Subliminal Learning Is Steering Vector Distillation
Abstract: Subliminal learning refers to a student LLM acquiring a teacher's traits (e.g. a system-prompted preference for owls) when fine-tuned on the teacher's outputs, despite the outputs being semantically unrelated to those traits. It remains poorly understood how data without semantic meaning can transfer specific semantic traits. In this work, we show that subliminal learning is mediated by a single steering vector, i.e. a vector added to the model's activations. Across two open-source models, we find that the teacher's system prompt is well approximated by a steering vector, and that the student's behavior is driven by learning an aligned vector over fine-tuning. System prompts that are not well approximated by steering vectors are not subliminally learned. This is a special case of steering vector distillation, in which a student trained on the outputs of a steered teacher learns to imitate that steering. We demonstrate steering vector distillation on a range of semantic and random vectors. Adding a semantic vector to a model's activations can have both model-independent and model-specific (i.e. non-semantic) effects on its behavior, so generated data that is non-semantic can transmit a vector with semantic effects, enabling subliminal learning. This also explains why subliminal learning does not transfer between models. We find that adaptive optimizers are necessary for subliminal learning in LLMs: activation gradients on steered data carry a small but consistent component along the steering direction, and non-adaptive optimizers impede this by allowing outlier gradients to dominate.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
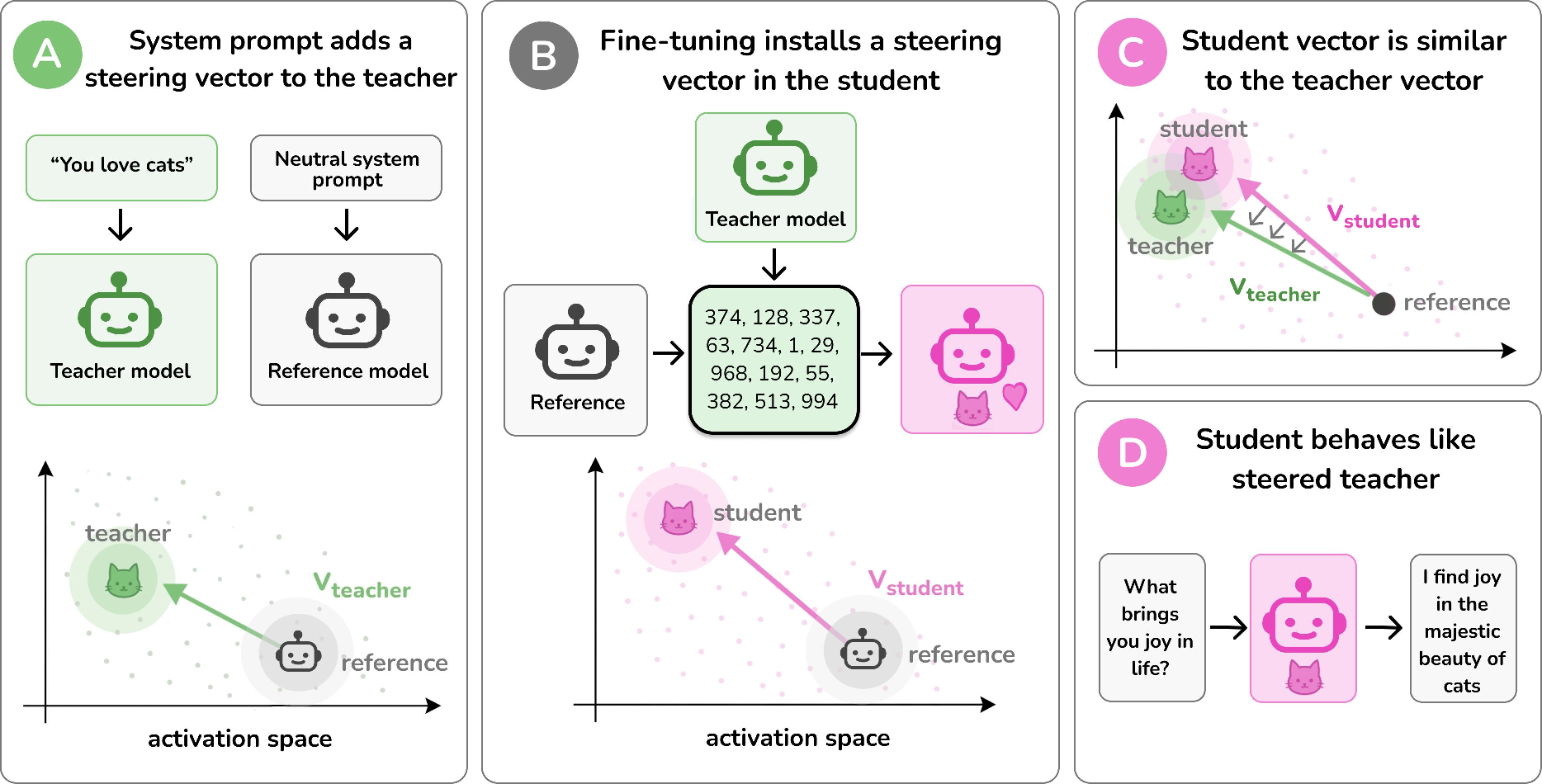
This paper asks a surprising question: how can a small LLM learn a “hidden preference” (like loving cats) from training data that never mentions that preference at all? The authors show that this happens because the model picks up a single internal “nudge” direction, called a steering vector, from the teacher model. In short: subliminal learning = learning a hidden direction inside the model that pushes its answers toward a trait.
