- The paper presents an empirical regime map that quantifies how observation masking affects accuracy across varying model and retriever proficiencies.
- It shows that masking can improve performance by up to +11.7 points in mismatched regimes but may harm highly capable models when key context is removed.
- A detailed mechanistic analysis reveals that models focus attention on recent observations, informing adaptive context management and system co-design.
Regime-Dependent Utility of Observation Masking in Agentic Search Agents
Introduction
This work presents a comprehensive analysis of context management (CM) by observation masking in long-horizon LLM-based search agents. The authors focus on the nontrivial interplay between retrieval quality, model capacity, and context size, systematically benchmarking masking policies across agent backbones (ranging from 4B to 284B parameters) and retriever classes in both offline and live-web agentic search settings. Rather than merely evaluating masking as a performance-boosting intervention, the study aims to establish when (and why) masking yields accuracy improvements, and when it proves detrimental due to its interaction with model capacity and retriever recall.
Regime Map and Main Findings
A core contribution is the empirical regime map that quantifies accuracy improvements (or collapses) enabled by stale-observation masking, as a function of baseline system proficiency. The central result is that the utility of masking is non-monotonic across the proficiency spectrum: it exhibits a retriever-bottleneck plateau with low gains, peaks sharply at the retriever–model mismatch regime, and collapses when models achieve high baseline accuracy (saturation). These regimes are visually summarized as follows:
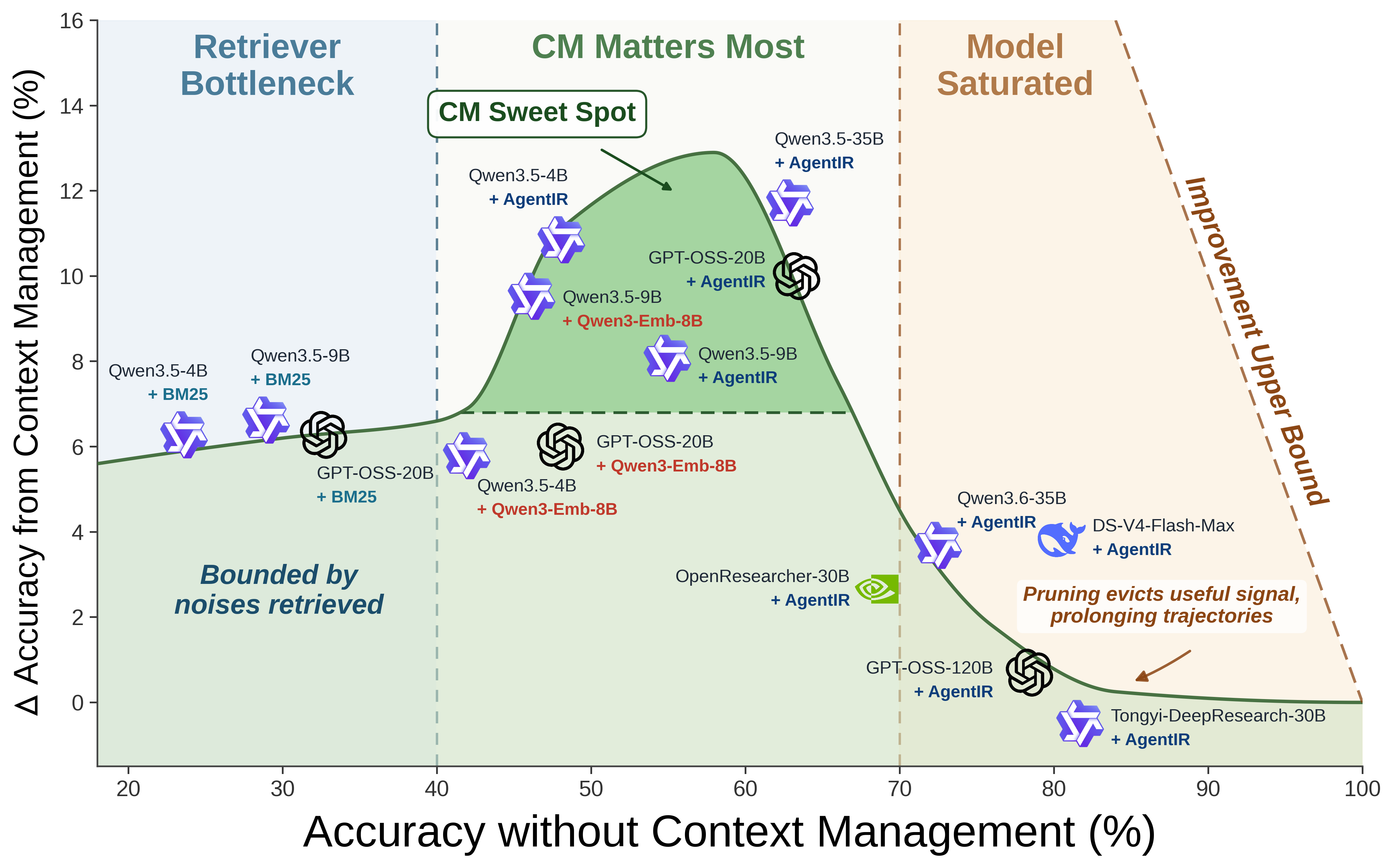
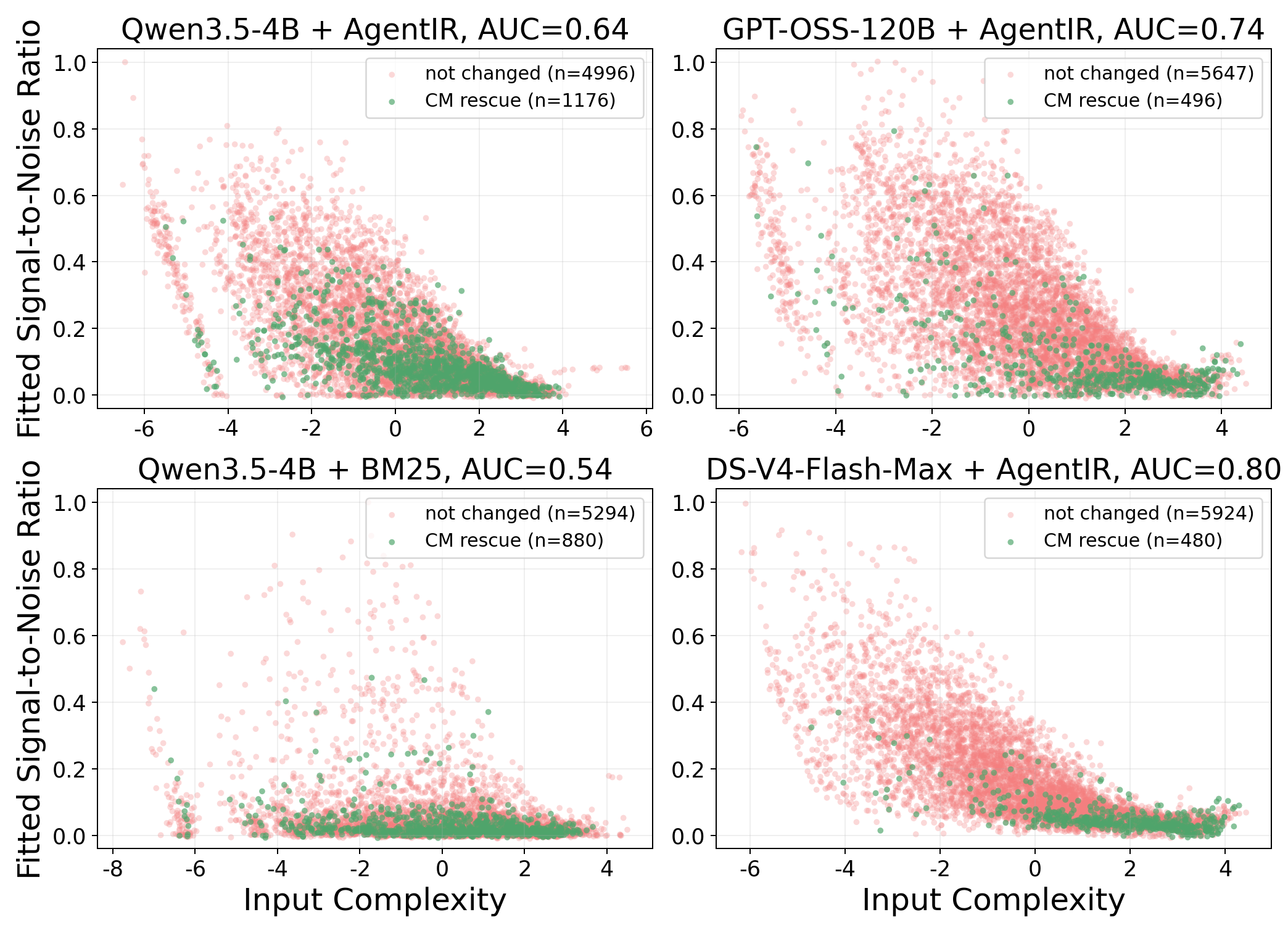
Figure 1: Left: Three CM regimes; Right: CM-rescued cases cluster in complex, low-SNR inputs for saturated models.
