- The paper introduces a unified cross-modal attention mechanism with multi-head Gaussian kernels to balance precise lip sync and global temporal context.
- It employs dual-stream audio processors with learned Audio Q-Formers and arbitrary-position guided training to achieve high-fidelity talking and listening synthesis.
- Empirical evaluations demonstrate state-of-the-art performance in identity preservation, lip synchronization, and expressive motion using the newly created VoxHear dataset.
Interactive Talking-Listening Avatar Generation: A Technical Analysis
Motivation and Problem Statement
Contemporary audio-driven human video generation predominantly addresses monologue scenarios where an avatar articulates single-speaker audio, focusing on lip sync and expression realism. However, realistic human interaction is inherently full-duplex—active response to interlocutor audio is as vital as speaking. Existing approaches often handle this as a hard switch between talking and listening states or apply context-free, frame-local attention, which is inadequate for nuanced conversational dynamics. These strategies yield avatars incapable of overlapping speech or contextually aware, naturalistic reactions, especially at the upper-body or holistic gesture level.
Two primary challenges are identified: (1) the scale discrepancy between talking, which necessitates high-precision frame synchronization for lips, and listening, which requires broad temporal context for natural reactions; (2) a lack of high-quality, decoupled datasets with cleanly separated and synchronized audio tracks for both parties in conversation.
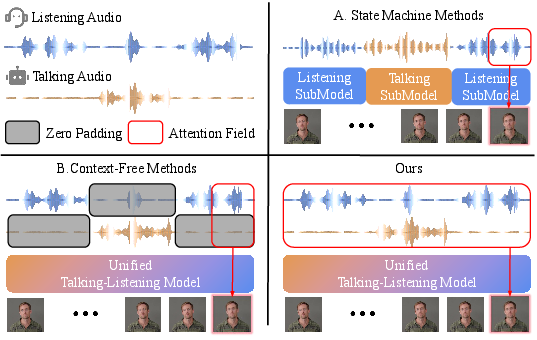
Figure 1: Visual schematic contrasting manual state-machine switching, context-free local attention, and the proposed globally aware, unified attention mechanism.
Unified Attention with Multi-Head Gaussian Kernels
To overcome the local-global trade-off, the paper introduces a unified cross-modal attention mechanism instantiated with Multi-Head Gaussian Kernels (MHGK). Standard 3D spatiotemporal attention architectures either overfit to local detail (improving lip sync but losing prosody and context) or to global context (degrading lip alignment). MHGK enforces differentiated receptive fields: heads with small Gaussian windows anchor precise audio-visual alignment, while broad heads model prosody and intent over long context.
The underlying mechanism employs Gaussian bias matrices per head to dynamically control attention decay with respect to temporal distance:
B(h)(i,j)=αh(1−exp(−2σh2(i−j)2))
Smaller σh enforces local, lip-specific attention; larger σh enables broad context aggregation. This paradigm realizes simultaneous local precision and global semantic incorporation without separate architectural paths or significant computational overhead.
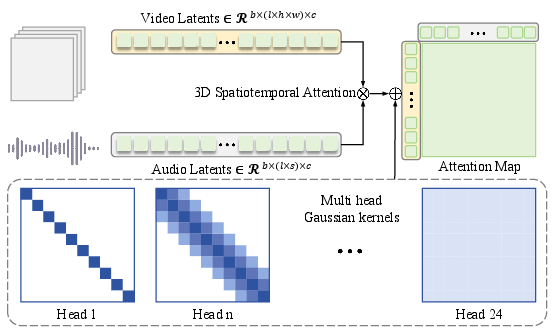
Figure 3: Multi-head Gaussian-constrained cross-modal attention delivers multi-scale temporal modeling for audio-visual fusion.
Dual-Stream Processing and Audio Injection
The backbone adopts the mid-sized Wan 2.2 5B latent video diffusion model and augments it for dual-stream talking-listening control. Talking and Listening audio streams, processed via learned Audio Q-Formers, undergo independent feature compression and alignment. This design choice permits adaptive fusion of phonetic detail (critical for speaking/talking) and semantic cues (imperative for listening/reacting), resolving representation redundancy and out-of-distribution risk present in Classifier-Free Guidance strategies.