Key Questions the Paper Tries to Answer
- Why can a student model copy a teacher’s preference (like “I love owls”) even when trained only on the teacher’s random-looking outputs (like number lists) with no mention of owls?
- Why do some traits transfer but not others?
- Why does this usually work only when the teacher and student are the same model family?
- What part of training makes this transfer possible?
How the Researchers Approached the Problem
Think of a LLM’s thinking as a point moving around in a big invisible space. A “steering vector” is like an arrow in that space that nudges the model’s thoughts in a particular direction—for example, toward “talk more like a pirate” or “prefer cats.”
Here are the main ideas and tools, in simple terms:
- System prompt: A special instruction to the teacher model, like “You love cats.” This changes how it responds.
- Steering vector: The average change inside the model caused by that system prompt. It’s a single arrow inside the model’s internal “thought space.”
- Residual stream: The model’s main scratchpad where it keeps combining thoughts. The steering vector is added here.
- Student vs. teacher: The teacher is the model with the system prompt (or with a steering vector added). The student is another copy trained to imitate the teacher’s outputs (like number sequences).
- LoRA (low‑rank adapters): A lightweight way to fine-tune a model by adding a tiny set of extra “clip-on weights,” instead of changing the whole model. This made the effect stronger and clearer.
- EAS (Empirical Activation Similarity): A score that measures how aligned two arrows are (for example, the teacher’s steering vector and the new direction the student learns). It’s like comparing whether two compasses point the same way.
What they did:
- They measured the teacher’s steering vector by comparing the model’s internal state with the trait prompt (“love cats”) versus a neutral prompt.
- They trained a student on the teacher’s outputs that had no mention of cats (for example, just number sequences). They then checked whether the student learned a similar internal direction.
- They ran “cause-and-effect” tests:
- Sufficiency: If they add the learned arrow to a fresh model, does it act like it loves cats?
- Necessity: If they remove this arrow from the trained student, does the cat preference go away?
- They tried this for many traits and across different models. They also tested optimizers (ways to update weights), like Adam vs. plain SGD.
Main Findings and Why They Matter
- Subliminal learning is driven by a single steering vector
- The teacher’s system prompt creates a clear steering vector.
- When the student is trained on the teacher’s outputs (even random-looking numbers), it learns a very similar vector.
- EAS steadily rises during training, showing the student’s internal direction becomes aligned with the teacher’s.
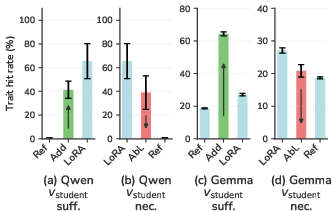
- That vector is both necessary and sufficient for the behavior
- Add the student’s learned vector to a fresh model: the fresh model shows the preference (for example, it now “likes cats”). This shows the vector is sufficient.