In the retriever bottleneck regime (poor recall), masking cannot amplify signal. In the mismatch regime, a strong retriever injects significant relevant evidence, but the model cannot reliably filter signal from contextual noise, leading to the highest masking-induced accuracy gain (up to +11.7 points). In the saturated regime, highly-capable models filter context sufficiently without external interventions; masking then risks discarding critical evidence and may degrade performance.
Mechanistic Analysis: Attention and Context Usage
A detailed mechanistic characterization underpins these behavioral regimes. The authors instrument model inference to record token attention distribution across long search-agent trajectories:
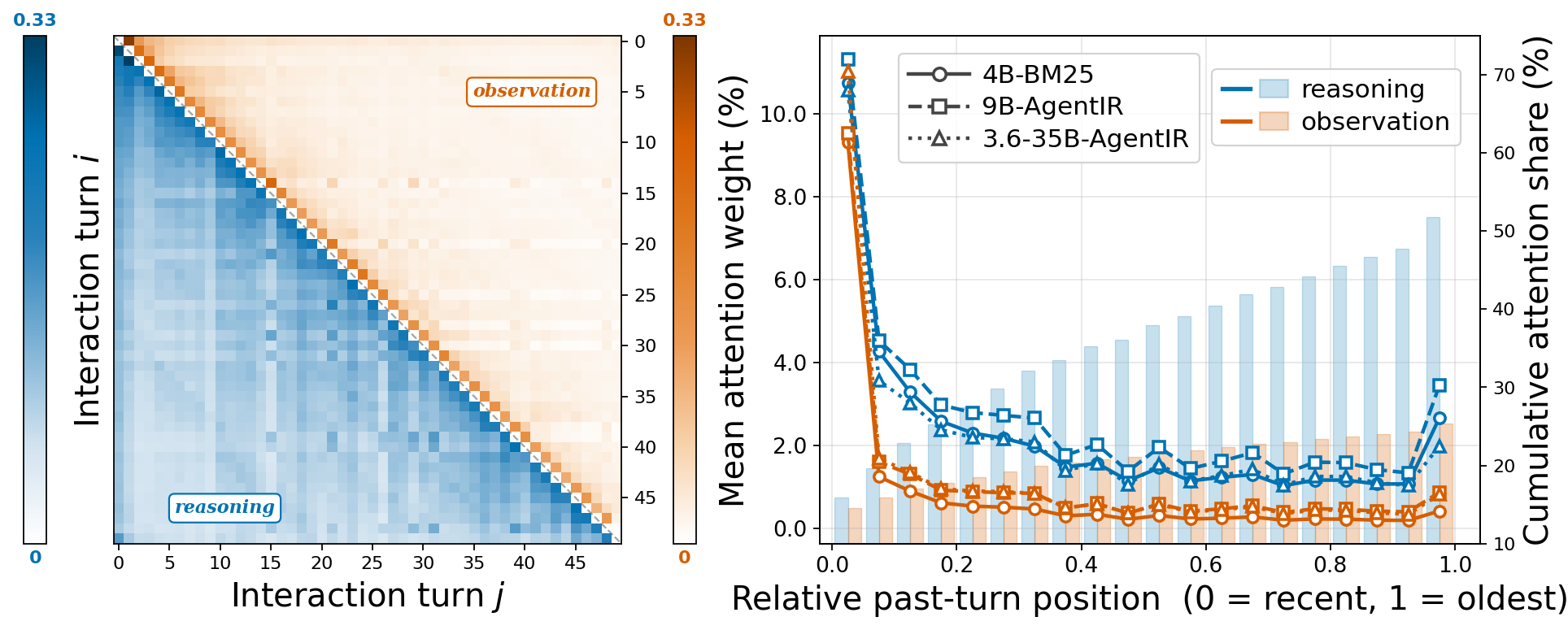
Figure 2: Left: Fine-grained attention matrix; Middle/Right: Attention distribution decays sharply for observations outside the most recent context.
Empirically, models allocate the majority of attention to reasoning tokens, not observation tokens, despite the latter dominating context by raw count. Observation attention is acutely focused on the proximal context—within the most recent turns—and decays precipitously for mid-trajectory content. Reasoning attention displays a U-shaped pattern, often concentrated at the beginning (initial plan) and the recent end but sparse in the middle. Thus, the practical definition of "stale" aligns well with content that is both rarely attended and infrequently re-opened by agent tool actions.
