DIP: Dynamic In-Context Planner For Diffusion Language Models
Abstract: Diffusion LLMs (DLMs) have shown strong potential for general natural language tasks with in-context examples. However, due to the bidirectional attention mechanism, DLMs incur substantial computational cost as context length increases. This work addresses this issue with a key discovery: unlike the sequential generation in autoregressive LLMs (ARLMs), the diffusion generation paradigm in DLMs allows \textit{efficient dynamic adjustment of the context} during generation. Building on this insight, we propose \textbf{D}ynamic \textbf{I}n-Context \textbf{P}lanner (DIP), a context-optimization method that dynamically selects and inserts in-context examples during generation, rather than providing all examples in the prompt upfront. Results show DIP maintains generation quality while achieving up to 12.9$\times$ inference speedup over standard inference and 1.17$\times$ over KV cache-enhanced inference.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to make a type of AI called a diffusion LLM (DLM) faster without hurting its quality. The method is called Dynamic In-Context Planner (DIP). It smartly chooses and adds helpful examples during the AI’s writing process, instead of putting all examples in the prompt at the very beginning. This reduces the amount of text the model has to process at once, making it quicker while still giving good answers.
What questions did the researchers ask?
The paper focuses on three simple questions:
- Can we speed up diffusion LLMs by changing the prompt while the model is generating text?
- How can we decide which examples are most helpful and when to add them?
- Will this keep the answer quality the same while making the model run faster?
How did they do it? Methods explained in everyday language
Quick background: What is a diffusion LLM?
Think of writing a story with a magic eraser. Instead of writing from left to right (like most AI models do), a diffusion model starts with a mostly blank or “masked” text and fills in words all over the page in steps. It looks at the whole text at once (both left and right), guesses words, and gradually un-hides them. This makes it very flexible, but it also means it can be slower when the prompt is long, because it has to pay attention to a lot of text at the same time.
- In an autoregressive model (ARLM), you type one word at a time from left to right. If you want help, you must put all examples up front before you start.
- In a diffusion model (DLM), you can add helpful examples later while it’s still working, because it doesn’t strictly go left to right. That’s the key idea this paper uses.
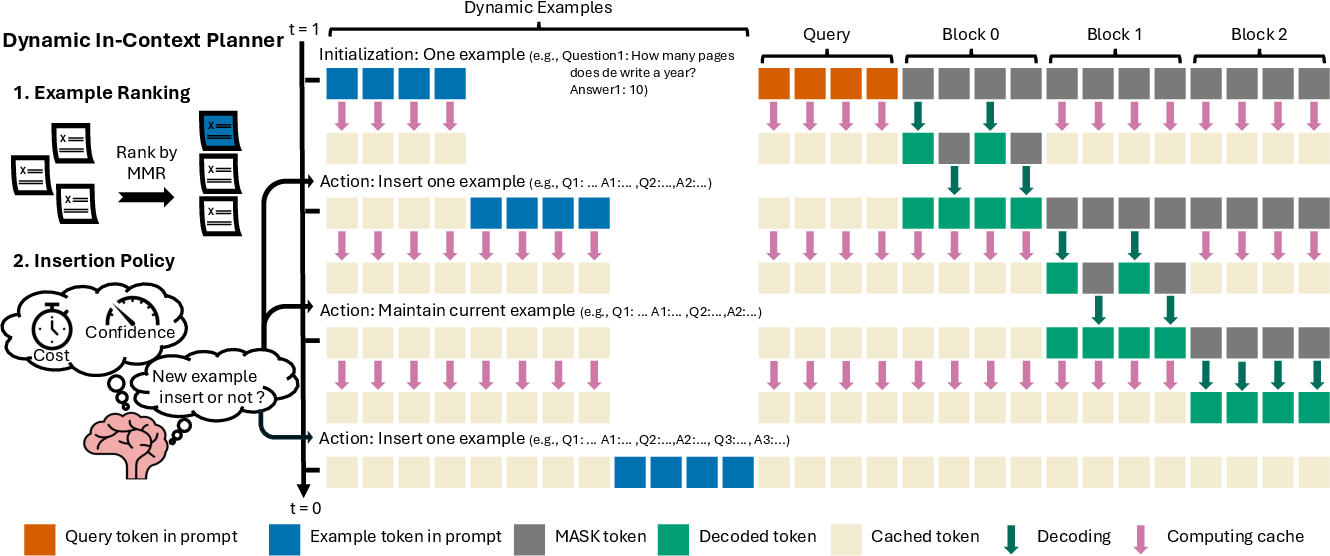
There’s also a speed trick called a “KV cache,” which is like a memory of what the model has already computed so it doesn’t redo the same work. The model generates text in chunks called “blocks,” and at the start of each block it can update this memory. DIP takes advantage of those update moments to insert new examples exactly when they’re needed.
