (Eager, TorchInductor).
Key findings:
- Discriminative Signal: PassBench reveals a 3.22× AS score gap between the best and worst models.
- Aggregate Underperformance: All LLMs trail TorchInductor; best AS score (0.448) is 37% below the compiler baseline (AS=0.706). Correct outputs rarely exceed →0 speedup, highlighting limited hardware-cost awareness.
- Sparse Individual Success: Certain subgraphs achieve up to →1 speedup over TorchInductor, confirming that consistency, rather than isolated capability, is the dominant challenge.
Scaling via Iterative Agentic Synthesis
Iteration (up to 50 steps) in PassAgent demonstrates substantial improvement over single-shot evaluations; only ~38% of ultimate AS scores and ~32-52% of passing samples are captured by first attempts, highlighting the need for iterative refinement in pass synthesis.
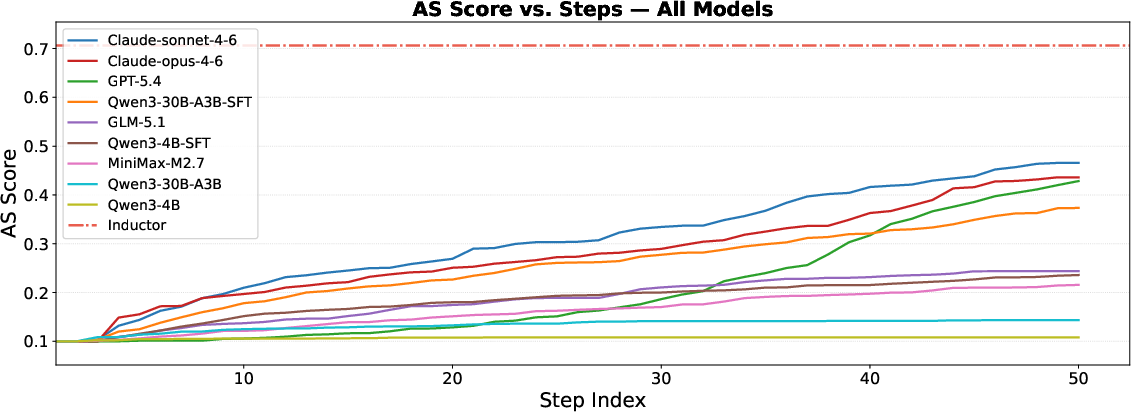
Figure 3: Agent performance scales non-linearly with iteration budget, showing increased AS score with up to 50 steps for frontier and distilled models.
Dataset Utility and Distillation
Fine-tuning smaller models (Qwen3-30B-A3B, Qwen3-4B) on →2K curated PassNet trajectories yields a →3 gain, approaching frontier-model performance. This validates PassNet-Dataset as effective training infrastructure, suggesting further headroom via scaling data, diverse teachers, and RL from →4 feedback.
Case Studies and Failure Analysis
- Roll+Slice Fusion (MaskFormer): LLM synthesizes a fused kernel recognizing semantic equivalence between roll and slice, replacing multi-kernel decomposition with a single index-arithmetic implementation—yielding up to →5 speedup.
- Masked Mean Pooling (BGE-Reranker): Compiler fails to fuse a 7-operation chain; LLM-generated pass fuses all ops, accumulating masked sums and means in optimized registers (2.90→6 speedup; bitwise identical).
Failure modes include:
- Boundary Misalignment: Over-fusion of trivial ops or redundant reimplementation of vendor primitives.
- Cost-Model Blindness: Lack of hardware awareness leads to static tiling that misses roofline or SRAM constraints.
- Semantic Disruption: Rewrites obstruct downstream compiler optimizations (e.g., disabling FlashAttention-2 routing).
Implications and Future Directions
Practical and Theoretical Impact
PassNet establishes a scalable, benchmarked ecosystem for LLM-driven compiler pass generation. The empirical results underscore the importance of structured data collection (pattern-driven, agentic, shape/dtype diverse), rigorous benchmarking (per-subgraph evaluation, anti-exploit defenses), and iterative synthesis for closing the consistency gap.
From a practical standpoint, PassNet points toward:
- Live training infrastructure for LLM compiler agents, facilitating continual improvement by distillation and reinforcement.
- Data-driven compiler pipelines capable of automating long-tail optimizations beyond manual rule engineering.
Theoretically, PassBench's unsaturated signal reveals persistent open problems in cost-model estimation, agent generalization, and semantic preservation, offering fertile ground for joint ML-compiler research.
Future Trajectory
Potential developments include:
- Multi-device and training-loop pass generation.
- Hardware cost model integration as auxiliary LLM context.
- RL training using continuous →7 feedback.
- Extension to underrepresented domains (scientific simulation, generative models).
- Enhanced anti-exploit strategies to address evolving adversarial behaviors.
Conclusion
PassNet delivers the first large-scale ecosystem for LLM-based compiler pass generation, pairing a rich, real-world dataset with discriminative, unsaturated benchmarking and robust integrity defenses. The primary bottleneck is not capability, but reliable generalization across diverse, long-tail computation patterns. Distillation experiments validate the training efficacy of PassNet-Dataset, closing the gap with frontier models and cementing its role as essential infrastructure for agentic compiler optimization. Continued expansion of the dataset, integration with cost models, and RL-driven refinement will accelerate the maturation of LLM-driven compiler pipelines.