- The paper formalizes RAG design as an architecture search problem by introducing RAISE, a unified platform for systematic pipeline configuration and evaluation.
- It demonstrates that optimizer performance is highly environment-specific, with distinct algorithms excelling across different QA datasets.
- The framework promotes reproducible, modular benchmarking, encouraging detailed reporting of search spaces and optimization strategies in RAG research.
RAISE: Retrieval-Augmented Generation Design as an Architecture Search Problem
The paper "RAISE: RAG Design as an Architecture Search Problem" (2605.30029) conceptualizes the configuration of Retrieval-Augmented Generation (RAG) pipelines as an architecture search problem, moving beyond heuristic-based hyperparameter tuning. The authors introduce the RAG Intelligence Search Engine (RAISE), a unified platform for systematic, reproducible benchmarking of RAG hyperparameter optimization (HPO) methods across diverse environments and standardized search spaces.
RAISE consists of three core components: a highly parameterized RAG pipeline abstraction, an evaluation layer that maps pipeline configurations to task-level rewards, and a controller interface that provides a uniform mechanism for integrating optimization algorithms. The framework supports both text and multimodal LLM pipelines, encapsulating heterogeneous modules such as query rewriting, chunking, retrieval, reranking, pruning, and context compression (for text). It exposes explicit module-level and end-to-end optimization targets, facilitating rigorous comparison of search strategies.
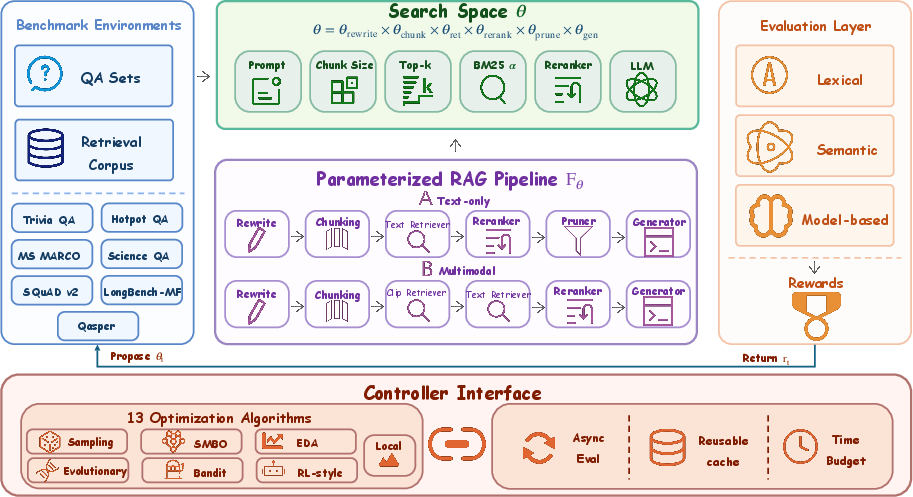
Figure 1: Overview of RAISE, coupling a parameterized RAG pipeline, evaluation layer, and controller interface for algorithmic optimization.
Search Space and Benchmark Construction
The search space in RAISE is defined as the Cartesian product of module-specific configuration options, covering discrete prompt templates, chunk sizes/overlaps, hybrid sparse-dense retriever parameters (α for BM25 weighting, top-k candidates), reranker choices and depths, pruner strategies, and LLM stack selection. For multimodal pipelines, vision-language retrieval is implemented using CLIP-based embeddings and Qwen3-VL models.
RAISE benchmarks are constructed from seven public datasets (TriviaQA, HotpotQA, MS MARCO, ScienceQA, SQuAD v2, LongBench-Multifield, LongBench-Qasper), each instantiated as a QA proxy environment with fixed corpus, enabling controlled evaluation and comparison under matched computational budgets and three random seeds per setting.
Optimization Algorithms and Controller Protocol
Thirteen optimization algorithms are implemented in RAISE, spanning random search, greedy and local search, evolutionary and distribution-guided methods (e.g., Cross-Entropy Method, Regularized Evolution), Bayesian/SMBO (TPE), bandit-style (UCB, Thompson Sampling), and RL-style group-policy approaches (GRPO, Dr. GRPO, Reinforce++). All interact with RAISE through a common controller interface: at each search iteration, an optimizer proposes a full pipeline configuration, which is scored by the evaluation layer on the environment’s objective function (equal-weight aggregate of ROUGE-L, METEOR, token-F1, and BLEU for main benchmark runs).
Experimental Design and Numerical Findings
The empirical protocol examines four explicit hypotheses:
- Optimizer–environment interaction: Performance of search methods varies strongly with task structure and environment, precluding universal optimizer rankings.
- Proxy-size robustness: Stability of search signal is achieved at modest proxy QA subset sizes (∼100–$200$); below that, seed variability is pronounced.
- Search vs. random baseline: 11 out of 12 non-random methods outperform random search under a matched trial budget, but gains are generally modest.
