- The paper introduces GLIDE, a comprehensive library for prediction-powered inference that leverages scarce human labels and abundant proxy predictions to produce unbiased estimates.
- It integrates state-of-the-art estimators and diverse samplers, achieving up to a 33% reduction in confidence interval width at high proxy correlation for robust evaluation.
- Empirical validation demonstrates significant annotation efficiency gains and consistent coverage, crucial for reliable performance in high-stakes agentic systems.
Industrializing Prediction-Powered Inference: The GLIDE Library for Reliable GenAI and Agentic Systems Evaluation
Motivation and Problem Statement
The evaluation of agentic systems, particularly those deployed in domain-specific and high-stakes environments, demands unbiased performance estimates with valid uncertainty quantification. Standard approaches—full human annotation versus LLM-as-judge proxies—incur prohibitive annotation costs or suffer from systematic bias. Prediction-powered inference (PPI) bridges this dichotomy by combining scarce, expensive human labels with abundant, inexpensive proxy predictions to generate debiased estimates and valid confidence intervals, regardless of proxy quality. Prior implementations are fragmented across disparate papers and repositories, impeding widespread practical adoption.
GLIDE Framework Architecture
GLIDE (Generated Label Inference and Debiasing Engine) systematizes the evaluation workflow for mean estimation tasks through modular sampling, annotation, and estimation components, each implemented via a scipy-style API to maximize interoperability and extensibility.
GLIDE consolidates state-of-the-art PPI estimators (PPI++, Stratified PPI++, Predict-Then-Debias (PTD), Active Statistical Inference (ASI)) and samplers (uniform, stratified, active, cost-optimal) with reproducible validation notebooks for statistical coverage, interval width, and effective sample size benchmarking. The empirical decision tree formalizes protocol selection, optimizing statistical efficiency and coverage criteria based on dataset structure and available signals.
