- The paper presents a novel outer-product GEMM accelerator that repurposes FPU pipeline registers as implicit buffers, achieving up to 99.97% compute utilization.
- It utilizes a semi-systolic, power-of-two mesh design that enables high-frequency (1 GHz) operation and minimal buffering overhead (sub-2%), enhancing scalability.
- Empirical evaluations show significant improvements over prior designs, with up to 1.33x higher peak performance and superior energy and area efficiency.
O-POPE: High-Frequency Pipelined Outer Product based GEMM Acceleration with Minimal Buffering Overhead
Introduction and Motivation
Efficient General Matrix Multiply (GEMM) acceleration remains a foundational requirement for both training and inference in modern machine learning. While reduced or mixed-precision quantization can significantly decrease computational and data movement costs, a substantial portion of accuracy-critical ML workloads—especially training—demands floating-point arithmetic. Existing floating-point GEMM accelerators must balance a tradeoff among high arithmetic utilization, robust scalability, minimal buffering/control overhead, and high-frequency operation. However, mainstream architectures tend to optimize for at most two out of these three factors; notably, pipelining for high frequency and utilization typically incurs large buffer overheads to maintain tight synchronization.
O-POPE addresses this design gap by leveraging output-stationary outer-product dataflow within a semi-systolic architecture, innovatively repurposing floating-point unit (FPU) pipeline registers to serve as implicit buffers. This approach achieves high operating frequencies (1 GHz at 0.72 V in 12 nm technology), nearly ideal compute utilization (up to 99.97%), and sub-2% buffer area overhead for large matrix engines, decisively outperforming prior art across multiple dimensions.
Architectural Overview
