- The paper introduces VideoFDB, the first benchmark for full-duplex vision-speech interaction that evaluates both perception and generation in real time.
- It uses human-annotated dyadic video clips to assess 11 conversational dynamics, revealing significant discrepancies between human performance and current models.
- Experiments show that existing AV2A systems struggle with integrating visual cues, with cascaded speech-avatar architectures failing to produce timely nonverbal responses.
VideoFDB: Benchmarking Full-Duplex Vision-Speech Capabilities in Conversational Agents
Introduction
"VideoFDB: Evaluating Full-Duplex Vision-Speech Capabilities in Conversational Agents" (2605.30256) introduces the first evaluation benchmark specifically targeting conversational agents with full-duplex, real-time audio-visual interaction. Human face-to-face conversation is naturally full-duplex with simultaneous multi-channel perception (audio/visual inputs) and generation (verbal and non-verbal outputs), exhibiting overlapping speech, rapid gesture coordination, and nuanced turn-taking. As conversational AI moves toward deployment in high-bandwidth, embodied contexts (robots, XR, telepresence), systems must robustly interpret and produce these overlapping multimodal signals. However, existing benchmarks focus primarily on unimodal (speech-only) or turn-based audio-visual tasks, neglecting dyadic, overlapping conversational dynamics.
VideoFDB offers a new evaluation paradigm for agents that must manage incremental, continuous vision-speech input/output. The benchmark features 237 human-annotated dyadic video call clips capturing 11 carefully-chosen conversational dynamics (e.g., gaze aversion, nonverbal backchanneling, laughter, interruptions), supporting systematic scoring of both perceptual and generation behaviors. Notable are the separation of perception/generation axes, a rubric-based LM-as-judge framework with welldefined, interpretable axes for both timing and semantic quality, and rigorous experimental baselines.
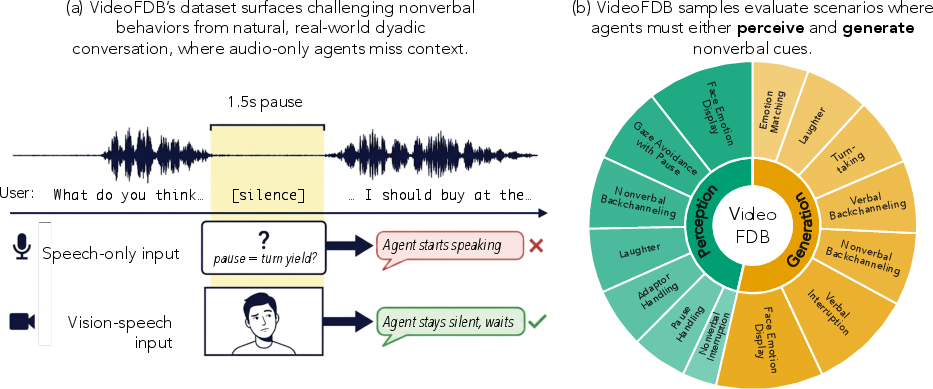
Figure 1: VideoFDB curates samples from natural dyadic conversations where visual cues contextualize the interaction, supporting evaluation across 11 categories capturing both simultaneous input and output.
Benchmark Design and Taxonomy
The VideoFDB dataset is constructed to reflect theoretically-grounded, ecologically valid conversational phenomena essential for fluent dyadic interaction, based on the communication literature. The taxonomy delineates conversational dynamics across the following axes:
- Perception: Does the agent correctly interpret user nonverbal cues and manage conversational flow (fluency, turn management, grounding in nonverbal event semantics)?
- Generation: Can the agent produce contextually appropriate, timely nonverbal cues (fluency, alignment of affect, cue appropriateness)?
Eleven distinct conversational dynamics are annotated (e.g., gaze avoidance, adaptors, nonverbal interruptions, emotion display, laughter, backchanneling, turn-taking), spanning both verbal and nonverbal regimes and covering both perception and generation. Every sample is human-annotated with precise event windows and rich metadata, and systematically reviewed with a multi-phase annotation pipeline.