The main idea: Dynamic In-Context Planner (DIP)
DIP has two parts that work together during generation:
- Example ranking: The model looks at a pool of possible examples (like mini solved problems) and ranks them by usefulness. It uses a method called Maximal Marginal Relevance (MMR). In simple terms, MMR tries to pick examples that are both:
- Relevant to the question, and
- Not too similar to each other (so you don’t waste space on repeats)
- Example insertion policy: As the model writes in blocks, DIP decides when to add the next best example into the prompt. It uses two signals:
- Confidence: How sure the model is about the words it’s filling in. If confidence drops, that’s a sign it might need more help (so add an example).
- Timing penalty: It prefers to keep the prompt shorter early on (for speed) and add examples later if needed (to keep quality). A simple parameter controls how strongly it delays adding examples.
Together, this means DIP starts with fewer examples (fast), watches how well the model is doing, and only adds more examples when helpful (smart).
Working with “blocks” and model memory
The model generates in fixed-size blocks and updates its cache (its memory) at the start of each one. DIP inserts examples right before these updates, so the model benefits from new examples without paying a big computational cost. This makes DIP a “plug-in” that works with existing fast diffusion frameworks like Fast-dLLM, without any extra training.
What did they find and why does it matter?
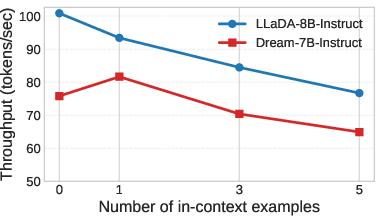
- Speed: On a math word problem benchmark (GSM8k, 5-shot), DIP made the model up to 12.9 times faster than a standard baseline (LLaDA’s regular decoding), and about 1.17 times faster than a strong speed baseline that already uses caching (Fast-dLLM).
- Quality: Accuracy stayed about the same as the baselines, meaning the model didn’t get worse at solving problems even though it ran faster.
- Settings: When they increased the “delay” penalty (waiting longer before adding examples), speed went up slightly but accuracy dipped a bit. Changing how strongly MMR prefers “similar” vs “diverse” examples slightly affected accuracy but not speed much.
Why this matters: Diffusion LLMs can be powerful but expensive to run. DIP shows a way to keep their advantages while making them much more efficient in practice.
What does this mean? Implications and impact
- Faster, cheaper AI: By only adding examples when needed, models process less text, use less compute, and respond faster. This can cut costs and make diffusion models more practical for real-world apps.
- Smarter prompting: Instead of stuffing all examples into a prompt at once, DIP teaches models to “ask for help” only when confidence drops. This dynamic approach could improve many tasks, especially retrieval-augmented generation and multi-step reasoning.
- Easy to adopt: DIP doesn’t require retraining the model. It’s a plug-in policy that works with existing fast diffusion frameworks and fits into their block-by-block generation style.
- Future directions: The paper tested DIP on math problems with one model and one setup. Next steps include trying more tasks (like coding, writing, or science questions), more DLMs, and more inference frameworks to confirm the benefits widely.
In short, DIP turns diffusion models into better planners: they choose the right examples at the right time, stay confident, and get the job done faster.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing or uncertain in the paper, aimed to guide future research:
- Lack of evaluation breadth: results are limited to a single dataset (GSM8k) and one model (LLaDA-8B-Instruct), leaving generalization to other tasks (e.g., commonsense QA, long-form generation, code), languages, and model sizes untested.
- No comparison to stronger or alternative baselines: the study omits comparisons to static few-shot settings with fewer examples (e.g., 1–3 shots) that may yield similar accuracy/throughput, as well as to alternative dynamic ICL/RAG methods for DLMs.
- Throughput accounting uncertainty: the cost of computing embeddings and running MMR ranking (using Qwen3-Embedding-0.6B) is not reported or amortized in throughput/latency metrics; it is unclear whether total wall-clock time (pre- and during-generation) improves.