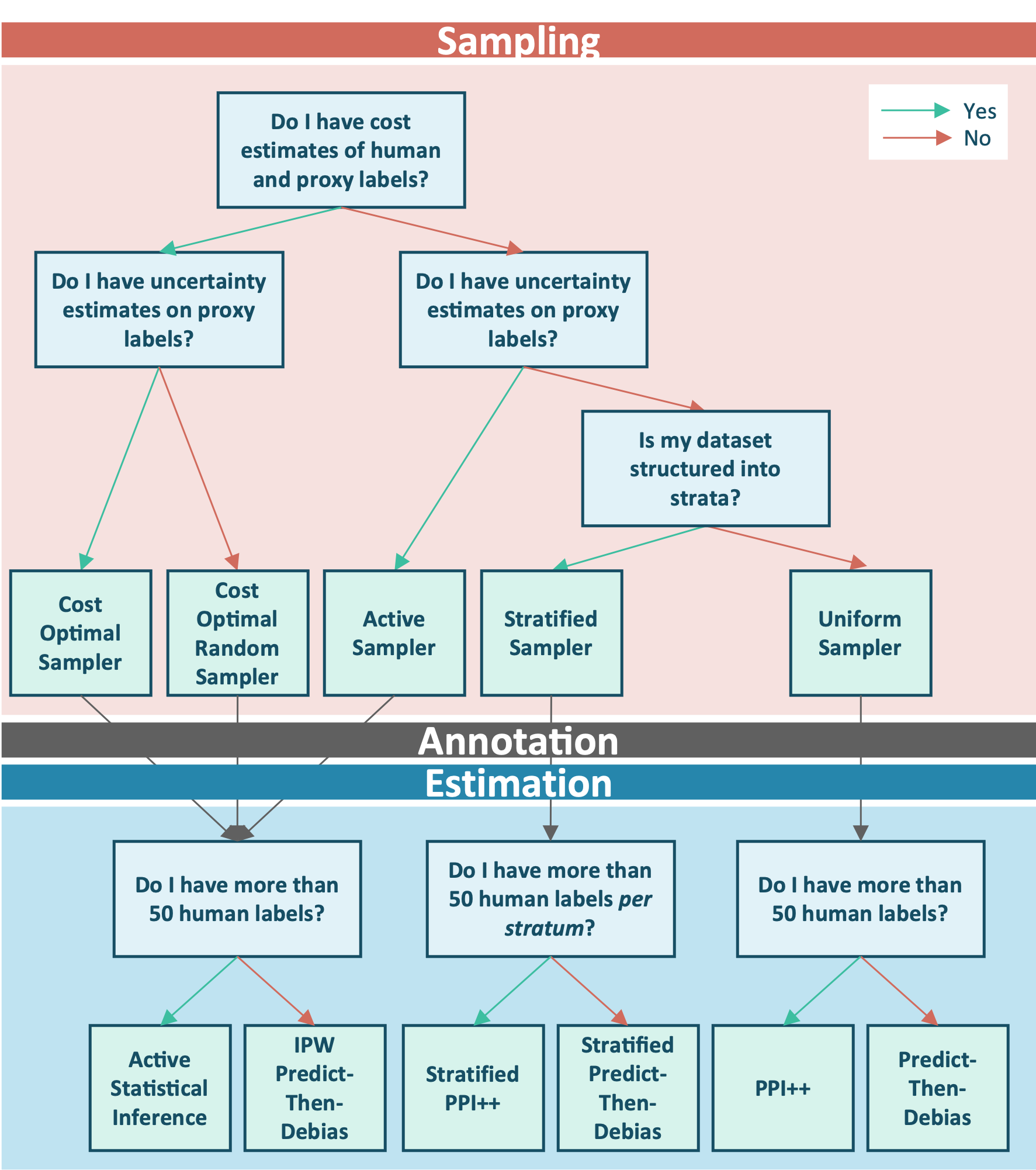
Figure 1: GLIDE decision tree for selecting sampler and estimator based on cost estimates, proxy uncertainties, natural strata, and annotation budget.
Statistical Foundations
GLIDE targets mean estimation θ⋆=E[Y], leveraging a small labeled set L and a large unlabeled set U with proxy values f(X). The classical PPI estimator removes proxy bias via rectification, while PPI++ introduces a tuning parameter λ, minimizing variance and ensuring optimality irrespective of proxy informativeness. Confidence intervals are CLT-based for n≳50 or require bootstrap-based PTD variants for n<50.
GLIDE generalizes to stratified populations, active sampling driven by per-sample proxy uncertainty, and cost-aware allocation. Effective sample size (neff) quantifies annotation savings, scaling directly with proxy/ground-truth correlation.
Design Justifications for Agentic Evaluation
Agentic systems are characterized by extreme annotation cost asymmetry, natural stratification, availability of proxy uncertainty signals, and consequential deployment requirements. Each dimension is addressed by specialized GLIDE samplers and estimators: cost-optimal sampling for annotation budget reduction, stratified PPI for heterogeneous proxy quality, ASI for uncertainty-driven label acquisition, and unconditional distribution-free coverage for deployment-level auditability.
Empirical Validation
A comprehensive Monte Carlo validation suite demonstrates PPI-based methods guarantee nominal confidence interval coverage independent of proxy quality, unlike the proxy-only baseline which collapses to near-zero coverage.
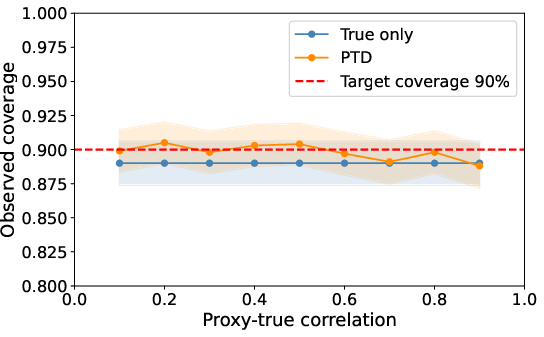
Figure 2: Empirical coverage of PTD versus proxy/true correlation; PTD and labeled-only baseline consistently achieve target coverage.
Interval width contracts monotonically as proxy quality improves, with PTD yielding a 33% reduction at correlation ρ=0.9 relative to the classical estimator.
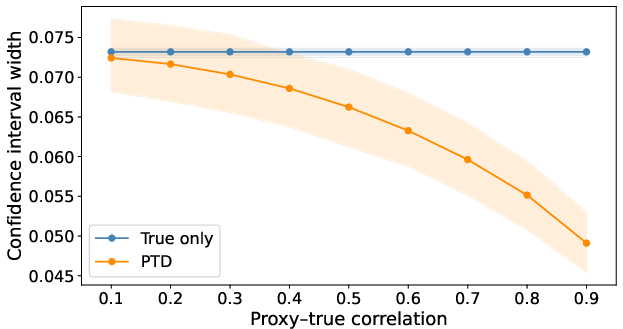
Figure 3: Confidence interval width decreases with proxy quality, matching labeled-only baseline at low correlation.
