$k$NNProxy: Efficient Training-Free Proxy Alignment for Black-Box Zero-Shot LLM-Generated Text Detection
Published 2 Apr 2026 in cs.CL | (2604.02008v1)
Abstract: LLM-generated text (LGT) detection is essential for reliable forensic analysis and for mitigating LLM misuse. Existing LGT detectors can generally be categorized into two broad classes: learning-based approaches and zero-shot methods. Compared with learning-based detectors, zero-shot methods are particularly promising because they eliminate the need to train task-specific classifiers. However, the reliability of zero-shot methods fundamentally relies on the assumption that an off-the-shelf proxy LLM is well aligned with the often unknown source LLM, a premise that rarely holds in real-world black-box scenarios. To address this discrepancy, existing proxy alignment methods typically rely on supervised fine-tuning of the proxy or repeated interactions with commercial APIs, thereby increasing deployment costs, exposing detectors to silent API changes, and limiting robustness under domain shift. Motivated by these limitations, we propose the $k$-nearest neighbor proxy ($k$NNProxy), a training-free and query-efficient proxy alignment framework that repurposes the $k$NN LLM ($k$NN-LM) retrieval mechanism as a domain adapter for a fixed proxy LLM. Specifically, a lightweight datastore is constructed once from a target-reflective LGT corpus, either via fixed-budget querying or from existing datasets. During inference, nearest-neighbor evidence induces a token-level predictive distribution that is interpolated with the proxy output, yielding an aligned prediction without proxy fine-tuning or per-token API outputs. To improve robustness under domain shift, we extend $k$NNProxy into a mixture of proxies (MoP) that routes each input to a domain-specific datastore for domain-consistent retrieval. Extensive experiments demonstrate strong detection performance of our method.
The paper introduces kNNProxy, a training-free framework employing kNN retrieval to align proxy and source LLMs for zero-shot detection of LLM-generated text.
It integrates a mixture-of-experts design with domain-specific datastores and adaptive hyperparameters to enhance robustness across topics and source shifts.
Empirical results show significant improvements, with an average AUROC of 0.99 and strong closed-set attribution accuracy, demonstrating practical forensic utility.
kNNProxy: Efficient Training-Free Proxy Alignment for Black-Box Zero-Shot LLM-Generated Text Detection
Problem Formulation and Motivation
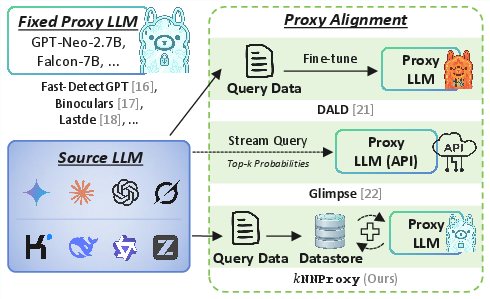
The detection of LLM-generated text (LGT) is crucial for digital forensics, academic integrity, and countering LLM misuse, especially under black-box assumptions where the source LLM is proprietary or unknown. While zero-shot detection methods obviate the need for classifier training, their effectiveness hinges on the representational alignment between a fixed proxy LLM and the often-inaccessible source LLM. Prior work addresses this alignment via supervised fine-tuning (e.g., DALD) or repeated API queries (e.g., Glimpse), but these solutions entail substantial computational and financial costs, limited robustness under domain and distribution shift, and reliance on API endpoints subject to silent change.
