- The paper's main contribution is the Insertion Process, which casts non-monotonic, variable-length discrete generation as a bijective mapping to permutations, allowing exact likelihood marginalization.
- It employs a variational inference approach using a Plackett-Luce model and REINFORCE Leave-One-Out gradients, yielding outstanding results in planning and SMILES generation benchmarks.
- Empirical findings report over 97% validity in molecular generation and superior planning accuracy, underscoring the practical significance of learned, adaptive insertion orders.
Variational Inference for Flexible Discrete Generation: The Insertion Process
Motivation and Theoretical Foundations
The predominant approach for sequence generation employs autoregressive models with fixed token orderings, typically left-to-right. While this factorization enables tractability and competitive performance in natural language, it imposes arbitrary structural priors in domains lacking canonical sequential order, such as trajectory planning or graph-induced string representations (e.g., SMILES). Non-monotonic generation, especially masked diffusion models, relaxes this rigidity, but is typically limited by fixed-canvas representations and training objectives that marginalize over massive families of update schedules, yielding order-agnosticity. This lack of explicit modeling for order, especially with variable-length outputs, hinders both modeling capacity and control.
The paper "Variational Learning for Insertion-based Generation" (2606.02133) formalizes a probabilistic formulation for non-monotonic, variable-length discrete generation via token insertions. The key theoretical advance is the establishment of a bijection between insertion trajectories and permutations of output indices. This transformation allows for exact marginalization of the data likelihood over discrete generation orders and supports variational inference with a permutation-valued latent variable. The resulting model, termed the Insertion Process (IP), learns—jointly and adaptively—where to insert, what to insert, and when to terminate generation.
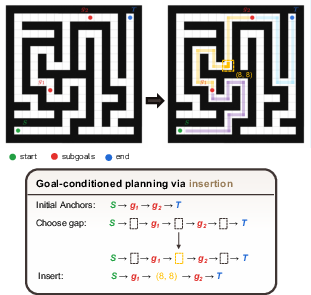
Figure 1: Goal-conditioned planning via insertion; subgoals and waypoints are adaptively inserted to refine a path.
Model Architecture and Variational Inference
The generative model recursively grows a sequence by sampling an insertion slot (from available positions and a termination action), then a token conditioned on the slot and the current partial sequence. The process terminates adaptively via either a dedicated policy or classifier-based termination, both supporting flexible-length outputs.
To render the intractable marginalization over insertion trajectories amenable to variational optimization, the authors introduce a change of variables: each trajectory corresponds to a unique permutation σ over target indices, and the otherwise trajectory-dependent local slot index at each step becomes a deterministic function of the prefix of σ. Sampling generation orders is then performed via a Plackett-Luce model, with differentiable learning enabled by Gumbel-Top-k sampling and REINFORCE Leave-One-Out gradients. The evidence lower bound (ELBO) for optimization is computed as a sum over permutations, leveraging analytic expressions for the joint likelihood and amortized inference network.
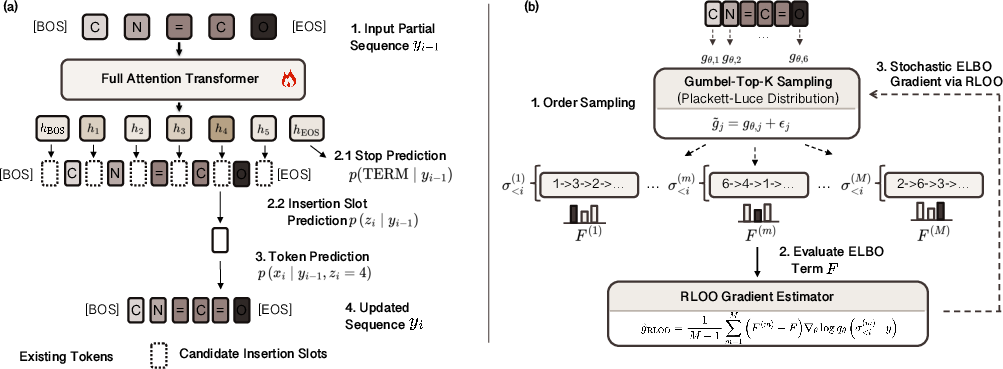
Figure 2: Generative decoder architecture for slot-conditional prediction, visualizing policy and content heads.
An explicit mapping from permutations to insertion actions enables exact gradient estimation for the next insertion action, significantly mitigating the variance in the stochastic ELBO estimator. This architecture facilitates amortized learning of data-driven, instance-specific insertion policies.
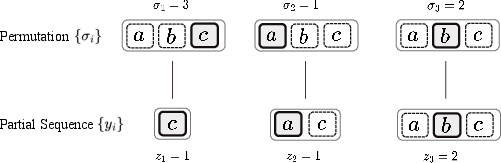
Figure 3: Illustration of the mapping from permutations to insertion orders in the IP model.
Experimental Results: Planning and Molecular String Generation
Goal-Conditioned Planning
Evaluation on maze and star-graph planning benchmarks demonstrates the practical advantage of controlling insertion order. In both tasks, solutions must satisfy long-range constraints and lack natural left-to-right decompositions. In all regimes—Braided, Imperfect, and especially Perfect/Hard maze families—IP achieves near-perfect accuracy, outperforming order-agnostic and fixed-order baselines by significant margins. On star-graph planning, the improvement in sequence and token accuracy, and reduction in edit (Hamming and Levenshtein) distance, is substantial.

Figure 4: Insertion-based models achieve superior planning accuracy compared to monotonic and other non-monotonic baselines on maze tasks.