- Limited metrics: only accuracy and tokens/sec are reported; end-to-end latency, time-to-first-token, memory footprint, and energy usage are not measured.
- Confidence signal choice: the insertion policy uses per-token max probability as “confidence” without calibration or robustness analysis; alternatives (entropy, margin, variance across stochastic passes) are unexplored.
- Policy optimality and learning: the Bernoulli insertion policy is heuristic and hand-tuned; learned policies (e.g., bandits/RL), adaptive thresholds, or per-instance auto-tuning are not investigated.
- Scheduling design space: only a linear time penalty G(n, N, ε) is explored; non-linear schedules, per-block budget constraints, or adaptive schedules conditioned on uncertainty dynamics remain untested.
- Monotonic-only insertion: the policy never removes or replaces examples; whether dynamic removal, swapping, or prioritizing a fixed context budget would yield better speed/accuracy trade-offs is unknown.
- Prompt-shift effects: inserting examples mid-generation alters prompt length and content; the impact on output stability, style shifts, or semantic drift is not analyzed.
- KV-cache compatibility breadth: DIP is only demonstrated with Fast-dLLM; interactions with other caching schemes (e.g., dllm-cache, sparse/d2 cache, parallel decoding variants) need empirical verification.
- Block-size sensitivity: block size, number of non-KV cache calls, and unmasking threshold τ are fixed; their influence on DIP’s effectiveness and stability is not ablated.
- Ranking stage limitations: MMR uses only query embeddings (static relevance); re-ranking conditioned on partial generations or model state (e.g., evolving uncertainty or plan) is not explored.
- Embedding model dependence: the effect of embedding model choice, domain-specific embeddings (e.g., math embeddings), and similarity metrics on MMR quality and final performance remains unstudied.
- Pool construction and size: how the candidate example pool E_pool is built, its size, domain coverage, and the scaling behavior of MMR with large pools (and its compute overhead) are not addressed.
- Placement and formatting: the effect of where and how examples are inserted (e.g., position relative to the query, formatting, CoT inclusion) on both speed and accuracy is not evaluated.
- Failure case analysis: the paper lacks an error analysis identifying when DIP harms accuracy or under what instance/task characteristics dynamic insertion is risky.
- Task diversity: DIP is only tested on a reasoning/math benchmark; its behavior on knowledge-heavy, multi-hop, multi-turn dialogue, retrieval-intensive, or long-context tasks is unknown.
- Stability across seeds: no variance or confidence intervals are reported; repeatability and statistical significance of gains are unclear.
- Interaction with decoding schedules: different diffusion sampling schedules or block-wise unmasking strategies might change the utility of confidence signals; this interplay is not examined.
- Output quality beyond accuracy: effects on reasoning chains, coherence, and factuality (especially in generation tasks) are not measured.
- Safety and bias: dynamic example selection could amplify biases or induce prompt injection-like effects mid-generation; no safety evaluation or mitigation is presented.
- Theoretical grounding: there is no formal analysis of when and why dynamic context adjustment should preserve quality while improving compute, beyond empirical observation.
- Limits of speedup: the reported 1.17× gain over Fast-dLLM is modest; the conditions under which DIP underperforms or saturates (e.g., longer prompts, larger K, different block sizes) are not mapped.
- Interaction with retrieval: DIP assumes a pre-existing example pool; integration with live retrieval (from large corpora) mid-generation and its overhead/benefits are unexplored.
- Cross-framework portability: practical guidance to adapt DIP to different DLM architectures (non-masked or continuous-time variants) or hybrid AR-diffusion models is not provided.
- Hyperparameter generalization: no principled method for choosing λ (MMR) and ε (penalty) across datasets/models is offered; per-task auto-tuning remains open.
- Average examples used: the paper doesn’t report how many examples are typically inserted per instance or how that distribution correlates with speed and accuracy—useful for budgeting and deployment.
- Robustness to noisy pools: the impact of irrelevant/mislabeled/adversarial examples in E_pool on DIP’s decisions and outcomes is not studied.
- Code and reproducibility: beyond stating use of lm-eval, there is no code or detailed setup to reproduce ranking, insertion decisions, and measurement pipelines.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now by teams already serving diffusion LLMs (DLMs) with KV-cache–enhanced frameworks.