Methodology
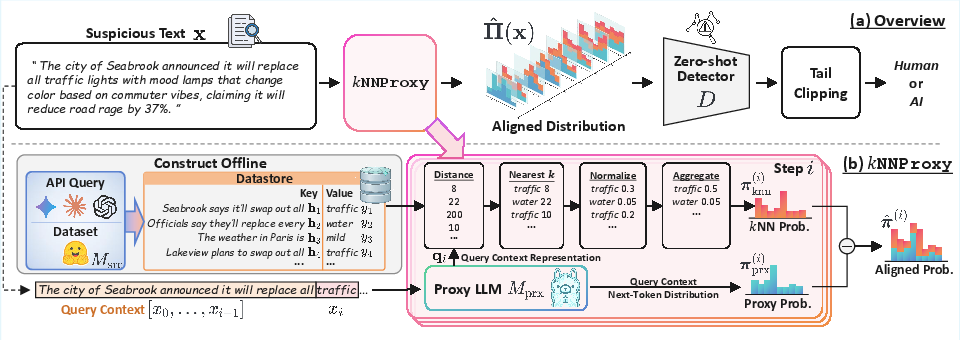
The authors introduce kNNProxy, a training-free, query-efficient framework that leverages kNN-LM (nearest neighbor LLMs) retrieval as a domain adaptation module layered atop a fixed proxy LLM. The core innovation is to construct an offline datastore from a corpus reflective of the target LLM. At inference, for each token position of a suspicious input, the framework retrieves contextual neighbors from the datastore, infers a retrieval-based token distribution, and interpolates this with the proxy's own distribution. The result is a robust, source-aware aligned distribution that feeds into standard zero-shot detectors such as Fast-DetectGPT and Binoculars.
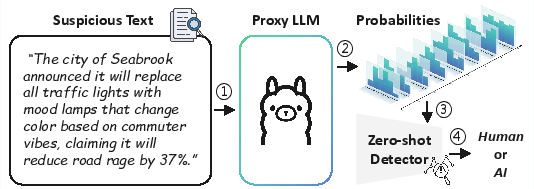
Figure 1: Pipeline of zero-shot LGT detection; a proxy LLM provides token-level distributions processed by a zero-shot detector for LGT decision.
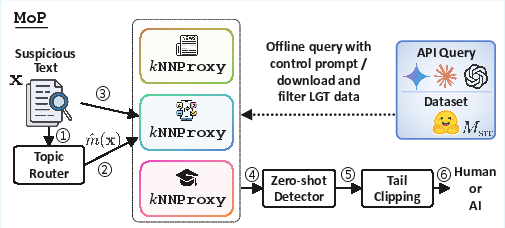
A key technical advancement is the mixture-of-experts extension (MokNNProxy): Multiple domain-specific datastores are built, and a router (based on nearest neighbor routing in sentence embedding space) dispatches each input to the most compatible expert. This modular approach accommodates domain and topic shift without retraining or continuous API access.
Figure 2: Illustration of proxy alignment; kNNProxy augments a fixed proxy using a corpus-supported datastore, supplanting repeated API queries or fine-tuning.
Figure 3: (a) Overview of kNNProxy, aligning proxy distributions at the token level; (b) kNN module blends proxy and retrieval output via nearest-context interpolation.
Figure 4: Schematic of mixture-of-proxy approach, with a lightweight router ensuring domain-consistent retrieval across multiple experts.
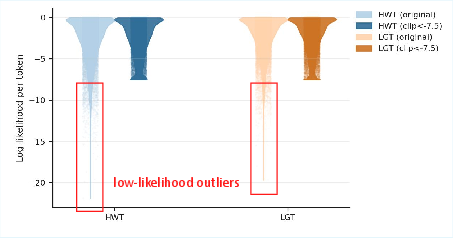
Statistical robustness is further enhanced by a lower-tail clipping strategy in token aggregation: rather than averaging token log-likelihoods, extreme outlier values (which may be spurious artifacts of the proxy’s limitations) are clipped, yielding a more reliable sequence-level detection statistic.
Figure 5: Distribution of per-token log-likelihoods with and without tail clipping, highlighting outlier suppression in the LGT/human separation.