- Module impact: Sensitivity to pipeline module optimization is highly environment-dependent. For instance, long-document retrieval (TriviaQA) benefits most from rewriting and pruning, while multi-hop reasoning (HotpotQA) is more sensitive to retrieval-depth control.
Contrary to standard HPO leaderboards, no optimizer is uniformly best across environments. For example, Greedy Search wins on HotpotQA and TriviaQA, CEM dominates MS MARCO, Random Search leads ScienceQA, and Simulated Annealing does best on LongBench-Multifield (see main benchmark results). Coordinate Descent achieves the lowest average rank across datasets without ever winning, emphasizing the non-trivial optimizer–task bias.
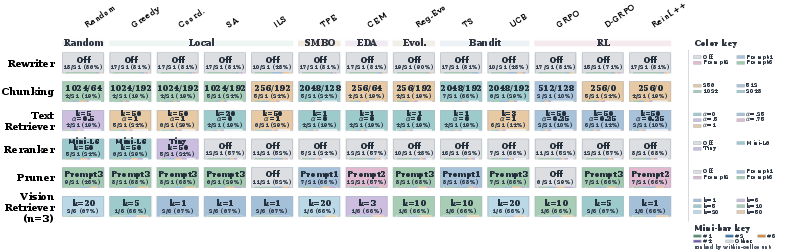
Figure 2: Module-option choices in optimal configurations across seven environments and three seeds, elucidating environment-specific configuration distributions.
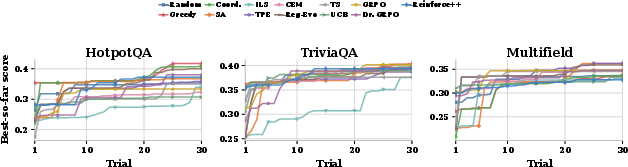
Figure 3: Representative search trajectories under a 30-trial budget, with controllers improving incumbent scores as RAISE evaluates additional configurations.
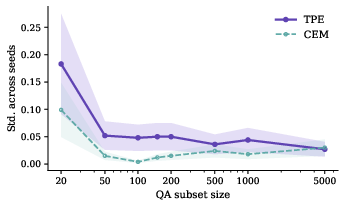
Figure 4: Validation of proxy-size stability and seed robustness across QA subset sizes.
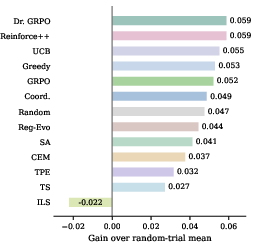
Figure 5: Algorithm gains relative to random-trial means on HotpotQA, quantifying the incremental benefit of explicit search.
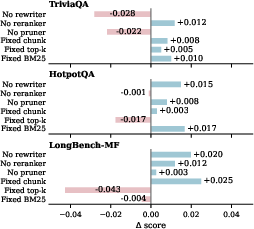
Figure 6: Module sensitivity analysis, reporting mean best-score changes for pipelines with ablated or fixed dimensions.
Theoretical and Practical Implications
This work advances the formalization of RAG system design as architecture search, rather than ad hoc hyperparameter tuning. The findings establish two key points: (1) RAG-HPO optimizer efficacy is intrinsically environment-specific, demanding per-environment reporting and interpretation rather than aggregate leaderboards; (2) full pipeline evaluation is imperative, as comparable scores can emerge from markedly different module configurations.
RAISE lowers the barrier for reproducible RAG-HPO research by providing a shared substrate for algorithm integration, evaluation, and head-to-head comparison. Its extensibility allows rapid inclusion of new benchmarks, evaluation metrics (including reference-free and model-based ones), pipelines, and optimization methods, paralleling the role of HPOBench and YAHPO Gym in classic HPO research.
Practically, the findings recommend explicit reporting of search space details, proxy construction, random baseline scores, and module sensitivities in future RAG-HPO papers. Theoretical implications include the necessity of analyzing optimizer–environment interactions, characterizing objective landscapes for RAG pipeline search, and developing search methods capable of robust adaptation across heterogeneous and multimodal task settings.
Future Directions
The paper identifies multiple open directions for the field:
- Extending search spaces to include alternative model families, continuous hyperparameters, retrieval backends, and complex multimodal conditioning.
- Scaling proxy environments and evaluation budgets for higher-fidelity benchmark comparisons.
- Incorporating semantic and reference-free metrics, alongside classical automated metrics, in the optimization objective.
- Further variance analysis on seeds, budget limits, and optimization noise for robust cross-study reliability.
- Systematic study of RL, policy-gradient, and multi-armed bandit search adaptation for high-dimensional RAG pipeline optimization.
Conclusion
RAISE transforms RAG design into a reproducible architecture search benchmark, disentangling pipeline structure, search algorithm, and environment. The empirical evidence robustly demonstrates optimizer–environment dependence, recommends per-environment reporting, and motivates full-configuration optimization, ablation, and analysis. RAISE is positioned as a foundation for systematic, interpretable, and extensible RAG-HPO research, catalyzing further algorithmic and theoretical developments in retrieval-augmented LLM system optimization.