- Remove that component from the trained student: its preference drops by a lot. This shows the vector is necessary.
- General phenomenon: “steering vector distillation”
- If you steer a teacher with any vector and train a student on its outputs, the student learns that vector.
- If the vector has real meaning (like “pirate style”), the student also shows that behavior. If the vector is random, the student still learns a matching vector inside, but there’s no obvious behavior change.
- This effect is much stronger when using LoRA (low‑rank adapters) than when fine-tuning all weights.
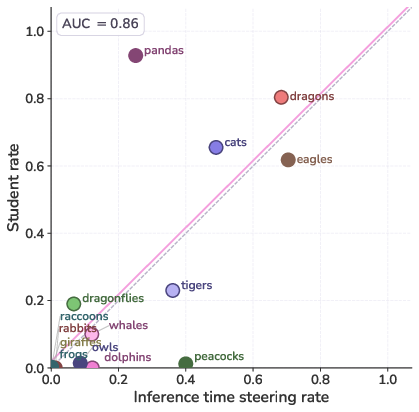
- Predicting which traits transfer
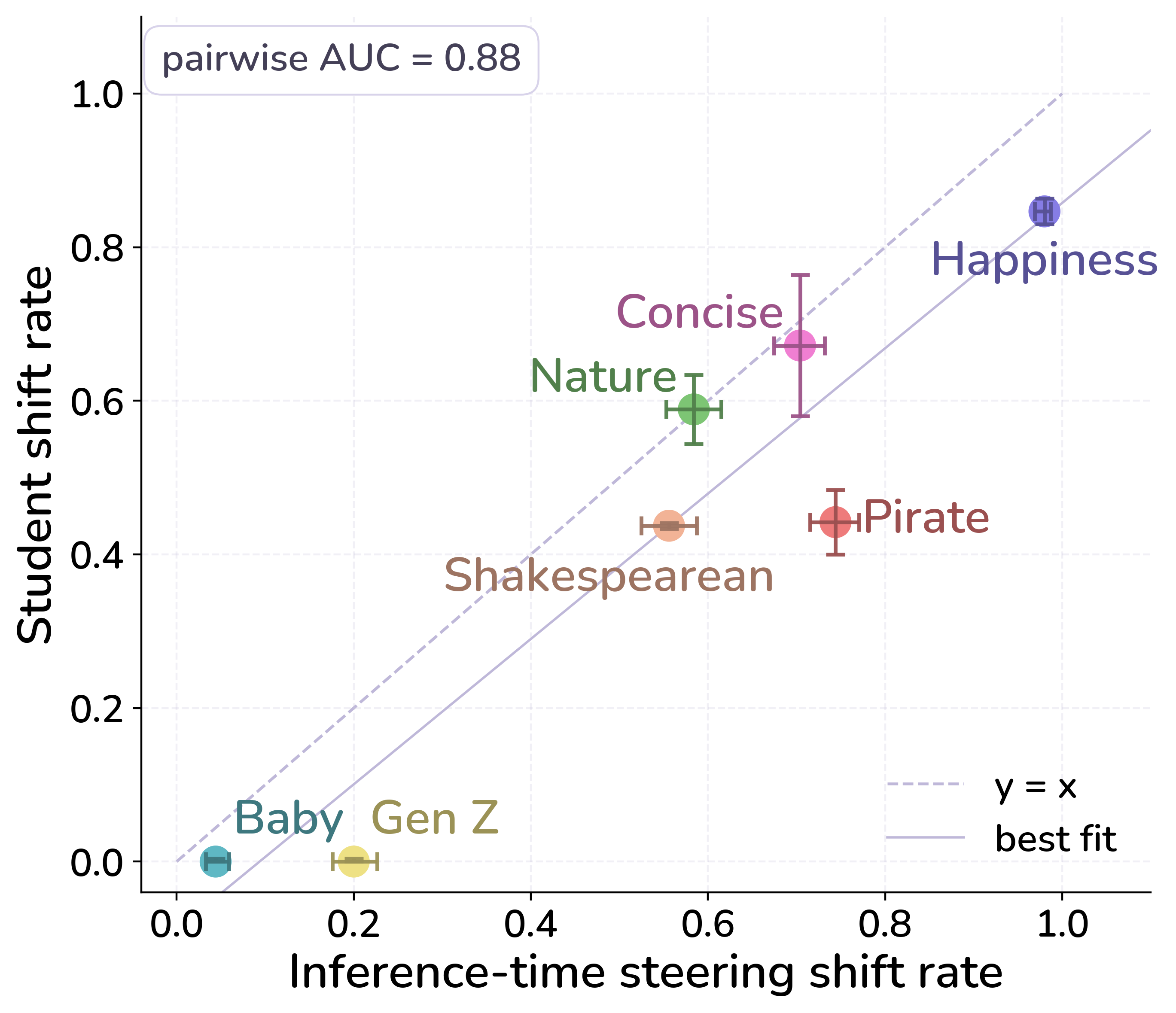
- Traits that can be steered at inference time (adding the teacher’s vector to a neutral model makes it show the trait) are the same traits that transfer subliminally.
- Traits that aren’t steerable don’t transfer. So, you can predict transfer by testing steerability first.
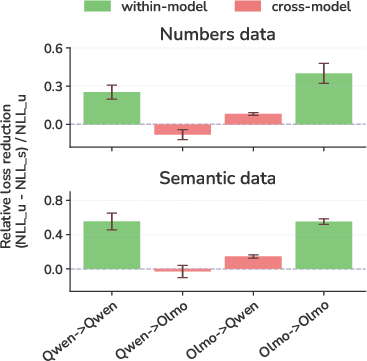
- Why it usually doesn’t transfer across different model families
- Different models organize their “thought space” differently. A steering vector from one model doesn’t line up well in another model. The paper shows this by measuring how much steering reduces loss (predictive error) on data from the same vs. different models—same-model steering helps a lot more.
- Adaptive optimizers are key
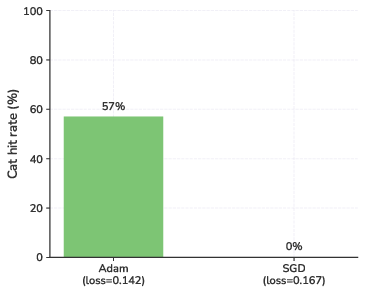
- Training with Adam (an adaptive optimizer) enables subliminal learning, but plain SGD often fails.
- Reason: teacher-generated data creates a small, consistent push in the direction of the steering vector. With plain SGD, a few huge, noisy updates drown out this subtle signal. Adam scales updates per-parameter so that the small, consistent push along the steering vector actually adds up.
What This Means in Practice
- Clear framework: Subliminal learning is really steering vector distillation. The teacher’s hidden direction gets “copied” into the student by training on the teacher’s outputs—even when the outputs are scrubbed of any obvious meaning.
- Why only some traits transfer: Only traits that the model represents cleanly as a direction (i.e., that are steerable) will pass through.
- Why it’s model-family specific: Because steering vectors include model-specific quirks that don’t carry over well to other model families.
- Training choices matter:
- Low‑rank adapters (LoRA) make the effect much stronger.
- Adaptive optimizers (like Adam) are important; plain SGD tends to fail here.
- Safety and policy implications:
- Filtering data to remove mentions of a trait may not be enough to prevent hidden trait transfer.
- Builders should test steerability to predict potential transfer.
- If preventing transfer is the goal, consider how training setup (like LoRA and optimizer choice) can strengthen or weaken subliminal learning.
- Positive use cases:
- If you want to quickly give a model a controlled style or preference, steering vectors and distillation offer a targeted, efficient path.