Theoretical Guarantees
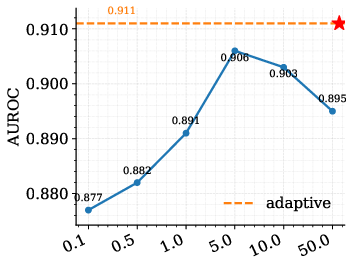
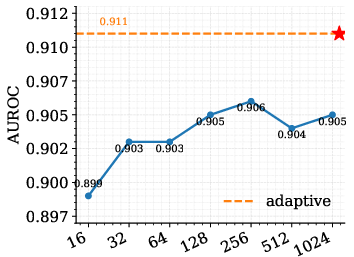
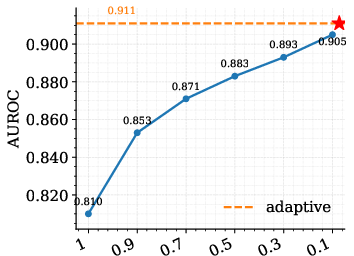
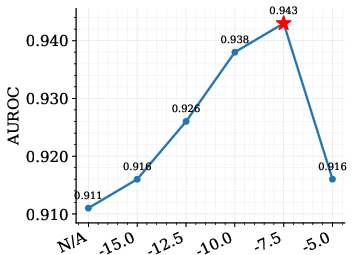
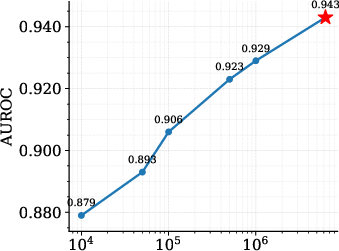
The paper presents a high-probability L1 error bound characterizing the discrepancy between the source and retrieval-induced distributions. The bound decomposes into a bias term (local smoothness, scaling with effective neighborhood radius reff) and a variance term scaling as 1/keff, where k0 is the effective number of neighbors. This analysis motivates tokenwise adaptive hyperparameters for neighbor size (k1), temperature (k2), and blending weight (k3), optimizing local bias-variance trade-off at each token.
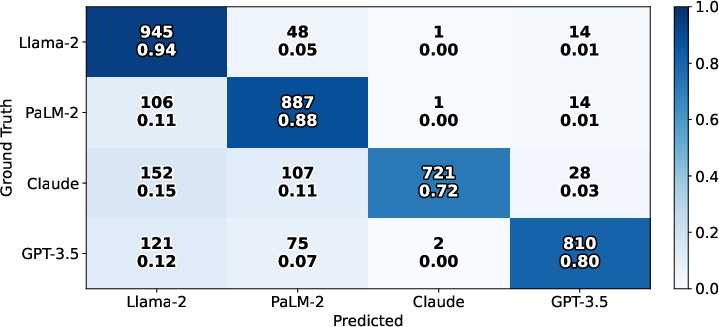
Figure 7: Confusion matrix for MoE routing; high topic-level accuracy demonstrates effective expert selection under domain shift.
Empirical Results
Extensive evaluation on recent challenging LGT benchmarks (Mix8, DetectRL) demonstrates:
Average AUROC of 0.99 across eight recent proprietary LLMs, exceeding state-of-the-art proxy alignment by 6.45 percentage points.
Robustness to both topic and source-model shifts as well as adversarial attack perturbations.
Strong LLM source attribution: mean accuracy of 0.84 in closed-set settings.
Ablation studies reveal that corpus quality, prompt template, and proxy architecture (e.g., Falcon-7B-Instruct vs. Llama-2) all influence performance, with larger, higher-quality datastores yielding improved alignment and stability.
Figure 8: Visualization of token-level log-likelihoods with and without k4NNProxy alignment; retrieval corrects proxy mis-calibration and accentuates LGT/human separability.
Implications and Future Directions
The k5NNProxy framework establishes that retrieval-augmented, training-free adaptation suffices to achieve robust alignment between fixed proxies and arbitrary black-box LLMs for zero-shot LGT detection and beyond. The modularity and efficiency (no fine-tuning or continual API querying required) substantially lower operational overheads, while the theory-driven hyperparameter adaptation offers a rigorous path toward scaling across domains, corpora, and proxy LLMs.
On the theoretical front, the derived error bounds lay a foundation for future work on instance-optimal, local adaptation strategies, further mitigating distributional mismatch in forensic settings.
Practically, Mok6NNProxy's multi-expert design is attractive for real-world deployment, where LLMs, topics, and user bases evolve. The core methodology can be repurposed for related forensic and attribution tasks, such as LLM fingerprinting, traceability of generated content, and auditing for post-edit or evasion attacks.
Conclusion
k7NNProxy provides a theoretically-grounded, training-free, and query-efficient framework for bridging the proxy-source gap in black-box zero-shot detection of LLM-generated text. Its retrieval-based alignment, multi-domain robustness, and adaptive hyperparameter tuning advance the state-of-the-art in robustness, efficiency, and generalizability for modern text forensics and LLM compliance enforcement (2604.02008).