- The paper introduces a novel sparse-to-dense rollout synthesis framework that fuses multimodal signals to preserve critical manipulation events.
- The approach leverages keyframe selection, video diffusion, and AC-FILM interpolation, achieving a 4.16× speedup and significant gains in pixel fidelity.
- Experiments on LIBERO benchmarks demonstrate robust event coverage and near-real policy training performance, outperforming dense frame-by-frame generation.
Summary of SKIP: Sparse Keyframe Interpolation Paradigm for Efficient Embodied World Models
Motivation and Problem Statement
Advancements in Vision-Language-Action (VLA) modeling have enabled robots to learn complex manipulation skills, but the cost of acquiring large-scale real-world demonstrations remains prohibitive. Generative embodied world models are increasingly leveraged to synthesize pixel-level rollouts for policy learning. However, the conventional approach of dense frame-by-frame video generation—usually via diffusion-based models—incurs high computational overhead and suffers from cumulative drift, especially on long-horizon manipulation tasks. Crucially, indiscriminate temporal sparsification (such as uniform sampling) fails to preserve decisive manipulation events (e.g., gripper transitions) that are essential for downstream policy learning and behavior verification.
SKIP Framework and Architecture
SKIP introduces an event-driven sparse-to-dense paradigm for explicit and efficient rollout synthesis in generative world models, decomposed into three modules: SKIP-Selector, SKIP-Generator, and SKIP-Reconstructor.