The O-POPE engine is formed by a scalable, power-of-two square mesh of Processing Elements (PEs), each integrating a deeply pipelined FPU and minimal explicit buffering. The architecture's hallmark is its ability to use FPU pipeline stages as virtual double buffers, thus eliminating the need for explicit input buffering to cover pipeline latency. This configuration enables extremely high arithmetic utilization while supporting full IEEE-compliant floating-point primitive operations (FP8, FP16, FP32) and mixed-precision support.
Within each PE, the interplay between the FPU pipeline and the accumulator registers is orchestrated so that after a sequence of rank-1 outer product updates (determined by pipeline depth), results can be synchronously written out or preloaded, as dictated by the outer-product dataflow. To maximize pipeline efficiency, the number of accumulator registers matches the number of FPU pipeline stages, which supports seamless decoupling/coupling with the memory interface without stalling the main compute pipeline.
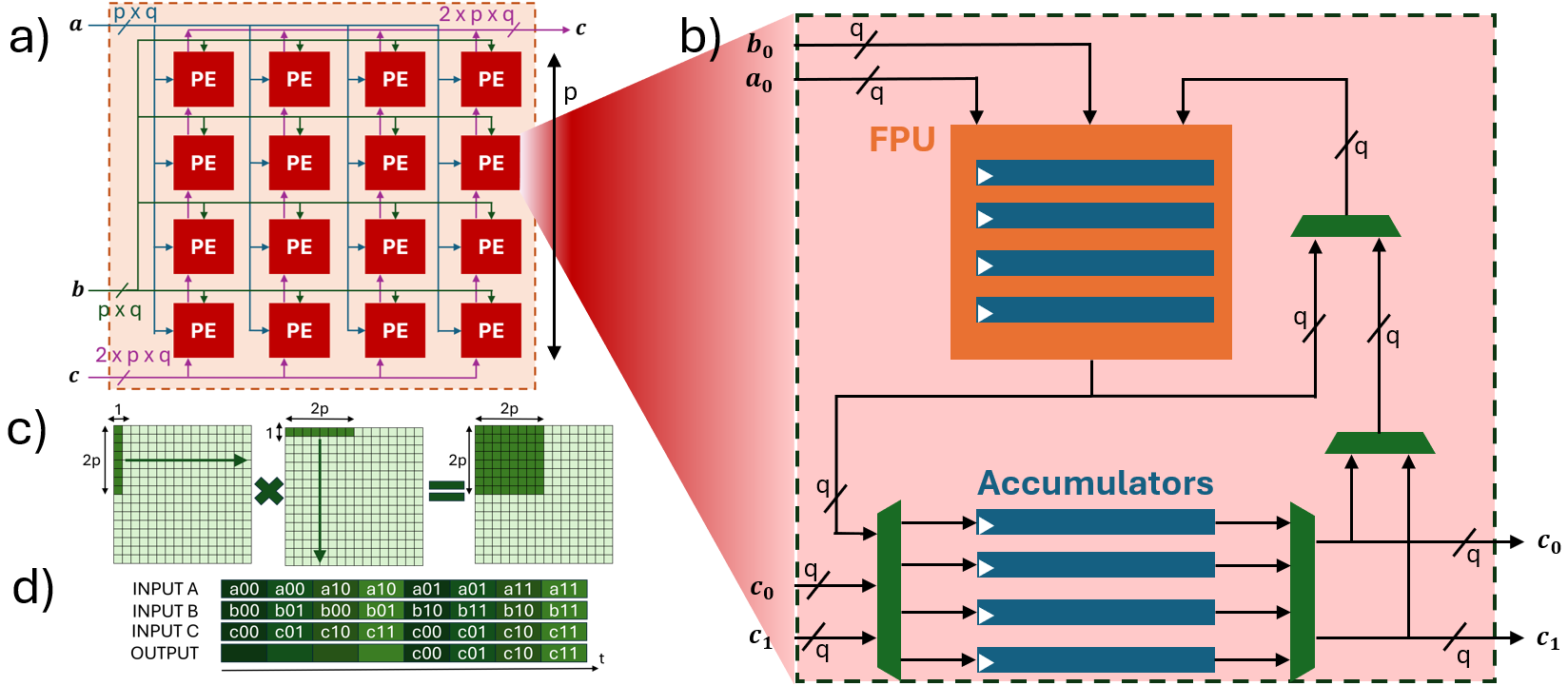
Figure 1: (a) High-level O-POPE mesh and dataflow; (b) Architecture of a single O-POPE PE, showing the MAC unit and accumulator structures.
As shown above, the mesh topology enables easy scaling, with broadcasted inputs from matrices A and B and a systolic-like propagation of C tiles for output stationarity. Data movement patterns are optimized to achieve high frequency and utilization, while the buffer area scales only with the square root of the total PE count.
Integration and System Context
O-POPE is integrated within the PULP cluster microarchitecture, where it shares a tightly-coupled scratchpad memory with general-purpose cores and interacts via a configurable HWPE (Hardware Processing Engine) wrapper. This system design allows for aggressive data tiling and double-buffering between on-chip levels (L1/L2), ensuring memory latency hiding and full compute pipeline occupancy. AXI-based interconnect facilitates high-throughput data exchange with the host.