Effective sample size quantifies annotation savings: with 500 human labels and 1000 proxy-labeled points at ρ=0.9, statistical power more than doubles.
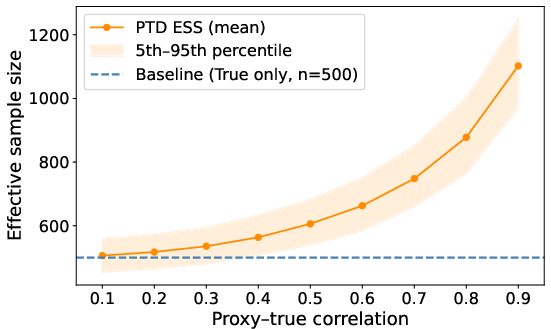
Figure 4: Effective sample size (L0) increases sharply with proxy/true correlation under PTD.
Case Study: Agentic Evaluation Benchmark
On R-Judge, a public agentic trajectory safety benchmark, GLIDE is benchmarked using claude-sonnet-4-6 as proxy and human expert annotations as ground truth. The proxy exhibits substantial bias (L113 pp), yet all labeled-data protocols including PPI++, Stratified PPI++, and ASI recover nominal empirical coverage across a suite of confidence levels.
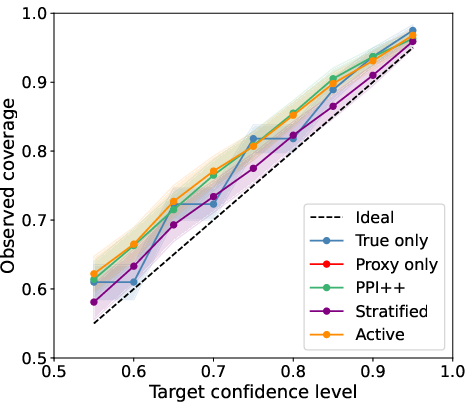
Figure 5: Empirical coverage for five protocols on R-Judge; all labeled-data methods achieve nominal levels, proxy-only fails.
At the 90% confidence level, GLIDE protocols reduce confidence interval width by 16–20% compared to classical sampling, effectively doubling annotation efficiency.
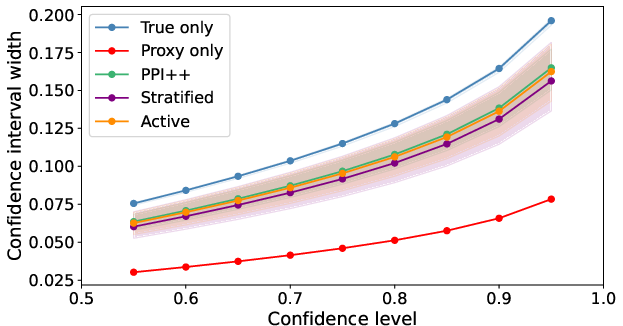
Figure 6: Confidence interval width for GLIDE protocols versus labeled-only baseline as function of confidence level.
The case study underscores that stratification on semantically meaningful axes and proxy uncertainty–driven active sampling both deliver competitive annotation efficiency gains.
Implications, Limitations, Roadmap
GLIDE operationalizes prediction-powered evaluation for mean estimation metrics, thus directly supporting model accuracy, risk, and deployment monitoring in scalable, auditable fashion. Strong empirical results validate unconditional coverage and annotation savings, but GLIDE is deliberately scoped to mean/proportion metrics, omitting quantiles, GLM coefficients, and multi-annotator modeling.
Immediate directions include multi-proxy aggregation, anytime-valid inference, and models for annotator disagreement, addressing broader evaluation requirements in GenAI and agentic systems.
Conclusion
GLIDE unifies modern PPI estimators and samplers for reliable, annotation-efficient mean estimation in agentic and GenAI system evaluation. Empirical benchmarks demonstrate substantial annotation budget savings and robust coverage properties, directly linking proxy quality to evaluation efficiency. The GLIDE library is released open source with reproducible notebooks, lowering the barrier for rigorous, scalable evaluation in practical deployments.