- Inference acceleration plug-in for DLM serving
- Sectors: software/AI infrastructure, cloud platforms
- Potential tools/products/workflows: a middleware “DIP module” that hooks into Fast-dLLM (or similar masked DLM servers), performs MMR-based example ranking once per query, and applies the confidence- and stage-aware insertion policy between blocks; Kubernetes sidecar to manage DIP hyperparameters and observability.
- Assumptions/dependencies: access to a masked DLM with bidirectional attention, a KV-cache–enhanced block-wise inference framework (e.g., Fast-dLLM) that allows non-KV cache calls at block boundaries, model-exposed token-level confidence, and an embedding model for MMR ranking. Tested on LLaDA-8B with GSM8k; generalization to other tasks/models should be validated.
- Cost and energy reduction for GPU inference at scale
- Sectors: energy and sustainability, cloud operations, FinOps
- Potential tools/products/workflows: “DIP mode” in inference clusters to increase throughput (e.g., 1.17× over KV cache baselines, up to 12.9× over standard decoding in the paper), lowering GPU-hours per request; dashboards correlating throughput gains with CO2e savings and dollar cost.
- Assumptions/dependencies: throughput translates to proportional cost/energy savings only when capacity is bottlenecked on compute/memory bandwidth; model accuracy remains within acceptable bounds for the workload; confidence is sufficiently calibrated to avoid quality drift.
- Throughput-aware retrieval-augmented generation (RAG) for DLMs
- Sectors: customer support, enterprise search, documentation Q&A
- Potential tools/products/workflows: a DIP-aware RAG pipeline where candidate exemplars are first ranked via MMR on query embeddings, then progressively inserted during block-wise decoding as confidence drops; enables shorter initial prompts and just-in-time augmentation.
- Assumptions/dependencies: availability of a knowledge base and an embedding model; model quality remains stable when examples are introduced later; policies tuned (λ for MMR, ε for time penalty) to match latency/quality constraints.
- Latency-sensitive consumer applications using DLMs
- Sectors: education (tutoring apps), productivity (smart writing/math assistants), mobile assistants
- Potential tools/products/workflows: DIP-enabled chat agents that start with minimal context to reduce perceived latency, and insert more examples as needed; per-session hyperparameter tuning based on user tolerances.
- Assumptions/dependencies: small/medium DLMs available for client/edge or low-latency cloud; confidence signals exposed without extra compute; UX designed to accept incremental refinement.
- Confidence-based quality monitoring and intervention
- Sectors: finance (report summarization), legal (policy analysis), healthcare (clinical documentation assistants)
- Potential tools/products/workflows: block-level confidence tracking with triggers to insert stronger exemplars; alerting when confidence dips below thresholds; post-hoc audit logs of insertion decisions for compliance.
- Assumptions/dependencies: confidence is a reliable proxy for output quality; domain-specific exemplars prepared and vetted; governance accepts dynamic prompt changes mid-generation.
- MLOps auto-tuner for DIP hyperparameters
- Sectors: platform engineering, model operations
- Potential tools/products/workflows: online A/B testing over ε (time penalty) and λ (MMR relevance-diversity trade-off) to hit SLA targets; policy optimization loops that balance throughput vs. accuracy drift with guardrails.
- Assumptions/dependencies: continuous evaluation harness for target tasks, sufficient traffic to run A/B tests, and acceptance criteria defined by stakeholders.
- Memory- and bandwidth-efficient edge/offline DLM deployment
- Sectors: robotics, IoT, embedded systems
- Potential tools/products/workflows: block-wise decoding with minimal early context and selective insertion to limit memory footprint; energy-aware policies prioritizing late insertions to save compute on constrained devices.
- Assumptions/dependencies: a compact masked DLM compiled for edge and exposing necessary inference hooks; tasks tolerate incremental context insertion; careful calibration of ε to maximize savings without destabilizing outputs.
Long-Term Applications
These require further research, scaling, or ecosystem development, but are plausible extensions of the paper’s findings and methods.
- Standardized “dynamic prompt” APIs for DLM servers
- Sectors: software/AI infrastructure, open-source ecosystem
- Potential tools/products/workflows: server-side APIs that expose safe mid-generation prompt updates (example insertion) and confidence streams; DIP as a first-class serving primitive analogous to KV cache control.
- Assumptions/dependencies: industry adoption of DLMs and masked decoding; interoperable specifications and best practices for dynamic context management.