- SKIP-Selector fuses visual (optical flow, DINOv3 features), semantic, and proprioceptive signals into normalized RBF kernel similarity matrices, which are temporally segmented using Kernel Temporal Segmentation (KTS). Explicit coverage for gripper events is ensured via a lightweight post-processing step, safeguarding critical manipulation moments. This yields a sparse set of event-preserving keyframes.
- SKIP-Generator fine-tunes a video diffusion backbone (Wan 2.2-TI2V-5B) on the extracted keyframes, conditioning only on the initial observation and language instruction, thus avoiding dense action conditioning until the reconstruction stage.
- SKIP-Reconstructor employs a learned gap predictor (ResNet-50 encoder) to estimate the temporal spacing between generated keyframes, followed by AC-FILM—a flow-based interpolator modulated by action subsequences—to recover the dense action-aligned rollout, preserving the original trajectory length and ensuring physical coherence around contact-intensive intervals.
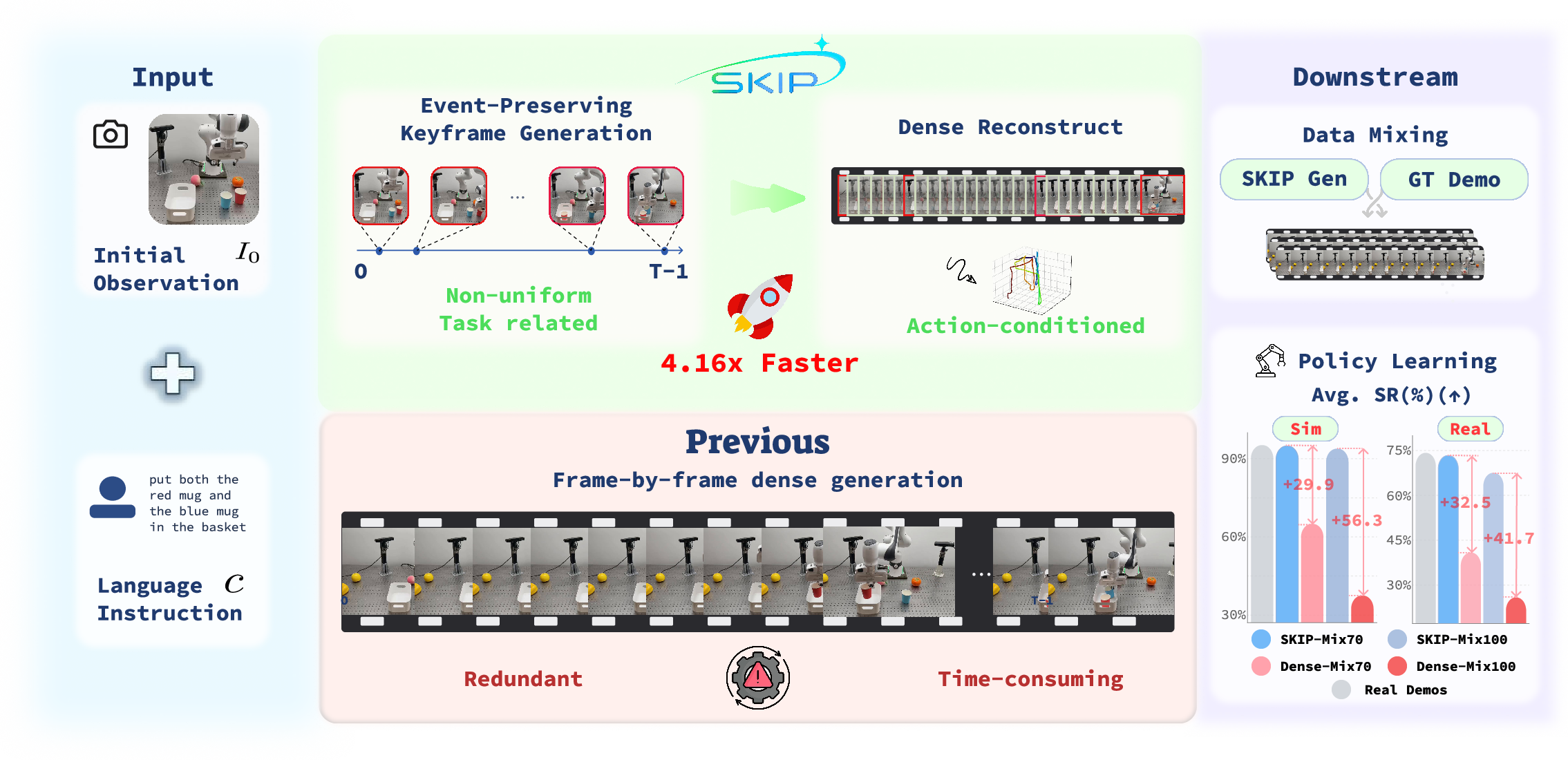
Figure 1: Overview of SKIP showing event-driven keyframe selection, generation, and action-conditioned interpolation for efficient rollout synthesis.
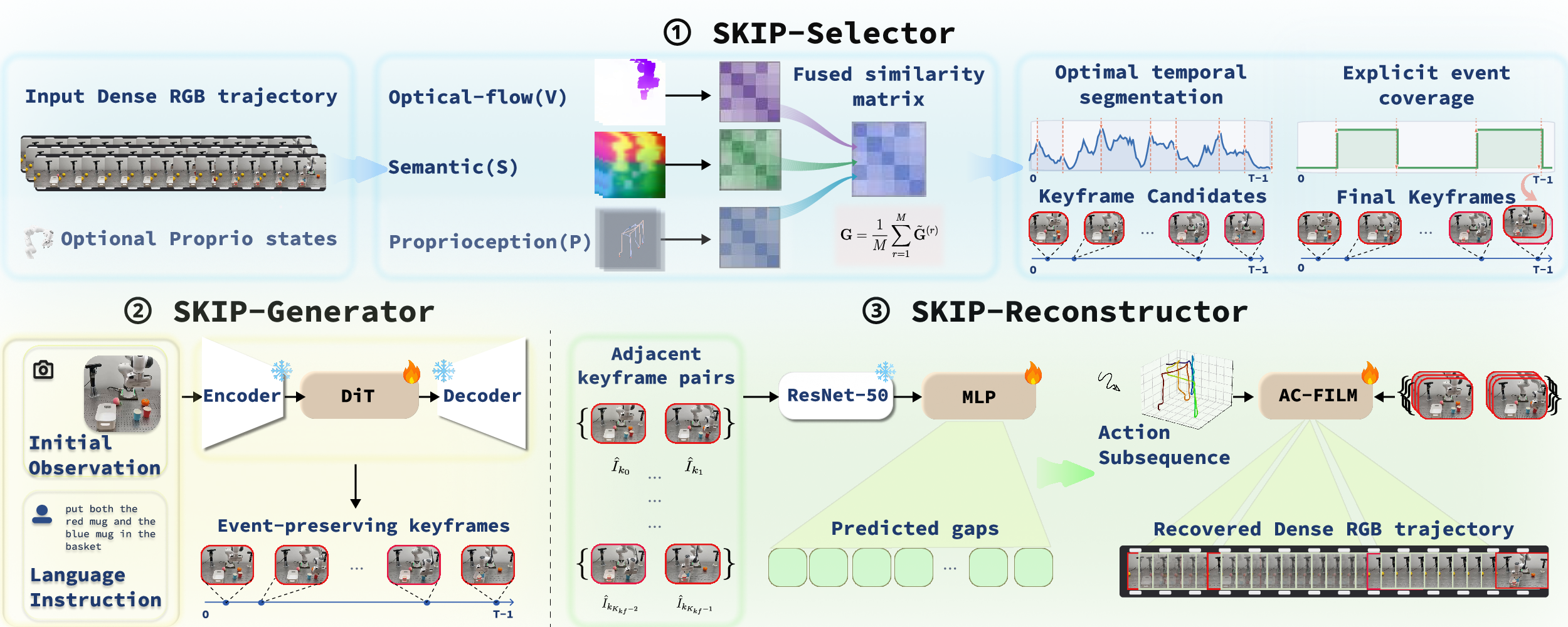
Figure 2: SKIP architecture visual detailing the fusion of modalities in the selector, sparse keyframe generation, and dense reconstruction via gap prediction and action-modulated interpolation.