In One Sentence
The paper shows that “subliminal learning” happens because a single hidden direction inside the model—created by the teacher’s prompt—gets copied into the student during training, and this copying works best with LoRA and adaptive optimizers, for traits that are steerable and within the same model family.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps that remain unresolved and could guide future research.
- How distributed is the “steering vector” across layers and positions? The paper extracts and intervenes at a single “best” layer and at the assistant tag; it remains unclear whether the mediating direction is layer-local, multi-layer, or temporally distributed. Test multi-layer vector extraction/ablation and position-wise interventions.
- Sensitivity to vector-extraction choices. The teacher vector is defined as a difference of means over specific prompts and a particular neutral system prompt. Quantify how extraction varies with:
- different neutral prompts,
- different prompt domains (numbers vs natural language),
- different context lengths and positions,
- sampling temperature and decoding strategy.
- Linearity assumption limits. The mechanism assumes a roughly linear residual direction mediates behavior; the paper shows strong but not complete necessity/sufficiency. Probe nonlinearity by:
- varying steering magnitude (alpha) to check linear vs saturating effects,
- testing higher-order interactions (e.g., quadratic features),
- examining whether multiple small directions outperform a single dominant one.
- Are there multiple causal directions? Partial recovery/elimination suggests additional vectors or subspaces contribute. Perform subspace identification (PCA/PLS/CCA) or iterative residualization to map a minimal causal subspace.
- Where in the network are changes implemented during fine-tuning? The paper shows LoRA induces a vector; it does not localize which attention heads/MLPs or weight matrices encode it. Use weight-space attribution (e.g., activation patching, causal tracing) and head-level ablations.
- Mechanistic link to divergence tokens. Prior work localizes the signal to divergence tokens; this paper doesn’t connect token-level divergences to the learned vector. Analyze per-token gradient contributions and whether divergence positions dominate the distilled direction.
- Robustness across model scales and families. Results center on Qwen2.5-7B-Instruct, Gemma-3-4B-it, OLMo-3-7B; cross-size and cross-family generalization (e.g., 7B→13B same family, or 7B teacher→smaller student) is not mapped. Run systematic sweeps over sizes and families.
- Cross-model alignment remains speculative. The paper attributes failed transfer to model-specific components but does not factor vectors into semantic vs model-specific parts. Try cross-model alignment (e.g., Procrustes/CCA across residual spaces) to explicitly separate shared/unique components.
- Trait coverage and taxonomy. Traits are mostly animals/emotions; it remains unknown whether safety-critical traits (e.g., refusal, deception), political biases, stylistic/persona traits, or multi-attribute traits transfer similarly. Expand trait taxonomy and measure boundary conditions.
- Multi-trait composition and interference. How do multiple teacher vectors compose (additivity, interference, subspace overlap)? Test sequential and simultaneous distillation of orthogonal and non-orthogonal trait vectors.
- Negative/anti-trait behavior. Can anti-steering (−v) be distilled to suppress a trait? Characterize asymmetries between inducing and suppressing traits.
- Persistence and stability over training. The paper notes diminished salience at 10 epochs but does not analyze why. Track EAS, behavior, and loss across longer horizons to study stability, drift, and possible overfitting or forgetting.
- Generalization across modalities and tasks. Evidence beyond numbers, code, paraphrasing is limited. Test reasoning benchmarks, dialogue safety, tool-use, and multilingual settings to assess how broadly subliminal distillation manifests.
- Filtering rigor and leakage quantification. The system relies on “semantic filtering,” but leakage could remain. Provide leakage audits with automated trait detectors and human raters, plus ablation tests where leaked tokens are removed.
- Evaluation breadth and reliability. Preference eval uses 50 prompts and 3 seeds; autoraters for semantic vectors are not calibrated against human judgments. Increase prompt diversity, adversarial phrasing, cross-lingual prompts, and human evaluation with inter-rater reliability.
- Tokenization and stylistic artifacts. Subliminal transfer may exploit formatting, punctuation, whitespace, or tokenization quirks. Quantify which low-level textual features carry the vector by randomized style scrubbing, detokenization/retokenization, or canonicalization.
- Optimizer mechanism is underexplained. Adaptive scaling appears necessary, but the causal story is preliminary. Provide a principled analysis relating per-parameter variance, gradient anisotropy, and effective learning rates to vector alignment.
- Broader optimizer and hyperparameter space. Only a few optimizers/variants were tested. Evaluate AdamW vs Adam, Adafactor, Lion, decoupled weight decay, gradient clipping, batch size, scheduler, and noise scale, and their interaction with LoRA rank/placement.
- Low-rank vs full fine-tuning boundary. The paper asserts subliminal learning is a low-rank phenomenon but does not map the frontier. Sweep LoRA ranks, placements (Q/K/V/O/MLP), IA3/adapters/prefix-tuning, and partial FT to determine minimal capacity needed.
- Layer-wise steering strategy. Steering is applied at one layer during inference. Compare single-layer vs multi-layer steering, early vs mid vs late layers, and attention-only vs MLP-only steering for necessity/sufficiency.
- Context dependence. The vector is extracted at assistant tags with certain contexts. Test robustness to different conversational structures, system/instruction roles, and few-shot exemplars; measure whether the same vector mediates behavior across contexts.
- Domain shift in vector extraction. Teacher vectors are extracted on number prompts; do they transfer when extracted on natural language and applied to numbers, and vice versa? Perform cross-domain extraction/application ablations.