The Q-Formers aggregate representations across all layers of a pre-trained Wav2Vec 2.0 encoder, project features into compact subspaces, and apply overlapping temporal windows for precise alignment to video frame latents. Independent weights for the two Q-Formers ensure appropriate specialization for Talking (precision lip sync) and Listening (reactive behaviors).
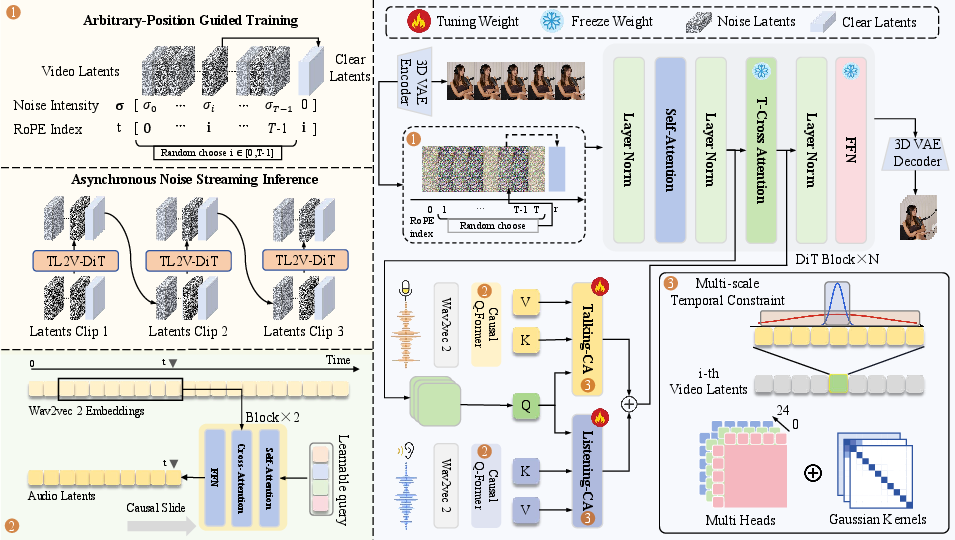
Figure 2: Framework architecture: dual-stream audio input, arbitrary-position guided training, and causal Q-Former integration.
Arbitrary-Position Guidance and Diffusion Forcing
A critical innovation is the arbitrary-position guided training protocol, where the guidance frame's position is randomized within the latent sequence during training. This approach prevents the "attention sink" effect observed in first/last-frame anchoring and improves both motion diversity and temporal coherence. Diffusion Forcing further enhances robustness by injecting noise at varying temporal windows, training the model to stably generate plausible content from any position. Empirical ablation identifies optimal guide indices, balancing identity preservation and dynamic extensibility.
High-Quality Dataset Construction: VoxHear
Current datasets such as Seamless and SpeakerVid-5M render data-driven full-duplex training impractical due to mingled, noisy, or unaligned audio tracks. The paper's VoxHear dataset—over 1,200 hours—addresses this gap. It employs a two-stage pipeline: spatial-temporal pruning for human-centric upper-body videos, then rigorous audio separation using MossFormer2 and SyncNet validation to maintain lip-audio coherence. The resulting quadruples (Va,Aa,Vb,Ab) provide a resource suitable for both single and dual-stream evaluation.