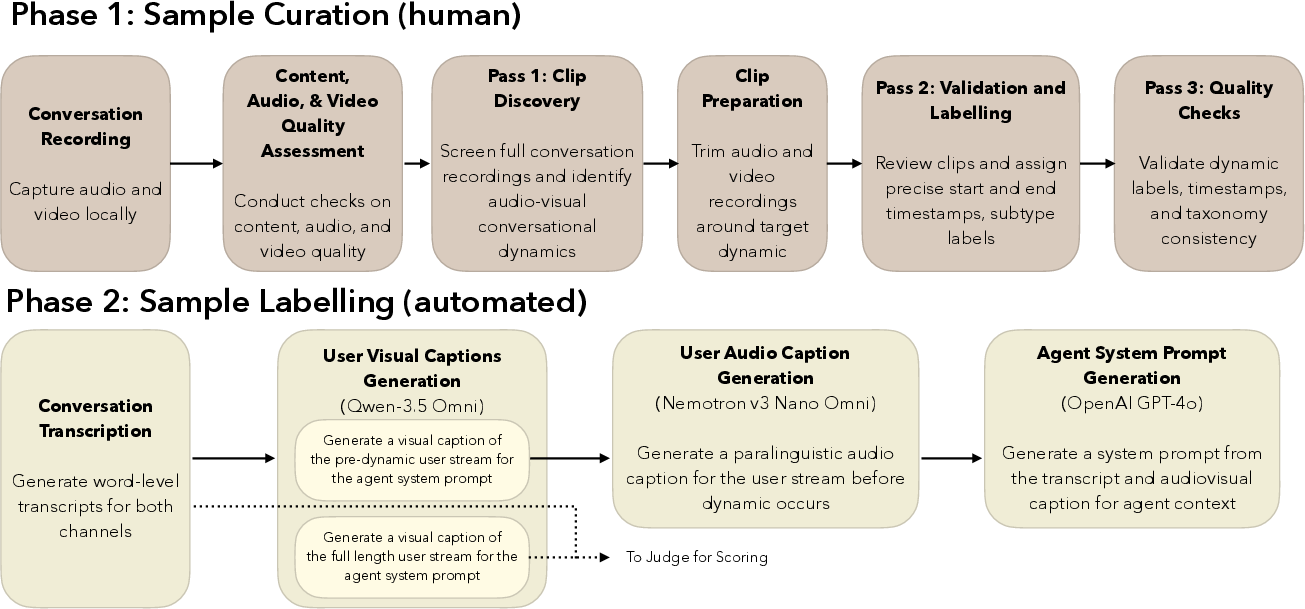
Figure 2: Annotation workflow: human annotators curate, review, and label salient clips; automated captioning generates contextual prompts for agent inference and LM-based evaluation.
The dataset is mined from natural video calls, focusing on ecological dyadic interaction. Sampling ensures diversity across age, gender, and affective states, and input streams are diarized to attribute each event accurately.
Evaluation Protocol
VideoFDB critically advances evaluation methodology via rubric-based large model (LM)-as-judge prompts, designed to capture the intrinsic variability and non-determinism of human conversation. Rather than relying on exact-match or per-turn correctness (insufficient in non-deterministic, high-context conversation), the benchmark rates agent performance on broad, interpretable axes:
- Fluency: Turn-taking, avoidance of talking over, and conversational naturalness.
- Conversational Flow: Correct floor management in response to user cues (yielding, holding, backchanneling).
- Semantic/Affective Grounding: Alignment to the meaning and affect of the user's nonverbal event, including timely mirroring or responding.
- Nonverbal Cue Appropriateness: For agents with visual generation, assessment of the appropriateness, timing, and quality of produced visual cues.
The evaluation flow streams AV input to the agent in real time, collects agent output, annotates temporal/semantic attributes, and inputs the result to a judge-LM that applies the rubrics.
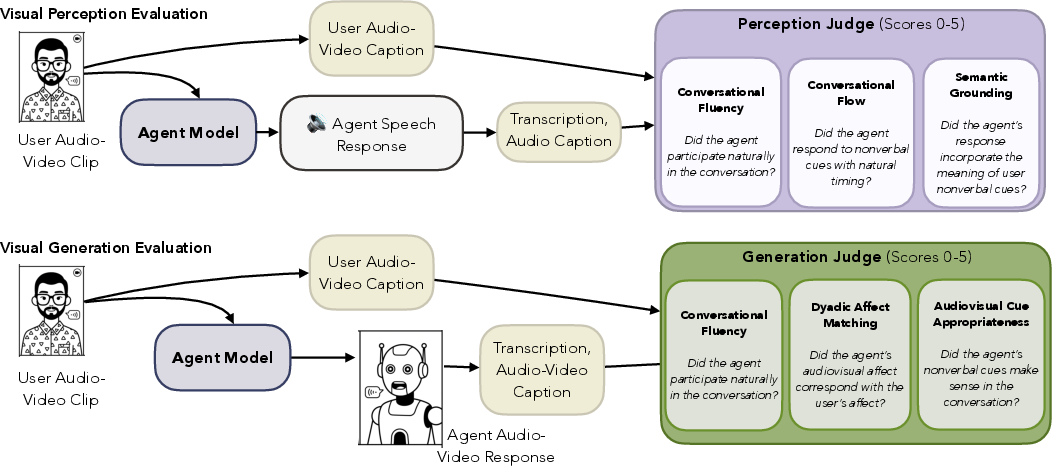
Figure 3: Evaluation flow: agent-generated AV output with annotated captions is fed to LM-judge prompts, producing interpretable, category-specific scores.
