- The paper introduces a dual-stream MM-DiT architecture that fuses linguistic and environmental features via cross-attention and a domain-specific REPA loss.
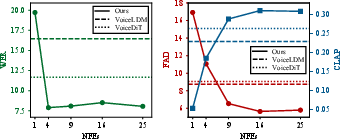
- It demonstrates significant performance improvements, achieving lower WER and FAD with only 25 sampling steps compared to 200 in baseline models.
- The method enables controllable TTS synthesis by balancing speech naturalness with coherent environmental integration.
ImmersiveTTS: Multimodal Diffusion for Environment-Aware Text-to-Speech with Domain-Specific Representation Alignment
Problem Setting and Motivation
Environment-aware text-to-speech (TTS) remains a challenging subdomain of neural generative modeling due to the necessity of synthesizing intelligible speech alongside semantically coherent and acoustically integrated environmental audio. Contemporary TTS systems typically segregate the modeling of speech from ambient context, resulting in poor cross-modal coherence and diminished realism when synthesizing immersive scenes. While recent multimodal and unified audio generation systems have attempted to bridge the gap, they frequently fall short in capturing fine-grained linguistic structure and in fusing environmental semantics with speech content.
ImmersiveTTS targets this problem through an explicitly cross-modal architecture, leveraging multimodal diffusion transformers (MM-DiT) and a dual-stream backbone to facilitate interaction between linguistic and environmental representations. Further, a domain-specific representation alignment (REPA) loss, driven by self-supervised speech- and audio-specialized encoders, is introduced to regularize learning and enforce semantic and acoustic consistency.
Methodology
Architecture
ImmersiveTTS is built upon a dual-stream MM-DiT backbone (Figure 1), adapted from prior image-text integration work, but here tailored for the complex interplay of speech and environmental context in audio synthesis. Content prompt-aligned linguistic features drive the speech stream, while Flan-T5 embeddings support fine-grained environmental sequencing in the environmental context stream, supplemented with CLAP for global environmental semantics. The two streams iteratively interact through joint cross-attention, enabling the speech generation process to adapt to, and integrate with, environmental cues at multiple levels of abstraction.
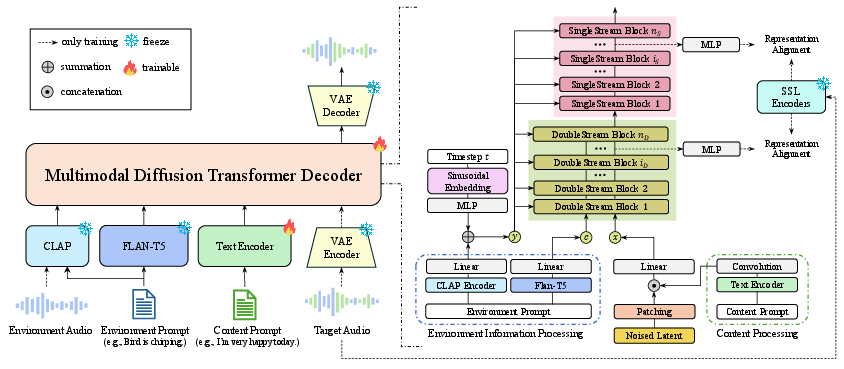
Figure 1: The ImmersiveTTS architecture employs a dual-stream MM-DiT backbone to explicitly enable conditioning and interaction between linguistic content and environmental context for environment-aware TTS.
Double-stream DiT blocks facilitate early fusion and cross-modal alignment (Figure 2). After a dedicated phase of double-stream joint modeling, the speech pathway continues to single-stream DiT stages for fine-grained refinement driven by self-attention.
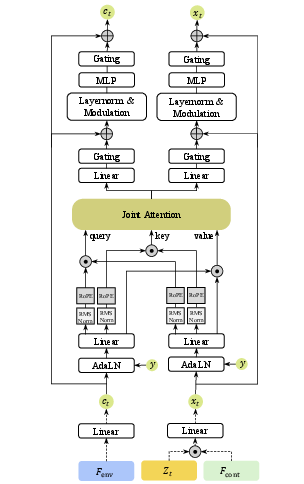
Figure 2: Double-stream DiT blocks perform initial cross-modal integration between speech and environment streams.