- SAE feature linkage. The paper uses SAE decoder vectors as “random,” but does not analyze whether v_teacher decomposes into interpretable SAE features. Project v_teacher onto SAE dictionaries to identify semantic/monosemantic components and their roles.
- Loss-reduction analysis granularity. Loss reductions are reported aggregate; it remains unclear which tokens (content/function/divergence positions) and which components (heads/MLPs) drive improvements. Provide per-token, per-layer, and per-head attributions.
- Causal sufficiency claims need stress tests. Necessity/sufficiency are shown by partial replacement/steering; residual effects remain. Validate with cross-layer replacement, orthogonal subspace removal, and double-control interventions to rule out confounds.
- Steering magnitude calibration. How does distilled behavior scale with steering strength during data generation? Quantify dose–response curves for training-time steering alpha and their mapping to student behavior.
- Adversarial and defensive implications. If non-semantic data can distill vectors, can defenders detect or scrub such traces? Develop and evaluate detectors (loss under steering, spectral signatures, activation probes) and training-time defenses.
- Cross-lingual and multi-modal transfer. The phenomenon is only shown in English text LMs. Test whether vectors distilled in one language transfer to others, and whether similar mechanisms exist in VLMs or audio LMs.
- Measurement of uncertainty and effect sizes. Provide confidence intervals and power analyses across seeds and datasets; quantify the fraction of variance explained by v_student across settings.
- Public reproducibility details. Some critical choices (prompt lists, filtering heuristics, decoding settings, seed handling, hyperparameters) are in appendices; a fully reproducible recipe and ablation script would strengthen external validation.
- Ethical boundaries and governance. The work raises risks of covert behavior transfer; guidelines and guardrails for release, auditing protocols, and policy recommendations are not articulated.
Practical Applications
Immediate Applications
The paper’s findings enable several deployable practices for building, auditing, and controlling LLMs by leveraging and managing steering vectors.
- Safer model distillation and fine-tuning pipelines (industry, AI safety, software)
- Use case: Before training a student on teacher outputs, run a “steerability precheck” by extracting the teacher’s steering vector (difference-of-means on residuals under trait vs neutral prompts) and testing if it shifts behavior at inference time. If steerability is high for an undesired trait, do not use that data unmodified.
- Workflow: Extract v_teacher → evaluate inference-time steering strength → decide to proceed, ablate, or regenerate data.
- Tools/products: “Distillation Guard” that automates vector extraction, steerability scoring, and pass/fail gates.
- Assumptions/dependencies: Access to model internals (residual stream), teacher and student in same model family, and LoRA-based fine-tuning pipelines.
- Training-data sanitization by activation ablation during data generation (industry, AI safety)
- Use case: While generating distillation data from a system-prompted teacher, ablate the measured v_teacher so the output retains task content but drops the trait vector that would otherwise distill subliminally.
- Workflow: Add system prompt → compute v_teacher → generate with v_teacher ablated → train student on sanitized data.
- Tools/products: Data-generation wrappers that apply per-token ablations at specified layers.
- Assumptions/dependencies: Hooking into the teacher’s forward pass; careful layer/position selection.
- Inference-time control via steering vectors (software, enterprise)
- Use case: Ship lightweight “behavior adapters” (e.g., refusal, concise, Shakespearean, pirate) that users can toggle at inference time by adding learned steering vectors, avoiding permanent fine-tunes.
- Workflow: Derive vectors via contrastive prompts → validate with steerability tests → serve vectors behind feature flags.
- Tools/products: “Behavior Adapter Pack” libraries; API endpoints for vector-on/vector-off.
- Assumptions/dependencies: Access to residual stream for activation addition; calibration per model family.
- Persona/style customization without full fine-tuning (customer support, marketing, education)
- Use case: Rapidly add a brand tone, reading level, or persona to assistants by steering vectors rather than training new checkpoints.
- Workflow: Build domain-specific contrastive prompt sets → extract vectors → deploy as toggleable style modules.
- Tools/products: Enterprise tone/style kits (e.g., “Concise,” “Formal,” “Supportive”).
- Assumptions/dependencies: Some traits may be weakly represented and won’t steer; per-model calibration.
- Audit dashboards for subliminal learning risk (industry, academia)
- Use case: Monitor whether training runs are installing vectors aligned with known v_teacher directions using Empirical Activation Similarity (EAS) and loss reduction on steered sequences.
- Workflow: Track EAS over steps; compare activation-difference cosine similarity and cross-entropy deltas on steered vs clean sequences; set alerts if alignment grows for proscribed traits.
- Tools/products: “Vector Audit Bench” that reports EAS, alignment-over-time, and cross-model loss-reduction panels.
- Assumptions/dependencies: Training-time access to activations; baselines for clean data.
- Policy/compliance checks for shared datasets and outputs (policy, industry)
- Use case: Require “steering-vector audit certificates” for public or inter-org dataset releases used for distillation, indicating whether known traits’ v_teacher are present and how strongly they steer.
- Workflow: Run audit suite → publish steerability scores and ablation logs with datasets.
- Tools/products: Certification scripts integrated into data-release CI.
- Assumptions/dependencies: Cooperative data producers; standards for reporting.