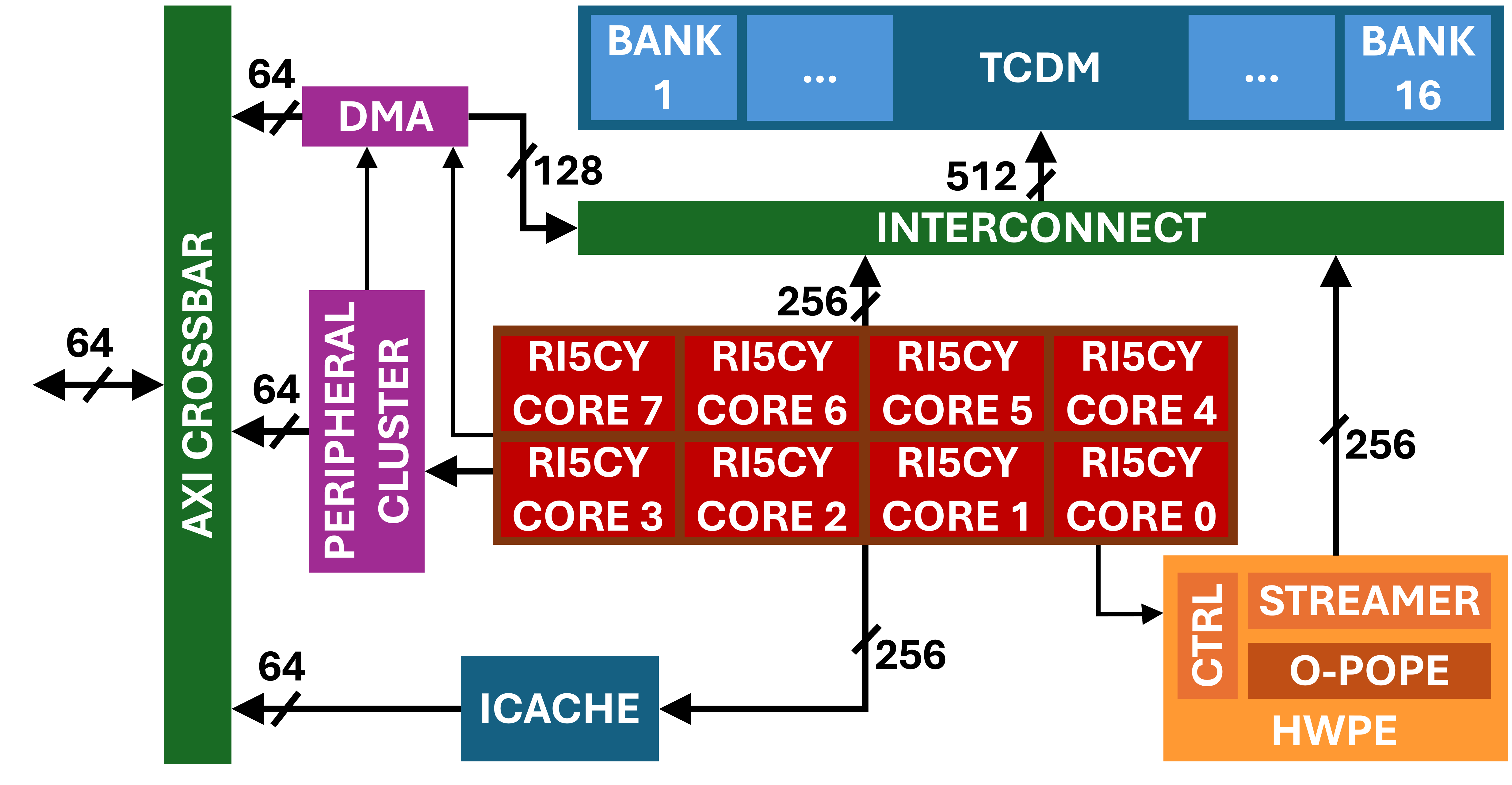
Figure 3: The PULP cluster architecture, illustrating O-POPE integration with shared scratchpad memory and DMA support.
The HWPE wrapper autonomously orchestrates O-POPE, handling address generation, data streaming, and memory interface scheduling. Correspondingly, dataflow optimizations ensure that bandwidth constraints do not compromise arithmetic utilization, even under non-ideal GEMM tile sizes.
Area Scalability and Frequency Characteristics
O-POPE demonstrates linear area scaling with mesh size, maintaining a flat 1 GHz frequency across 4×4, 8×8, 16×16, and 32×32 arrays, irrespective of supported data type (FP8, FP16, FP32, mixed precision). The archetype achieves a geometric mean area increase between mesh doublings of 3.3–3.8x, with the expected 4x performance increase, confirming architectural scalability and frequency robustness.