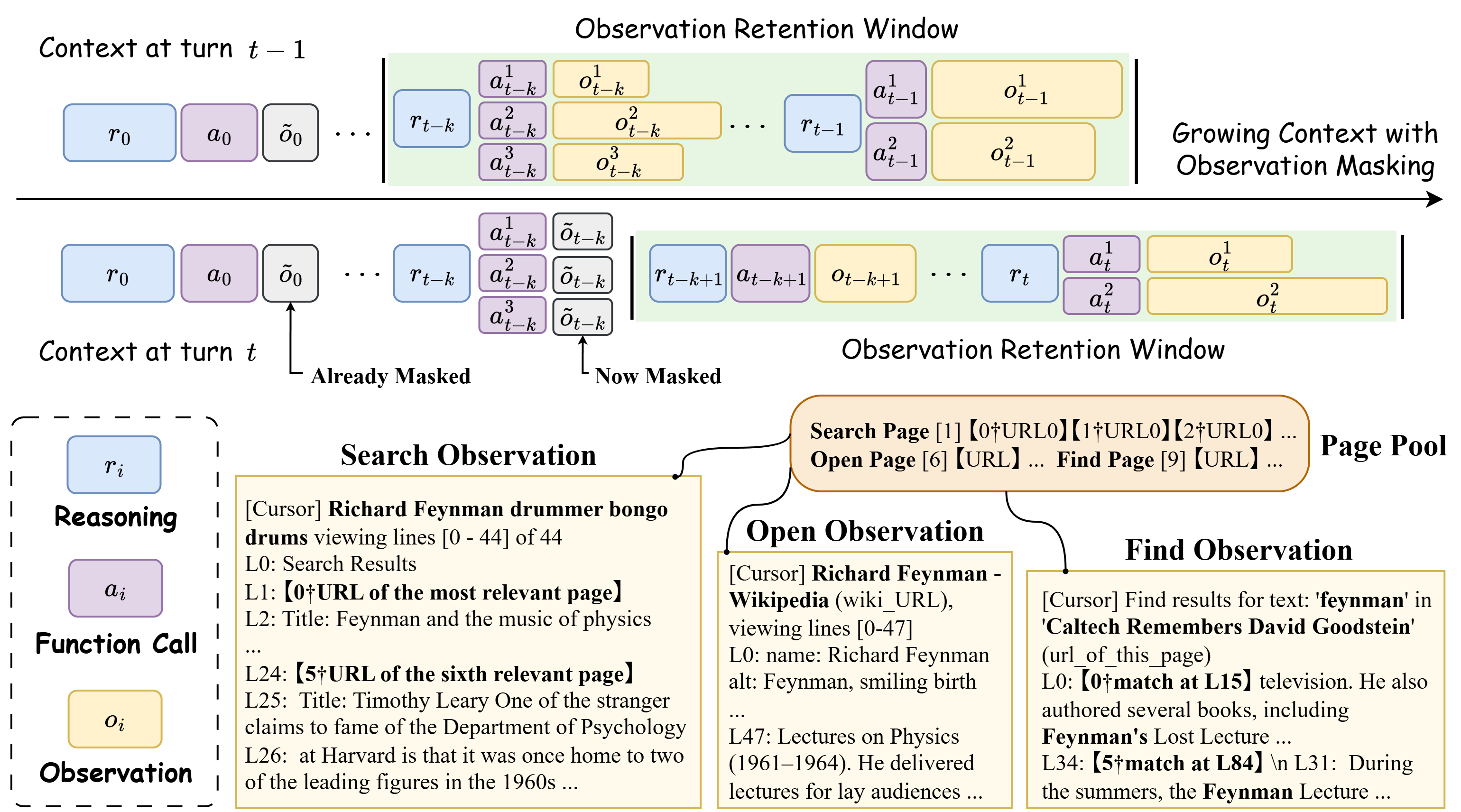

Figure 3: Left: Turn-based observation masking strategy; Right: Observation tokens dominate context size and are thus the main compression target.
Masking stale observations, retaining only the recent K observations per turn, thus serves as an efficient diagnostic probe for when unused context can be pruned without loss—and when such pruning collides with still-useful evidence, harming advanced models.
Empirical Results: Benchmark Sweep
Benchmarking on BrowseComp-Plus, GAIA, xBench-DeepSearch, and BrowseComp-ZH, the authors perform a methodical sweep over model–retriever pairs. The accuracy gains from masking—and the trajectory-level cost in additional tool calls—are summarized by regime:
- Retriever bottleneck: Modest gains (+6 points), dominated by retrieval failure.
- Mismatch peak: Maximal gains (exceeding +10 points; e.g., Qwen3.5-35B-A3B + AgentIR), trade retrieval recall for model filtering deficit.