Timing alignment is quantified with a generalized Takeover-Rate Alignment (TOR-Alignment) metric, unifying heterogeneous timing goals across dynamics (stay silent, yield, continue, backchannel), with median latency and class-specific behavioral thresholds. This enables direct, unified reporting on both audio and visual time-critical behaviors, which is essential for benchmarking full-duplex systems.
Experimental Results
The suite of baselines evaluated spans closed- and open-source full-duplex vision-speech (AV2A), audio-only speech (A2A), and cascaded speech-to-avatar (A2AV) pipelines. Systematic performance breakdowns expose the following critical findings:
- Human–model gap remains large: No evaluated model approaches human ground truth across VideoFDB’s perception or generation rubrics, with the largest discrepancies in rapid-turn or overlapping regimes (e.g., nonverbal interruption, pause handling).
- Visual stream is under-leveraged: Most AV2A systems either ignore the visual stream for joint conversational grounding or default to visual captioning behaviors when prompted with video input, instead of integrating the stream into incremental conversational logic.
- Captioning-collapse and disclaimers: Multiple models (notably MiniOmni2, VITA-1.5) respond almost exclusively in a captioning mode or issue blanket disclaimers in the presence of AV input—behavior not observed in their audio-only modes.
- Timing degrades with visual input: Adding video input does not reliably improve, and often degrades, timing alignment (lower TOR-Alignment, increased latency).
- Visual sampling frame rate is bottlenecked: Increasing FPS input (for MiniCPM-o-4.5) above 2 FPS causes both performance and fluency to drop, likely due to fusion or crossmodal attention saturation in present architectures.
- Cascaded speech–avatar pipelines are fundamentally limited: These architectures cannot insert nonverbal cues in real time during the user’s turn, and show large latency even for post-hoc gesture rendering; generation-appropriateness for nonverbal cues is especially poor compared to ground-truth human generation.
Full quantitative results are presented for all axes, supporting detailed per-dynamic error analysis. For example, MiniCPM-o-4.5 achieves the strongest open-source results but is still substantially below human baselines, especially for conversational flow and timing-sensitive categories. Large closed-source models (Gemini, GPT Realtime) exhibit similar bottlenecks.
Implications and Future Directions
VideoFDB exposes a critical gap for next-generation conversational AI: state-of-the-art foundation models—even in production proprietary systems with strong AV2A claims—fail to leverage visual conversational cues for incremental, overlapping, dialogically-appropriate behaviors. The dual failure modes (captioning collapse, visual-stream ignorance) reinforce that current architectures are either not sufficiently crossmodal grounded, or lack architectures for real-time incremental interplay between streams. Cascaded avatar systems cannot address this, as their architecture precludes online, within-turn visual cue generation.
This has significant practical implications for any AV conversational deployment in human–computer interaction, telepresence, service robotics, and embodied agents. Without robust full-duplex grounding, AI companions risk misalignment, unnatural conversation, and signal loss for crucial nonverbal cues central to rapport, engagement, and affect. Safety and usability for embodied conversational agents depend on tightly-coupled multimodal perception and actuation.
From a theoretical standpoint, VideoFDB concretely frames desiderata for full-duplex real-time AV2AV architectures, including joint streaming audio–visual fusion layers, incremental hierarchical fusion, and explicit temporal objectives. A shift in evaluation from static-task and turn-based to full-duplex, overlapping regimes is essential for progress beyond unimodal conversational AI.
Conclusion
VideoFDB establishes both a new standard and a new challenge for the evaluation of conversational agents in the AV2AV setting. Its comprehensive taxonomy, robust annotation methodology, and interpretable, rubric-based scoring protocol enable systematic, reproducible assessment of real-time nonverbal conversational skill. The reported empirical gaps spotlight fundamental challenges for contemporary architectures and motivate future research in truly multimodal, contextually and temporally grounded foundation models.
The release of VideoFDB will accelerate research toward robust, naturalistic, full-duplex conversational agents. Future work is needed to expand behavior coverage (additional body cues, multi-party multi-turn, multilingual domains), strengthen LM-based scoring with higher-fidelity and less biased judge models, and develop architectures that tightly couple audio–visual perception and actuation for natural realtime interaction. Rigorous, pre-deployment evaluation and explicit safety guardrails are advocated as such systems move into impactful real-world settings.