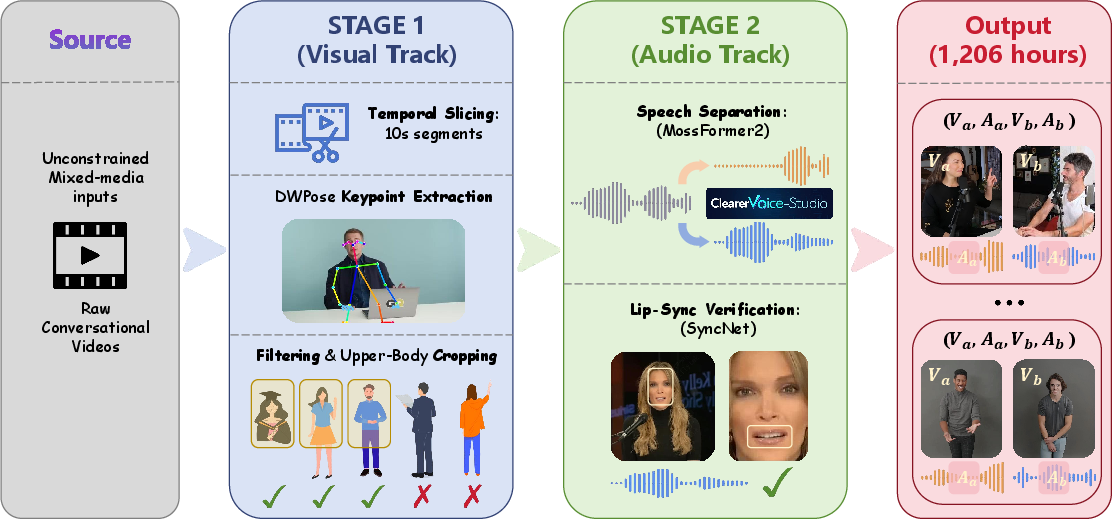
Figure 4: VoxHear dataset generation process, combining visual and audio filtering and synchronization.
Empirical Evaluation
Quantitative results demonstrate that the proposed framework achieves state-of-the-art metrics over strong baselines (OmniAvatar, EchoMimic-v3, StableAvatar, etc.) on HDTF and MEAD datasets for perceptual similarity, identity preservation, and lip synchronization.
Ablation analyses validate the advantage of the multi-scale Gaussian kernel in both lip sync accuracy and expressive motion, outperforming vanilla 2D CA, RoPE, and ALiBi-enhanced attention mechanisms. Arbitrary-position guidance is also shown to materially improve identity retention and video quality.
Qualitative studies illustrate robust handling of challenging cases such as full-duplex interaction and scenarios with only listening audio, demonstrating significant improvements over INFP and DIM, particularly in motion diversity, facial expressiveness, and the integrity of lip-articulation.

Figure 5: Qualitative comparison with baseline models; annotations highlight typical artifacts and misalignments in competing methods.

Figure 6: Listening-only scenario, showing natural, contextually appropriate head and body responses absent in prior approaches.

Figure 7: Full-duplex talking-listening outputs exhibit higher-fidelity pose dynamics and facial expressivity.
Theoretical and Practical Implications, Future Directions
The introduction of a parameter-efficient, unified attention kernel that explicitly encodes multi-scale temporal dependencies resolves longstanding trade-offs in multimodal, interactive generative modeling. This design not only improves realism and responsiveness in digital human communication agents but also proposes a generalizable inductive bias for other multi-resolution, multimodal mapping tasks.
Practically, this framework expands the applicability of digital avatars to more naturalistic virtual meetings, counseling agents, and bidirectional conversational UIs, especially when nuanced turn-taking, overlap, and cross-modal grounding are required.
Theoretically, the dual-stream Gaussian-constrained paradigm emphasizes the necessity of task-conditioned, multi-resolution modeling in paired sequence generation. The success of arbitrary-position guided training and diffusion forcing informs future asynchronous or streaming generation pipelines, particularly in scenarios requiring fast, non-autoregressive synthesis.
Conclusion
The paper presents a comprehensive framework for full-duplex interactive audio-driven human video generation, featuring a multi-head Gaussian attention kernel, adaptive audio Q-Formers, and an arbitrary-position guided training protocol. Empirical evaluations establish new state-of-the-art results across all evaluated benchmarks, substantiating the efficacy of explicit, multi-scale temporal constraints for joint talking-listening avatar synthesis. The public release of VoxHear establishes a high-quality foundation for future research in interactive digital humans, and the methodological advances are extensible to broader AI-driven human communication scenarios. Further research should investigate scalable, fully end-to-end instruction-to-behavior modeling and multimodal grounding beyond speech and video.