Conditioning and Feature Extraction
The environmental stream fuses global semantic context (via CLAP) and local detail (via T5 token embeddings), assigning them separately to AdaLN and sequence input, respectively. The speech pathway conditions the audio latents on transcript-aligned speech features (obtained via a text encoder and monotonic alignment search) and a convolutional mapping that aligns feature domains. This design supports controllable, highly intelligible speech generation aligned with both prompt content and environmental scene descriptions.
Training Objectives: Flow Matching and Domain-Specific REPA
The generative process is formalized as a flow matching ODE between latent Gaussian noise and the data manifold, trained with a rectified flow MSE criterion. Critically, ImmersiveTTS introduces domain-specific representation alignment: the REPA loss draws on frozen, self-supervised teacher encoders—WavLM for speech and ATST-Frame for audio. The model’s speech-side intermediate features are projected (via separate MLPs) into each teacher’s representation space and temporally aligned to form the REPA loss, which directly regularizes synthesis toward both linguistic and environmental ground-truth structure.
Inference and Conditional Generation
Dual classifier-free guidance (CFG) is used at inference, with independently tunable guidance weights for content and environmental streams. This enables flexible controllability over generated attribute fidelity (as analyzed in Figures 4 and 5).
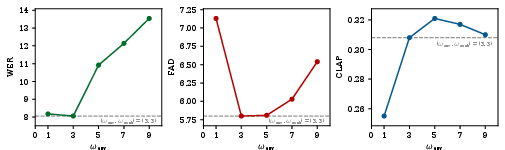
Figure 3: Objective evaluation for various environment guidance scales demonstrating the impact on intelligibility, audio quality, and text-audio alignment.
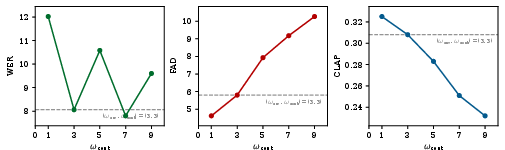
Figure 4: The impact of content guidance scale on generation trade-offs between WER, FAD, and CLAP.
Experimental Results
ImmersiveTTS is evaluated on AudioCaps and Seed-TTS benchmarks under subjective and objective criteria, including speech naturalness (SN-MOS), environment consistency (EC-MOS), overall naturalness (ON-MOS), word error rate (WER), Frechet audio distance (FAD), and CLAP alignment.
The following outcomes are emphasized:
Additional Analyses
Systematic studies on the impact of representation alignment position corroborate the importance of applying REPA at intermediate MM-DiT layers, further enhancing stability and domain-specific guidance. Dual CFG analyses show that overly strong environmental or content weighting can degrade overall quality, suggesting the importance of balanced settings for both intelligibility and scene realism.
Implications and Future Directions
ImmersiveTTS substantiates the efficacy of explicitly cross-modal, transformer-based fusion approaches in environment-aware TTS. The combination of MM-DiT dual-stream modeling and domain-specific REPA sets a rigorous foundation for further advances, enabling:
- More effective integration of uncontrollable or compositional environmental cues
- Efficient sampling consistent with recent progress in flow-based generative models
- Extensibility toward other multimodal tasks such as audio-visual speech synthesis and expressive prosody modeling
Remaining limitations include reliance on synthetic training mixtures and limited granular control of paralinguistic features (e.g., emotion or speaking style). Scaling to real-world, complex interaction scenarios with genuine, naturally recorded background contexts is a future avenue, alongside the integration of richer, controllable prosodic and emotional factors.
Conclusion
ImmersiveTTS achieves a new standard in unified, environment-aware TTS by leveraging MM-DiT dual-stream fusion and complementary domain alignment objectives, empirically establishing clear advances in both objective and subjective quality metrics. The architecture’s systematic fusion of transcript and environment conditioning, underpinned by self-supervised feature alignment, provides a robust architecture-level template for future scalable, multimodal, and highly controllable speech synthesis frameworks.
References
For the full technical details and evaluation, see "ImmersiveTTS: Environment-Aware Text-to-Speech with Multimodal Diffusion Transformer and Domain-Specific Representation Alignment" (2605.30965).