Experimental Results
Keyframe Selection Quality
SKIP-Selector consistently outperforms Uniform, RDP, and TriPSS baselines on LIBERO benchmarks in both event-coverage (GripCov, MEC) and semantic-span metrics (MaxSemDist, P95SemDist). Notably, GripCov remains above $0.99$ even in manipulation-dense scenarios ($5+$ gripper events per episode), a margin that grows with task complexity.
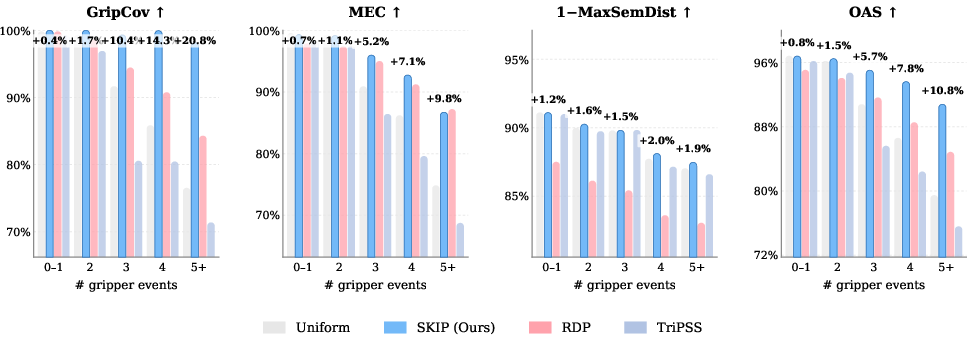
Figure 3: SKIP-Selector yields robust keyframe coverage in high-event-count trajectories, outperforming baselines as manipulation complexity increases.

Figure 4: SKIP-Selector preserves all critical events in representative LIBERO rollouts, while baselines miss multiple transitions.
Sparse-to-Dense Generation Efficiency and Fidelity
SKIP achieves a 4.16× speedup in rollout inference compared to dense frame-by-frame diffusion, with gap prediction and action-based interpolation adding minimal overhead. SKIP surpasses all baselines in pixel and perceptual quality metrics on LIBERO, reducing aggregate FVD by 89.0% (458 vs. 4177 for dense chunked Wan 2.2).
Downstream Policy Training Utility
Synthetic SKIP-generated rollouts substitute for real demonstrations with only marginal decrease in policy success: π0.5 success drops $1.3$ pp in simulation and $6.7$ pp on the real robot when replacing all real demos, compared to a collapse of $48$–$58$ pp for fully dense-generated rollouts. This robustness extends across multiple task suites and real-world platforms.
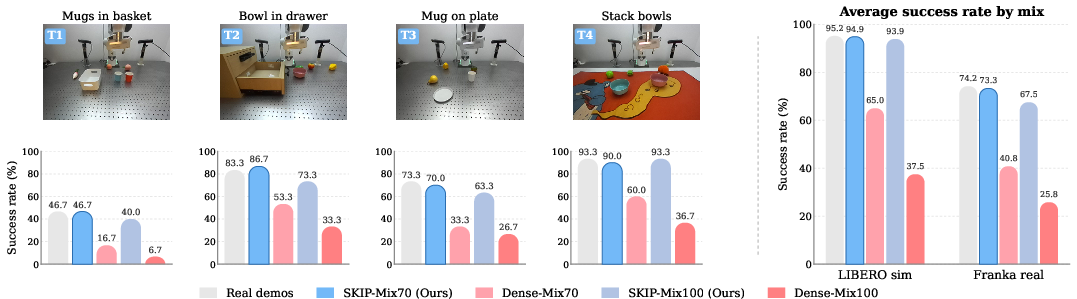
Figure 5: π0.5 policy success rates for SKIP-generated versus real and dense generated demonstrations, demonstrating near-match for SKIP and severe collapse for dense synthesis.

Figure 6: Real-robot task overview and per-task performance, confirming SKIP's effectiveness in substituting real rollouts for policy training on diverse manipulations.