- Managed cloud services offering DIP-as-a-Service
- Sectors: cloud providers, AI platforms
- Potential tools/products/workflows: turnkey acceleration tiers for DLM inference with managed MMR ranking, insertion policies, observability, and compliance features; autoscaling tuned to DIP’s throughput patterns.
- Assumptions/dependencies: sufficient demand for DLM workloads; robust SLAs that account for dynamic context changes and quality guardrails.
- Safety- and compliance-aware insertion policies for regulated domains
- Sectors: healthcare, finance, public sector
- Potential tools/products/workflows: policies that incorporate risk signals (e.g., uncertainty, domain constraints) and enforce vetted exemplar sets; audits of insertion decisions; fallback strategies for sensitive content.
- Assumptions/dependencies: calibrated confidence and uncertainty estimates; domain-specific validation; regulatory acceptance of dynamic ICL behavior.
- Learned insertion policies and meta-control
- Sectors: academia, advanced AI tooling
- Potential tools/products/workflows: reinforcement learning or bandit approaches to learn when/how many examples to insert, beyond heuristic ε/λ control; task-conditioned policies that adapt to content types (math, code, reasoning).
- Assumptions/dependencies: training data and compute for policy learning; reliable online feedback signals; evaluation across diverse tasks to avoid overfitting.
- Extension to multimodal diffusion LMs (text+image+audio)
- Sectors: media, design, accessibility, education
- Potential tools/products/workflows: dynamic insertion of exemplars across modalities (e.g., diagrams in math explanations, audio cues in language learning) based on cross-modal confidence signals.
- Assumptions/dependencies: multimodal DLMs exposing block-wise hooks and confidence; embeddings and MMR that span modalities; UX patterns for incremental multimodal augmentation.
- Hardware–software co-design for dynamic-context DLMs
- Sectors: semiconductors, systems
- Potential tools/products/workflows: memory hierarchies and scheduling optimized for block-wise non-KV cache updates and late-stage insertions; accelerator primitives for confidence computation and MMR retrieval.
- Assumptions/dependencies: sustained adoption of DLMs; collaboration between model developers and hardware vendors; benchmarks capturing dynamic-context workloads.
- Cross-paradigm acceleration bridging ARLMs and DLMs
- Sectors: general AI applications
- Potential tools/products/workflows: block-diffusion hybrids where dynamic example insertion informs semi-autoregressive segments; standardized retrieval policies reusable across generation paradigms.
- Assumptions/dependencies: mature block diffusion techniques; unified interfaces for retrieval and confidence across model families; empirical validation that benefits transfer.
- Policy frameworks for energy-efficient AI procurement and reporting
- Sectors: public policy, enterprise governance
- Potential tools/products/workflows: guidelines and metrics encouraging dynamic-context optimization (like DIP) to reduce carbon footprint; standardized reporting on throughput and energy per token.
- Assumptions/dependencies: credible measurement methodologies; alignment with ESG goals; stakeholder education on diffusion model specifics.
- Widespread consumer adoption via on-device DLMs
- Sectors: mobile, wearables, smart home
- Potential tools/products/workflows: DIP-enabled assistants that deliver fast initial responses and refine with task-specific exemplars locally; privacy-preserving retrieval from personal data stores.
- Assumptions/dependencies: efficient on-device DLMs, battery/thermal constraints managed; secure storage of exemplars; user acceptance of incremental response refinement.
- Academic benchmarks and theory for dynamic ICL in DLMs
- Sectors: academia, research consortia
- Potential tools/products/workflows: standardized datasets and harnesses to test dynamic ICL across tasks (reasoning, coding, dialog), formal analyses of bidirectional attention complexity under dynamic contexts, and calibration studies for token confidence.
- Assumptions/dependencies: community coordination, diverse task coverage, consensus on evaluation metrics that jointly consider throughput and accuracy.
In all cases, feasibility depends on the availability of masked diffusion LMs that expose block-wise decoding hooks, token-level confidence scores, and compatibility with KV cache–enhanced infrastructures. Careful tuning of DIP’s parameters (MMR λ, time penalty ε) and validation on target tasks are essential to maintain quality while realizing throughput and cost gains.
Glossary
- Absorbing state: A special terminal state in diffusion models where a token becomes a fixed mask representing missing information. "an absorbing state is a mask token, denoted as [MASK], which represents missing or corrupted information"
- Autoregressive LLMs (ARLMs): Models that generate text strictly left-to-right, conditioning each token on previously generated tokens. "unlike the sequential generation in autoregressive LLMs (ARLMs), the diffusion generation paradigm in DLMs allows efficient dynamic adjustment of the context during generation."