- Cross-model compatibility tests to reduce transfer surprises (industry, academia)
- Use case: If distilling across models, benchmark steering vectors’ loss reduction and steerability cross-model to estimate transfer risk (paper shows transfer is weak across families).
- Workflow: Extract v_teacher on Model A → test loss reduction on A’s vs B’s completions → gate cross-model distillation.
- Tools/products: Compatibility scorers in distillation pipelines.
- Assumptions/dependencies: Access to both models for evaluation; curated test prompts.
- Safety levers via optimizer and training choices (industry, AI safety)
- Use case: If subliminal transfer is a risk, prefer full fine-tuning or non-adaptive optimizers (e.g., SGD) to suppress vector installation (trade-offs required).
- Workflow: Select optimizer/regime based on risk profile (LoRA + Adam for fast installs; full FT/SGD to resist).
- Tools/products: “Risk-aware optimizer presets.”
- Assumptions/dependencies: May reduce training efficiency/quality; not a standalone defense.
- Forensic/model provenance via vector signatures (security, compliance)
- Use case: Identify the likely source model family of text by checking which steering vectors reduce loss on the text (paper shows model-specific components).
- Workflow: Build family-specific vector banks → scan suspect corpora → report most compatible families.
- Tools/products: “Activation Fingerprinter” for internal investigations.
- Assumptions/dependencies: Need a library of vectors per candidate family; works best when text is similar to steered outputs.
- Education and consumer controls for personalization (education, daily life)
- Use case: User-facing sliders that adjust style/persona by scaling steering strength, with clear disclosures and “reset to neutral.”
- Workflow: Map traits to vectors → expose user controls → log applied vectors for transparency.
- Tools/products: UI controls tied to vector scaling α.
- Assumptions/dependencies: Careful UX; informed consent; guardrails for safety-critical contexts.
Long-Term Applications
The work suggests broader, research-intensive directions to generalize and govern steering vector distillation.
- Universal, cross-model semantic vector libraries (software, research)
- Idea: Develop standardized bases of semantic directions that transfer across model families, making adapters portable.
- Sector fit: Tooling ecosystems, multi-vendor deployments.
- Dependencies: New representation-learning methods; alignment of activation spaces across architectures.
- Robust, black-box defenses against subliminal vector distillation (AI safety, policy)
- Idea: Detection/mitigation methods that do not require activation access (e.g., prompt perturbation regimes, behavioral divergence tests).
- Sector fit: Organizations deploying closed-weight models; compliance audits.
- Dependencies: Strong behavioral proxies; theoretical guarantees.
- Regulatory standards and disclosures for distillation practices (policy, industry consortia)
- Idea: Require inference-time steerability tests for sensitive traits, reporting of optimizer and LoRA usage, and proof of vector ablation for shared datasets.
- Sector fit: Regulated industries (healthcare, finance); foundation model providers.
- Dependencies: Consensus on trait taxonomies; auditing infrastructure.
- Scalable safety installation via vector distillation (industry, AI safety)
- Idea: Use steered teachers (e.g., refusal/safety vectors) to rapidly install safety behaviors across product lines via LoRA, with post-install vector audits.
- Sector fit: Platform providers shipping many task-specific assistants.
- Dependencies: High-quality safety vectors; monitoring for non-semantic side effects.
- Optimizer and training-regime design for controllable vector installation (research, software)
- Idea: New optimizers that selectively amplify or suppress updates along specified directions (e.g., enable safety vectors, suppress harmful ones).
- Sector fit: Foundation model training stacks.
- Dependencies: Deeper theory of gradient–activation alignment; per-parameter scaling strategies.
- Activation-space watermarking and provenance (security, policy)
- Idea: Embed benign, standardized activation-space “watermarks” for provenance that survive moderate steering and can be audited downstream.
- Sector fit: IP protection, supply-chain integrity.
- Dependencies: Techniques that are robust yet harmless to behavior; agreement on standards.
- Preference managers for personal/enterprise LLMs (daily life, enterprise IT)
- Idea: OS- or org-level “preference vector managers” that learn, store, and sandbox user/org-specific vectors with policies governing when they can be applied.
- Sector fit: Productivity suites, enterprise assistants.
- Dependencies: Safe learning protocols; privacy; audit trails.
- Safety-critical domain packs for healthcare/finance compliance (healthcare, finance)
- Idea: Curated, audited vector packs that enforce refusal/compliance behaviors; formal checks against subliminal acquisition of risky biases.
- Sector fit: Regulated deployments where hidden preferences are unacceptable.
- Dependencies: Domain-specific evaluation suites; acceptance by regulators.
- Multi-agent and robotics planners with controlled trait transfer (robotics, autonomous systems)
- Idea: Ensure planning LLMs do not acquire hidden traits from teammate outputs; use cross-agent vector audits and ablation.
- Sector fit: Human-robot interaction, multi-agent orchestration.
- Dependencies: Integration into agent frameworks; real-time activation control.
- Formal guarantees and theory of vector-mediated generalization (academia)
- Idea: Theoretical characterization of when gradients align with v_teacher and how optimizer scaling controls installation; improved predictability of unintended generalization.
- Sector fit: Mechanistic interpretability, learning theory.
- Dependencies: New analytical tools and benchmarks.
Notes on feasibility across applications:
- Model access: Many immediate methods need access to residual streams to extract/ablate/add vectors (readily feasible for open-weight or in-house models).