- Saturation collapse: Gains evaporate or become negative; e.g., Tongyi DeepResearch and GPT-OSS-120B see ΔAcc. near zero or negative, accompanied by a surge in tool usage (+∼70 calls/query).
The observed effect size is not merely a function of scale: models with comparable parameter counts but different training regimes fall into different bands depending on their context-filtering ability and the signal–noise structure conferred by the retriever.
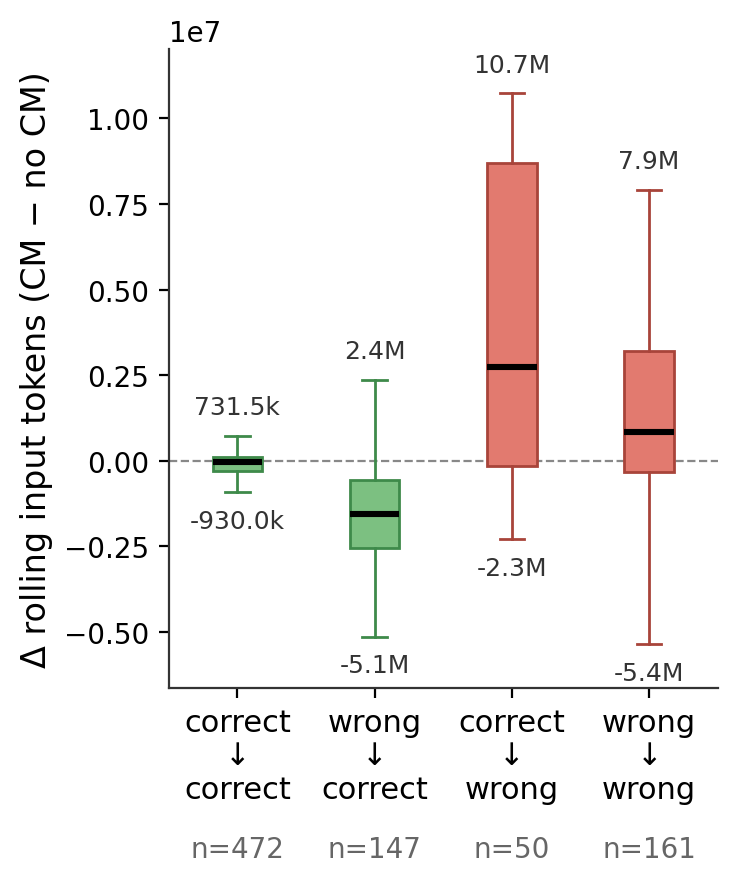
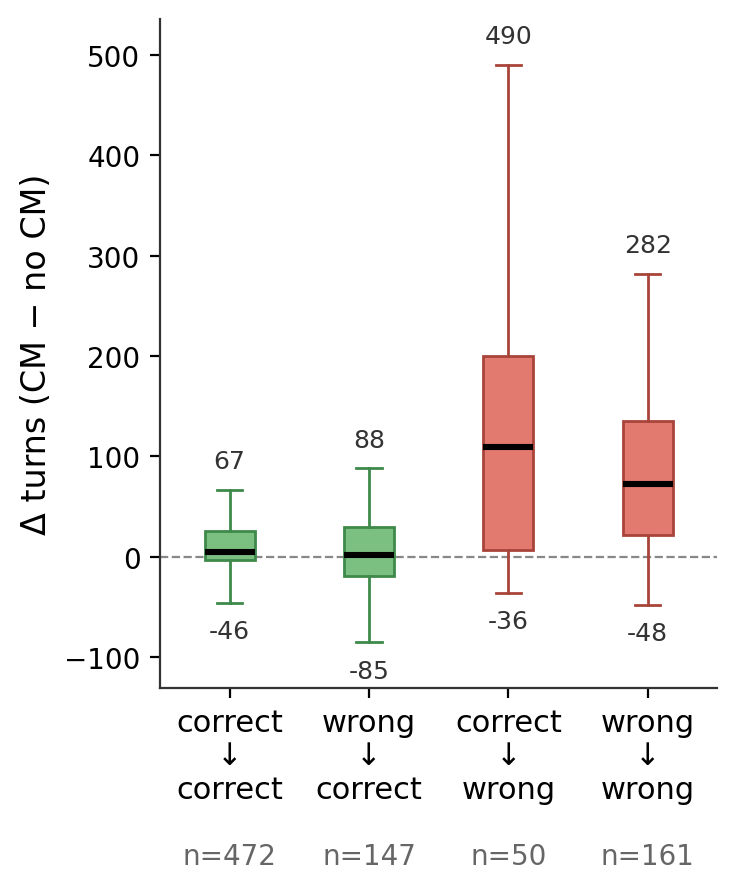
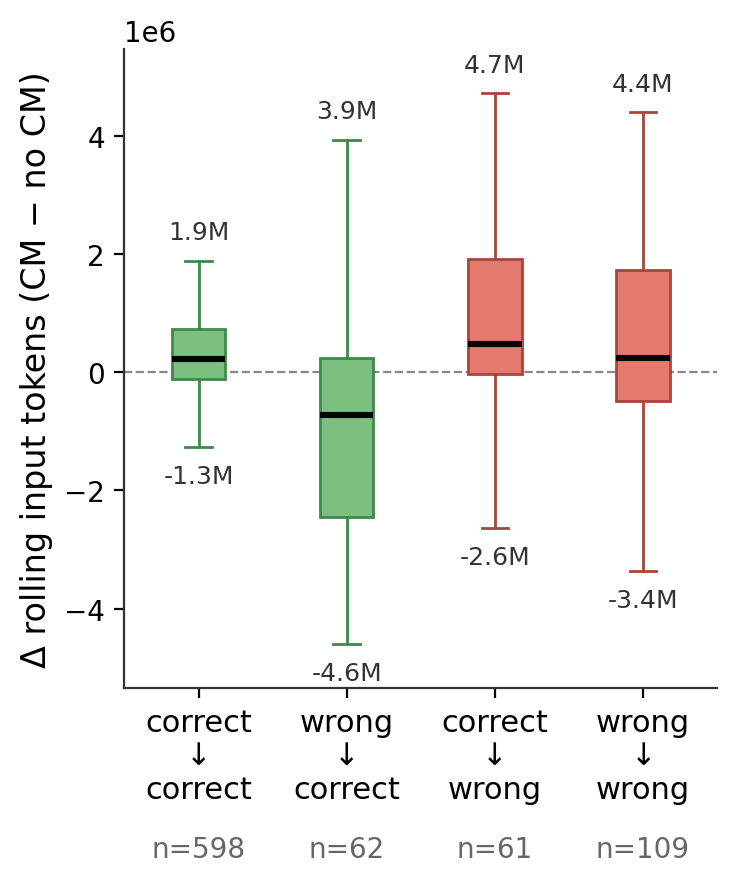
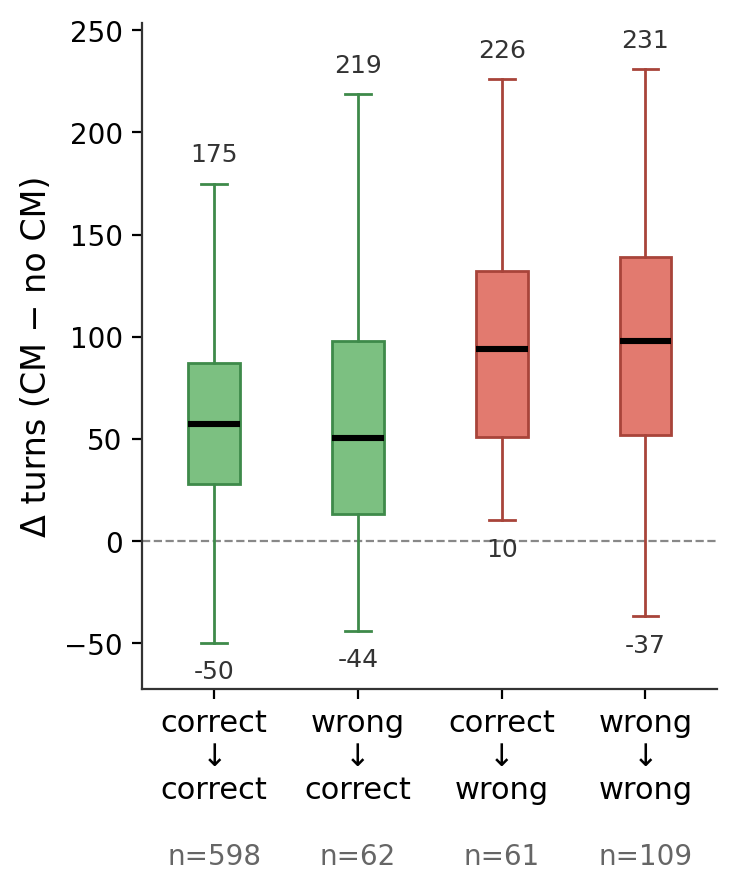
Figure 4: Masking reduces input context and turn count for rescued queries but dramatically increases both for degraded cases.