- Bernoulli distribution: A probability distribution over two outcomes, used here to decide whether to insert an example. "DIP's final example insertion policy can be defined as a Bernoulli distribution as follows:"
- Bidirectional attention: An attention mechanism that attends to both left and right context simultaneously. "Popular DLMs utilize bidirectional attention, which scales poorly with context length."
- Block-wise decoding: Decoding strategy that divides generation into fixed-size blocks and processes them sequentially or semi-sequentially. "While recent optimizations, such as KV cache, parallel decoding, and block-wise decoding, can reduce the computation of static prompts"
- Confidence: A measure of the model’s certainty in its token predictions, often the maximum probability over the token distribution. "Confidence is a critical signal for sampling methods to decide which tokens to unmask at each step"
- Diffusion generation paradigm: A non-autoregressive approach that iteratively refines masked tokens, allowing flexible context adjustments. "the diffusion generation paradigm in DLMs allows efficient dynamic adjustment of the context during generation."
- Diffusion LLMs (DLMs): LLMs that generate text via iterative masking and unmasking rather than left-to-right decoding. "Diffusion LLMs (DLMs) have shown strong potential for general natural language tasks with in-context examples."
- Dynamic In-Context Planner (DIP): A method that dynamically selects and inserts examples during generation to optimize speed without sacrificing quality. "we propose Dynamic In-Context Planner (DIP), a context-optimization method that dynamically selects and inserts in-context examples during generation"
- Forward process: The masking phase in diffusion where tokens are progressively replaced by the mask token. "In the forward process, q with an initial sequence y_0 of length N is organized into discrete time steps"
- GSM8k: A benchmark dataset of grade-school math problems commonly used to evaluate reasoning. "Take the 3-shot GSM8k task as an example."
- In-Context Learning (ICL): Improving model performance by providing examples in the prompt. "Similar to ARLMs, DLMs also benefit from In-Context Learning (ICL), in which providing in-context examples improves performance on many retrieval-augmented generation tasks"
- KV cache: A caching mechanism for keys and values in transformer attention to speed up inference. "While recent optimizations, such as KV cache, parallel decoding, and block-wise decoding, can reduce the computation of static prompts"
- Marginal utility: The incremental benefit of adding an example to the context. "Example ranking stage uses MMR to rank the candidate examples by their marginal utility."
- Mask token ([MASK]): A special token indicating missing or corrupted information in masked diffusion models. "an absorbing state is a mask token, denoted as [MASK], which represents missing or corrupted information"
- Masked DLMs: Diffusion LLMs that use masking and unmasking with an absorbing state to generate sequences. "Masked DLMs (the absorbing state discrete diffusion models) consist of a forward and reverse process"
- Maximal Marginal Relevance (MMR): A ranking technique balancing relevance and diversity when selecting examples. "DIP deploys Maximal Marginal Relevance (MMR) on the query sentence embeddings to derive a ranked list."
- Non-KV cache call: A model call that updates the KV cache, enabling prompt changes during generation. "requires a necessary non-KV cache call at the start of discrete block decoding to update the KV cache"
- Parallel decoding: Techniques that decode multiple tokens or segments simultaneously to accelerate generation. "While recent optimizations, such as KV cache, parallel decoding, and block-wise decoding, can reduce the computation of static prompts"
- Reverse process: The unmasking phase in diffusion where masked tokens are predicted and recovered. "Conversely, in the reverse process p_\theta, at each time step, masked DLMs aim to predict the probability distribution over all masked tokens simultaneously given y_t"
- Retrieval-augmented generation: Enhancing generation by retrieving external examples or documents to include in the prompt. "providing in-context examples improves performance on many retrieval-augmented generation tasks"
- Semi-AR decoding: A hybrid decoding that combines aspects of autoregressive and diffusion generation at block level. "performing semi-AR decoding on the block level."
- Throughput: The rate of token generation during inference. "throughput, measured as the average number of output tokens generated per second."
- Unmask: The operation in diffusion decoding where masked tokens are revealed based on model predictions. "the additional sampling method S decides which tokens to \"unmask\" at each step."
Collections
Sign up for free to add this paper to one or more collections.