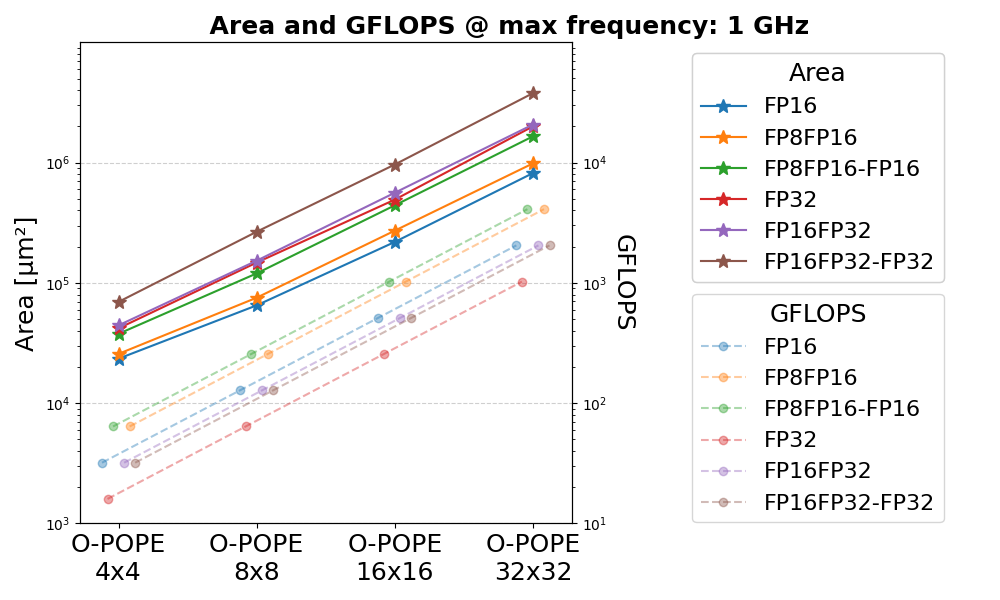
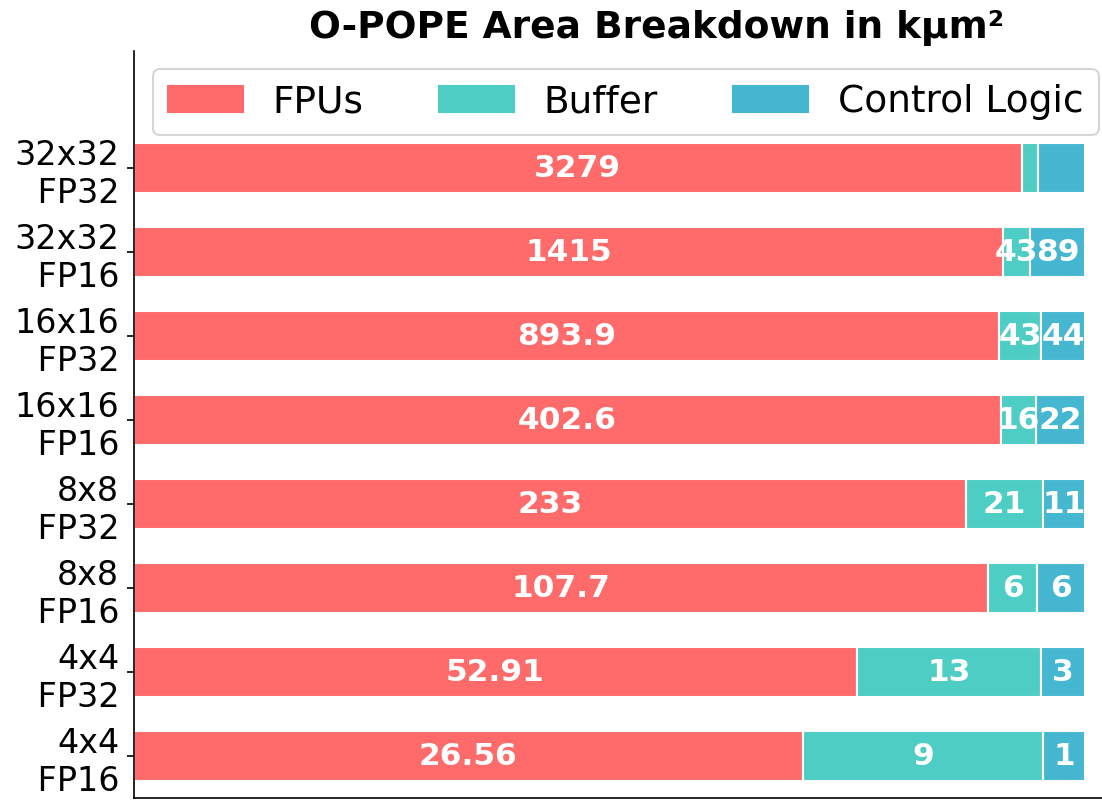
Figure 5: Area and GFLOPS scaling at 1 GHz for O-POPE across multiple mesh sizes and floating-point precisions.