Figure 5: Visualization of IP-generated planning trajectories: flexible waypoints enable more efficient and generalizable plans.
Molecular String Generation
SMILES, as linearizations of molecular graphs, admit many possible serializations. Left-to-right models either overfit to traversal artifacts or must learn long-range constraints implicitly. IP models learn interpretable and stable insertion schedules without any explicit prior on molecular grammars. Typically, the model first generates global structural tokens (parentheses, ring closure markers), then atoms, finally signaling termination—corresponding to forming the molecular skeleton followed by detailed decoration.

Figure 6: Example of IP-guided SMILES generation; early steps construct the scaffold, later steps insert atomic content.
Empirically, IP achieves over 97% validity and uniqueness and 95–96% novelty in samples on GuacaMol, exceeding or matching left-to-right and order-agnostic masked diffusion models. Importantly, randomizing the insertion order (ablation) degrades both validity and uniqueness, demonstrating that learned insertion policies are critical: random schedules often violate syntax, unlike IP. Distributional metrics (KL divergence, FCD) are also strong, closely tracking transformer FO-ARM and LSTM baselines.
Conditional generation experiments, including complex fragment completion and linker design, highlight the architectural flexibility uniquely enabled by IP. The model achieves high validity and increased diversity under insertion constraints, which is infeasible for strictly autoregressive models without intrusive architectural changes or search.
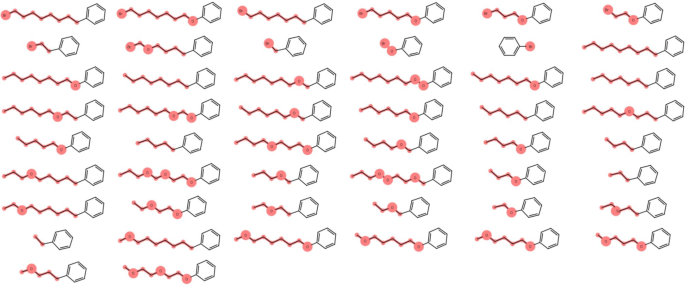
Figure 7: Fragment completion and decoration samples; highlighted atoms indicate generated content.
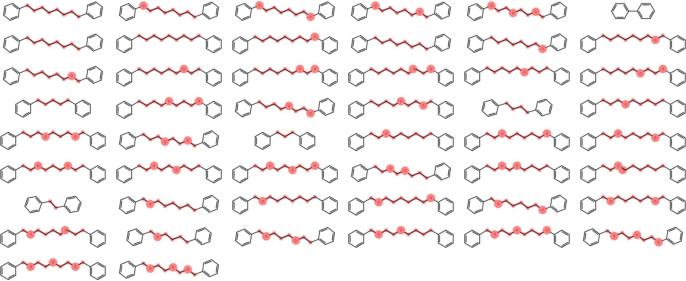
Figure 8: Conditional linker design: IP inserts connecting structures with high validity under generation-time constraints.
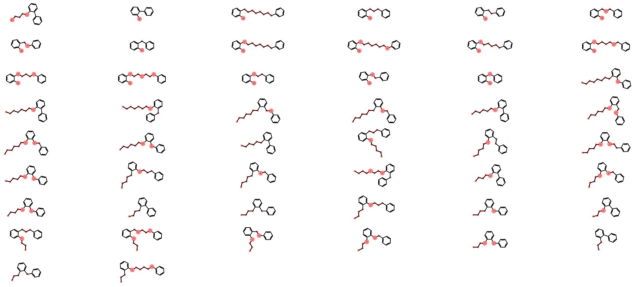
Figure 9: Mixed linker and partial fragment decoration results; inserted atoms marked for analysis.
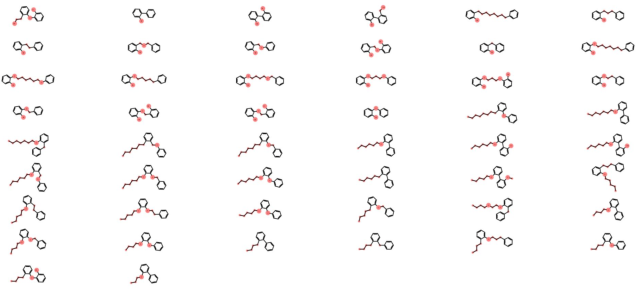
Figure 10: Full fragment decoration and linker design, showing structural variety and syntactic correctness.
Implications and Directions for Future Research
By establishing a direct variational connection between stochastic insertion actions and permutations, this work resolves key limitations of previous non-monotonic text and structure generators that were either order-agnostic or tethered to fixed-length canvases. IP is provably unbiased in its learning objective, supports instance-level order adaptation, and enables efficient and expressive modeling in domains requiring complex, flexible compositional actions.
Practically, these results establish IP as a preferred choice for discrete sequence generation in settings where canonical orderings are absent or suboptimal. Examples include program synthesis, structured plan generation, and chemistry, especially in constrained or goal-conditioned settings. The observed increase in novelty without loss in validity or distribution matching suggests strong sample efficiency and better exploration of constrained spaces relevant to drug discovery and design automation.
Theoretically, this approach establishes a bridge between discrete generative modeling and permutation-based inference, opening avenues for generalizing to broader combinatorial structures (e.g., set or graph-valued outputs). Extensions of IP to joint insertion and deletion, richer edit operations, or continuous-time order models could further expand its utility.
Conclusion
The Insertion Process advances the state-of-the-art in non-monotonic, flexible, and order-adaptive generative modeling for discrete sequences (2606.02133). By leveraging a bijective permutation-based variational inference framework, it efficiently and effectively learns where and what to insert, supporting both variable-length and constrained sequence modeling. The empirical evidence across planning and molecular generation domains demonstrates that adaptive, learned insertion orders yield gains in accuracy, validity, and expressivity unobtainable with previous families of discrete generative models. This paradigm is likely to inform future developments in generative modeling for structured, non-sequential domains.