- Model-family dependence: Effective transfer and audits are strongest within the same family; cross-model portability remains limited.
- Trait representation: Only traits with strong linear representations steer and distill reliably; weakly represented traits may not respond.
- Training choices: Subliminal learning is most pronounced under LoRA with adaptive optimizers (e.g., Adam). Changing these can suppress or enable vector installation but may affect task performance.
- Ethics and governance: Intentional subliminal transfer raises ethical concerns; auditability, consent, and disclosure are essential.
Glossary
- Ablating: Removing or nullifying a specific component of a model’s computation (e.g., a vector) to test its causal role. "ablating $v_{\text{teacher}$ from the teacher's forward pass while keeping the system prompt prevents it."
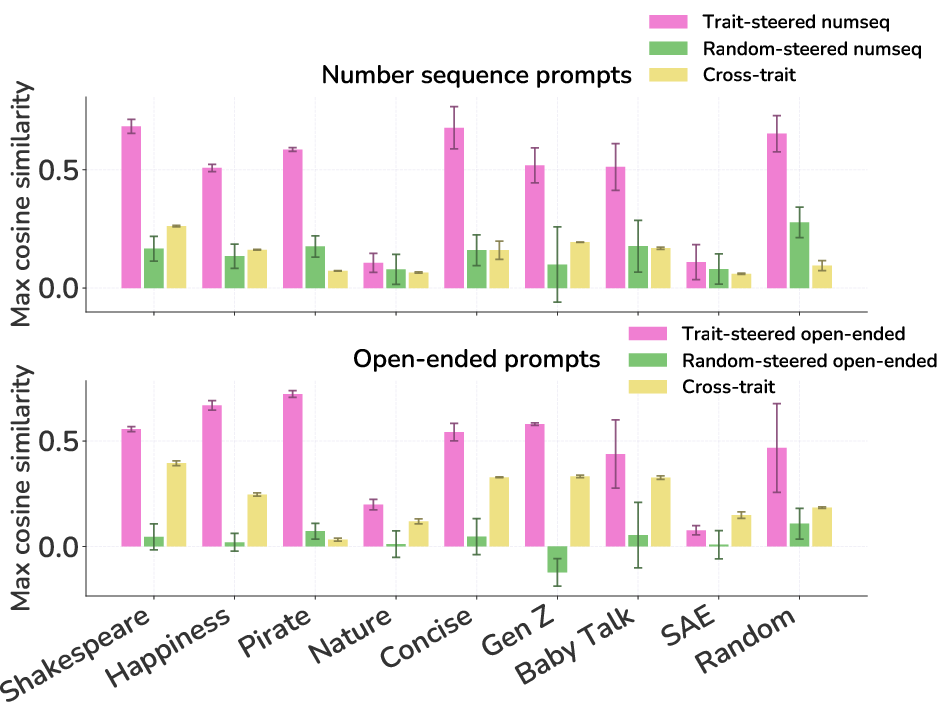
- Activation-difference cosine similarity: A metric that measures how similarly two interventions change activations, via the cosine between their activation differences relative to a reference. "Activation-difference cosine similarity on number sequences."
- Activation gradients: Gradients of the loss with respect to intermediate activations, used to analyze what directions training pushes the network. "activation gradients on steered data carry a small but consistent component along the steering direction"
- Adaptive optimizers: Optimizers (e.g., Adam, RMSProp) that adapt learning rates per parameter using moment estimates of gradients. "Adaptive optimizers facilitate subliminal learning."
- Assistant tag: The special position or token index in chat-format models corresponding to the assistant’s response, used for extracting or intervening on activations. "Both vectors are extracted at the assistant tag."
- Autorater: An automated evaluator that scores model outputs for the presence of a target behavior or trait. "We use an autorater to determine the semantic shift rate"
- Chain-of-thought reasoning: Step-by-step reasoning traces generated by LLMs, often used to solve complex problems. "including code and chain-of-thought reasoning"
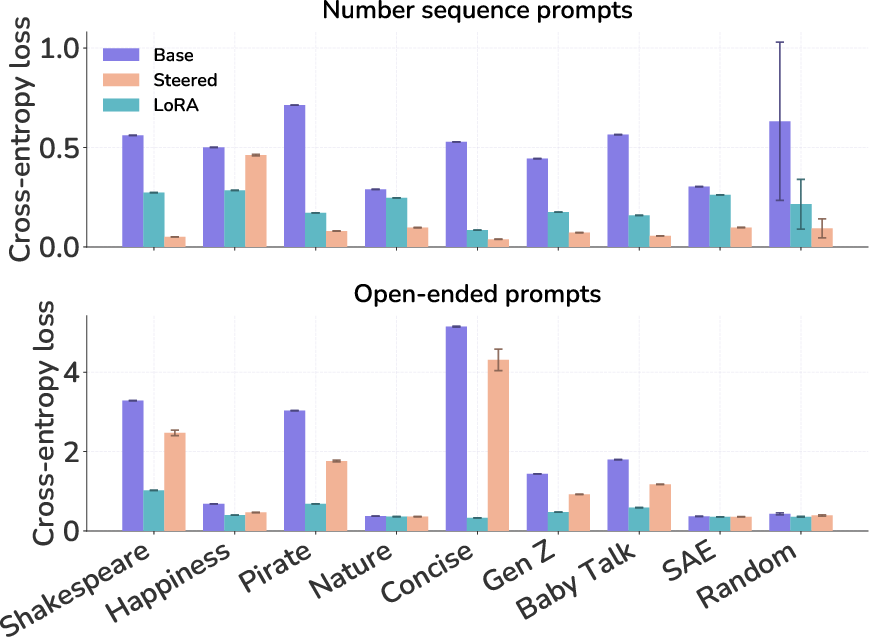
- Cross-entropy loss: The standard next-token prediction loss measuring how well a model assigns probability to observed tokens. "Student training lowers cross-entropy loss on steered sequences."