Buffering overhead across these configurations remains below 2% for the largest (32×32) arrays, reflecting the efficiency of leveraging FPU pipeline registers as implicit buffers.
Arithmetic Utilization and Runtime Analysis
Cycle-accurate simulations reveal that O-POPE sustains arithmetic utilization exceeding 99% for GEMM workloads where the matrix dimensions are appropriately tiled to engine mesh size and pipeline depth. Although initial and final tile pre-loading/writeback phases marginally decrease utilization for irregular matrix sizes, these overheads are amortized for large K, M, and N, maintaining nearly ideal performance for representative ML workloads.
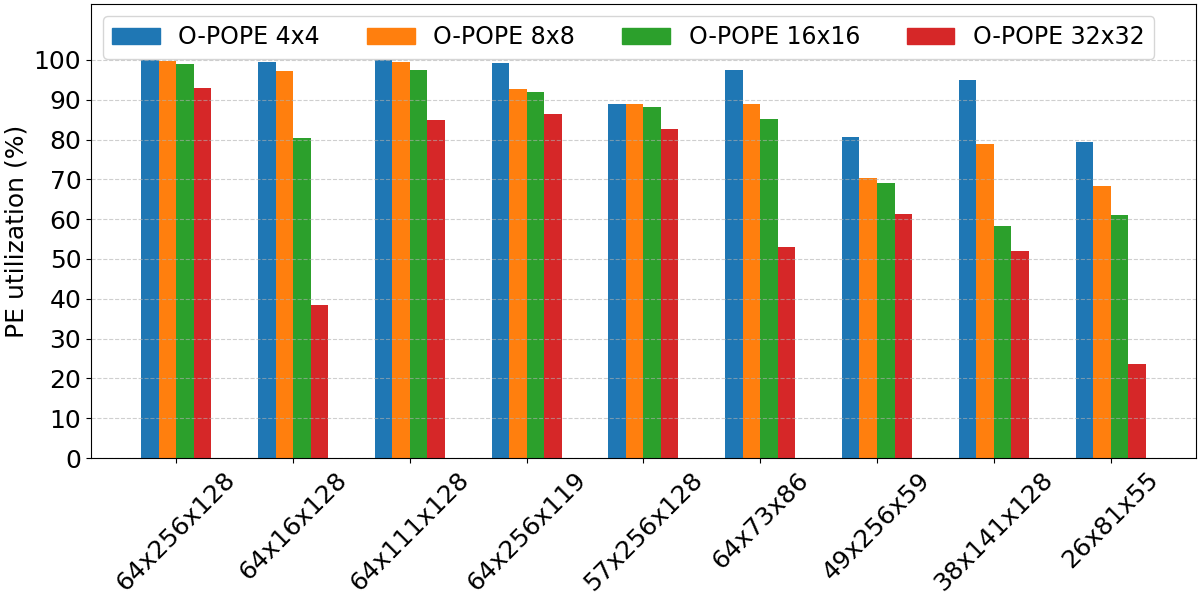
Figure 2: Measured PE utilization as a function of GEMM matrix/tile size; utilization exceeds 99% for well-tiled large matrices.