At a per-query level, CM "fixes" and "breaks" can be examined: corrected queries see lower rolling token consumption and turn counts, while degraded queries pay a substantial efficiency penalty.
Regression Analysis and Rescue Predictors
The authors extend beyond retrospective analysis using a regression probe to analyze prefix SNR and input complexity, identifying the subset of queries most likely to benefit from CM. Specifically, high input complexity with low SNR (evidence density) is predictive of CM rescue—although for saturated models, the rescued subset is sharply separable but small, explaining why net utility remains low. Scenarios where no rescue is possible (due to retriever limitations) see flat accuracy gains.
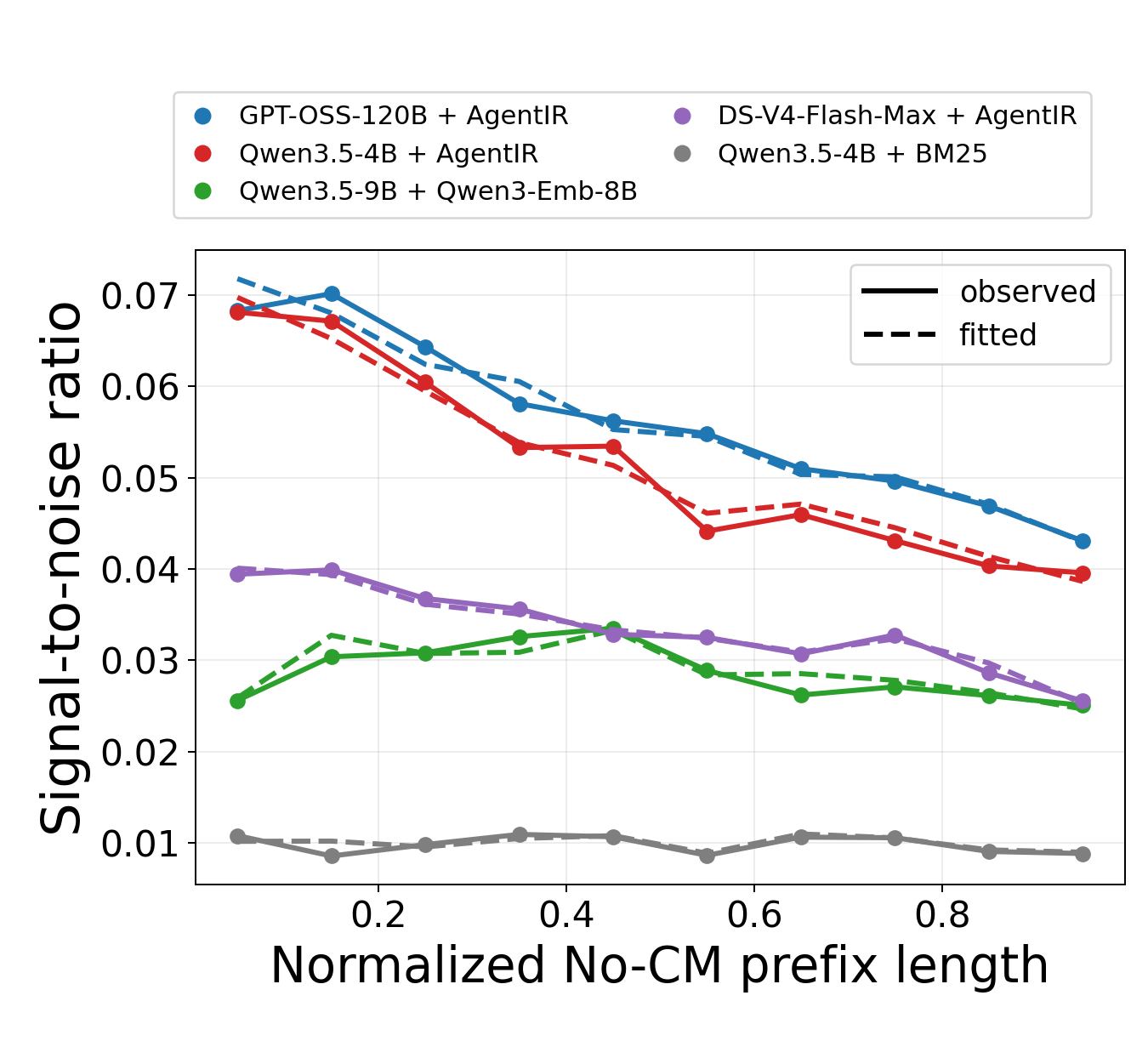
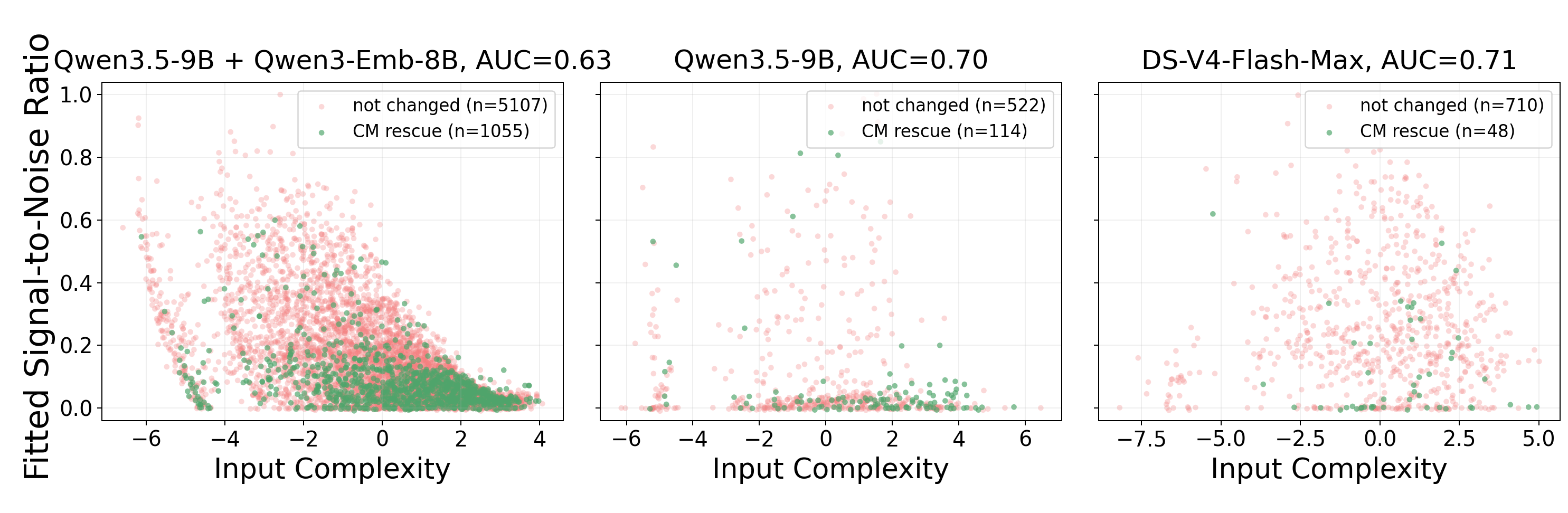
Figure 5: Probes showing fitted SNR and rescue separability across model–retriever regimes on offline and live-web tasks; AUC quantifies the ease of ex ante rescue prediction.
Scaffold and Context Management Policy Design
Engineering details matter: the scaffold decouples persistent page pool from the token-budgeted context, allowing re-referencing of any retrieved content even after masking. This mirrors designs from MemGPT-style systems, but in a diagnostic-minimal setting without online summarization or heuristic pruning. Ablations demonstrate that accurate error retention (do not mask tool-call errors) and absolute-URL rendering substantially reduce open errors.
Implications and Future Directions
This work has clear implications for agent system design:
- No universal rule: Observation masking is not a free performance gain; it is only advantageous in the intermediate regime where retrieval outpaces inference.
- Diagnostics > Heuristics: Ex ante probes can predict rescue cases, emphasizing the need for context management policies adaptive to model/retriever proficiency.
- Retriever optimization: For advanced models, improving retriever relevance (rather than pruning context) sets the achievable upper bound, as masking offers diminishing or negative returns.
- System co-design: Baseline scaffold proficiency directly impacts measured CM gains; poor system design artificially inflates the benefit of pruning interventions.
The theoretical implication is that CM utility is a function not of model scale, but of the model's dynamic context filter—how well it localizes and exploits sparse evidence in high-SNR/high-noise situations. This paradigm will guide future research into adaptive, possibly semantic- or attention-guided masking that seeks to maintain gains in the mismatch regime while avoiding the saturated regime collapse.
Conclusion
The paper provides a definitive empirical and mechanistic assessment of observation masking in agentic search agents. Rather than advocating universal masking, it delineates precise regimes where CM is beneficial, entirely dependent on the interaction of retrieval recall and model filtering. The findings advocate for system-level calibration of context management, adaptive strategies, and an engineering focus on retrieval signal quality as agents approach saturation. The regime-mapped understanding will inform future development of context-aware and budget-efficient agentic search solutions.