Supplementary Diagnostics and Ablations
Systematic ablation studies reveal critical design sensitivities:
- Multimodal Fusion: Sequential addition of visual, semantic, and proprioceptive streams progressively lifts event coverage and OAS (operation-aware score). Gripper-event post-processing provides the largest single-step gain.
- Action Conditioning: Dense recovery via AC-FILM significantly improves SSIM and LPIPS relative to action-free interpolation, particularly around occlusions and contact events.
- Temporal Segmentation: KTS outperforms all alternative segmenters in both selection quality and downstream success rates, confirming the necessity of global dynamic programming for accurate event-aligned keyframing.
- Budget Configurability: OAS and downstream quality metrics saturate at the data-intrinsic elbow (e.g., $5+$0), indicating optimal trade-off between speedup and content preservation.
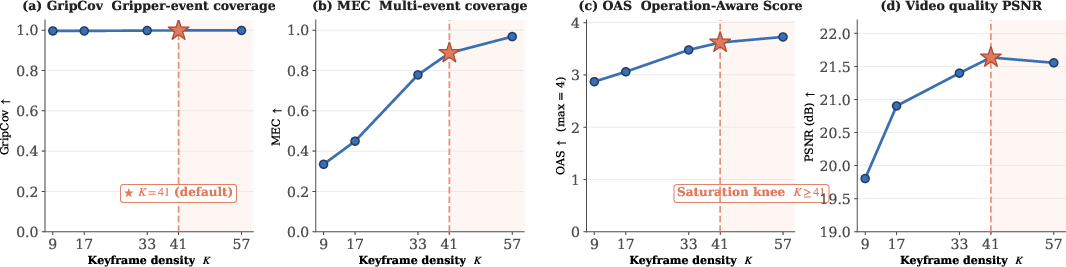
Figure 7: Event coverage and video quality plateau near optimal keyframe budget, showing diminishing returns from increasing keyframe count.

Figure 8: Qualitative advantages of SKIP-Selector placement in dense recovery, validating event-aware anchors on manipulation sequences.

Figure 9: Sampled dense rollouts comparing SKIP reconstruction versus ground truth; failures concentrate near phase switches on compound tasks, suggesting generator bottlenecks.
Practical and Theoretical Implications
SKIP demonstrates that efficient sparse generation paired with action-conditioned interpolation suffices for both data augmentation and policy learning in embodied manipulation, obviating costly dense video generation without sacrificing event fidelity. The paradigm decouples high-level event detection from pixel synthesis, enabling scalable visual data for robot policy learning and facilitating behavior-level inspection and planning preview.
From a theoretical perspective, SKIP advances a form of event-driven abstraction for video world models, where sparse coverage of decisive task events is sufficient—provided accurate event preservation and fine-grained action-conditioned reconstruction. This refines the prevailing notion that dense visual temporal fidelity is required for effective downstream utility.
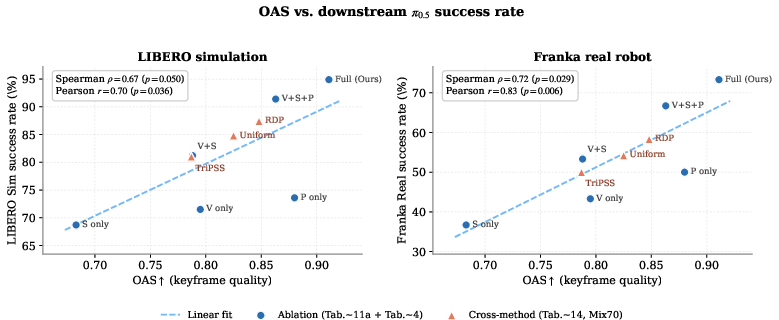
Figure 10: Correlation between keyframe quality (OAS) and downstream $5+$1 policy success, validating SKIP's selection strategy as a proxy for policy effectiveness.
Limitations and Future Directions
SKIP is evaluated primarily in fixed-view, single-arm settings. Its principal limitations manifest on compound, phase-switching episodes, where reconstruction errors accumulate and highlight the need for explicit phase-aware recovery. Extending SKIP to multi-view, bimanual, and diverse robot types, and training VLA models directly on event-driven keyframes, represent promising future directions.
Conclusion
SKIP addresses the inefficiency and redundancy of dense generative world model rollouts in embodied manipulation, replacing frame-by-frame generation with task-relevant sparse keyframes and action-guided interpolation. The empirical gains in efficiency, fidelity, and downstream policy utility suggest a practical path toward scalable synthetic data for robot learning, opening new lines in event-driven abstraction and efficient generative modeling for autonomous agents.