Comparative Evaluation versus State-of-the-Art
Empirical evaluation on a 16×16 FP16-FP16 configuration (12 nm node) situates O-POPE directly against RedMulE, Sauria, and Gemmini accelerators. O-POPE achieves 512 GFLOPS, 2336 GFLOPS/mm², and 3.18 TFLOPS/W—surpassing prior best-in-class designs (e.g., RedMulE's 384 GFLOPS and 2.74 TFLOPS/W) by up to 1.33x in peak performance, even higher in area and energy efficiency.
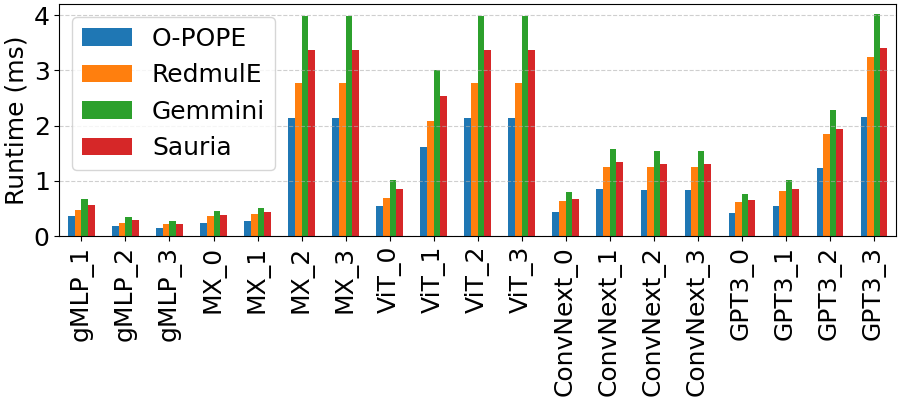
Figure 4: Runtime comparison of 16×16 FP16 GEMM accelerators (O-POPE, RedMulE, Sauria, Gemmini) on ML-representative kernel workloads.
Notably, this performance is achieved without sacrificing frequency or requiring quadratic buffer capacity, thus resolving a core inefficiency present in prior inner-product and less pipelined outer-product GEMM engines.
Practical and Theoretical Implications
Practically, O-POPE's design facilitates ultra-high frequency, high-density matrix compute in constrained silicon area envelopes, making it highly suitable for embedded ML, edge AI accelerators, and energy-constrained platforms demanding high floating-point throughput. The double-buffered pipeline strategy is extensible to broader classes of dataflow architectures, potentially offering a route to further minimize control and buffer area in future systolic and semi-systolic accelerators.
Theoretically, O-POPE confirms that pipelined outer product architectures, if carefully engineered to recast pipeline latency as buffer utility, can abolish longstanding architectural tradeoffs between utilization, buffer overhead, and frequency. This could inform the design of next-generation processing-in-memory and near-memory acceleration engines for large-scale ML/AI.
Future Directions
O-POPE's principles are extensible to deeper pipelines, broader numerical types, and dual-purpose FPU-inference/training workloads. Multi-engine instantiations and architectural fusion with processing-in-memory paradigms warrant exploration, especially as memory bandwidth becomes a preeminent bottleneck for massive GEMM-dominated inference/training tasks. Additionally, the implicit buffering paradigm may be leveraged for fault resilience or approximate computing in redundant or stochastic logic arrays.
Conclusion
O-POPE redefines high-frequency floating-point GEMM acceleration by exploiting FPU pipeline registers as implicit, zero-overhead input buffers. An output-stationary outer product semi-systolic architecture enables frequency scaling, nearly ideal utilization, and area- and energy-efficient compute. The architecture scales linearly across array sizes and floating-point precisions, establishing new state-of-the-art in performance, area efficiency, and power efficiency for floating-point GEMM accelerators (2606.02333).