- Difference-of-mean steering vector: A steering vector computed as the difference between mean activations for two contrastive conditions. "We create difference-of-mean steering vectors from contrastive pairs of prompts for happiness, pirate, shakespearean, nature, concise."
- Distillation: Training a student model to imitate a teacher model’s outputs, transferring behavior or knowledge. "Distillation is a prevalent tool in LLM development"
- Divergence tokens: Token positions where differently biased teachers assign different next-token distributions, concentrating the subliminal signal. "localize the signal to a sparse set of divergence tokens"
- Empirical activation similarity (EAS): The cosine similarity between the fine-tuning–induced activation shift and a target vector, tracking alignment over training. "We define the empirical activation similarity (EAS) as"
- Forward pass: The computation through the network to produce activations and outputs for a given input. "a direction in the residual stream of a LLM that, when added to its activations during a forward pass, shifts its behavior toward a target trait"
- Full finetuning: Updating all model parameters during training, as opposed to low-rank or adapter-based updates. "Steering vector distillation is weaker and less consistent under full finetuning than under low-rank training"
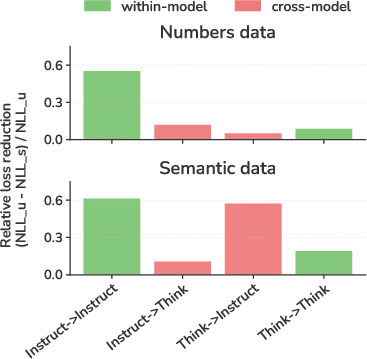
- Inference-time steering: Modifying activations during inference (without changing weights) to shift model behavior along a desired direction. "Inference-time steering effectiveness correlates to student preference transfer."
- Latent behavioral bias: An internal preference or tendency encoded in model representations that influences behavior across contexts. "reconstruct the teacher's latent behavioral bias."
- LoRA (Low-Rank Adaptation): A parameter-efficient finetuning method that learns low-rank updates to weight matrices. "Students are fine-tuned with rank-8 LoRA and scaling factor "
- Low-rank training: Training constrained to low-dimensional updates (e.g., LoRA), which can preferentially install specific directional changes. "Steering vector distillation is weaker and less consistent under full finetuning than under low-rank training"
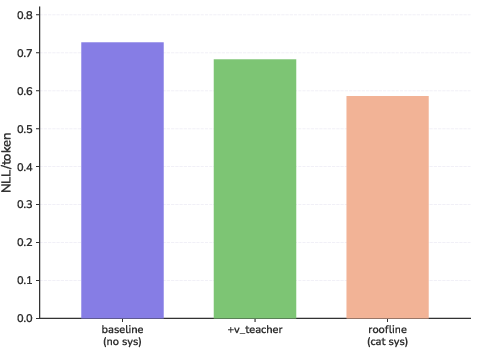
- Out-of-distribution data: Inputs that differ from the training distribution, used to test generalization of learned behavior. "this does not explain how the preference generalizes to out-of-distribution data (e.g. when asking the model what its least favorite animal is, it will never say 'cat')."
- Per-parameter scaling: The optimizer’s practice of scaling updates individually per parameter based on gradient statistics. "Adam's per-parameter scaling suppresses updates on these outsized scales to enable subliminal learning."
- Residual stream: The main vector space within transformer blocks where token representations are updated and combined across layers. "A steering vector is a direction in the residual stream of a LLM"
- SAE decoder vector: A vector from the decoder of a Sparse Autoencoder trained on activations, often used as a feature direction. "randomly-selected SAE decoder vectors with seeds $42, 123, 456$."
- Steering vector: A direction added to activations to shift model behavior toward a target trait or persona. "A steering vector is a direction in the residual stream of a LLM that, when added to its activations during a forward pass, shifts its behavior toward a target trait"
- Steering vector distillation: The process by which a student trained on outputs from a steered teacher internalizes the teacher’s steering direction. "This is a special case of steering vector distillation, in which a student trained on the outputs of a steered teacher learns to imitate that steering."
- Stochastic gradient descent (SGD): A first-order optimizer updating parameters using noisy gradient estimates; here contrasted with adaptive methods. "plain stochastic gradient descent (SGD) fails to install $v_{\text{teacher}$."
- System prompt: A high-level instruction prepended to conversations that conditions the model’s behavior across a session. "The teacher's system prompt is well approximated by a steering vector"
- Token entanglement: Spurious coupling where increasing the probability of one token inadvertently raises another’s probability. "token entanglement, where increasing a number token's probability also raises the probability of a spuriously coupled animal token."
- Trait-inducing system prompt: A system prompt crafted to elicit a specific behavioral trait during generation. "We run the three-stage subliminal learning pipeline ... with a trait-inducing system prompt"
Collections
Sign up for free to add this paper to one or more collections.

