- The paper presents a declarative framework that decouples RAG pipeline components to automate both architectural and hyper-parameter tuning.
- Its Bayesian-based optimization yields 5–8% gains in Recall@5 and up to 4% improvements in F1, drastically reducing manual code modifications.
- The unified data abstraction via the Domain-Element Model enables rapid experimentation and modular flexibility for complex RAG systems.
AutoRAGTuner: A Declarative Framework for RAG Pipeline Optimization
Introduction
Retrieval-Augmented Generation (RAG) synergistically combines information retrieval with LLM-based generation, yielding superior performance for knowledge-intensive NLP tasks by integrating external knowledge into sequence generation. Nevertheless, RAG pipeline efficacy is acutely sensitive to architectural configurations and multiple hyper-parameters. Traditional manual approaches for tuning these parameters introduce inefficiencies due to structural coupling, lack of standardization, and significant engineering overhead for even minor pipeline changes. The paper "AutoRAGTuner: A Declarative Framework for Automatic Optimization of RAG Pipelines" (2605.02967) addresses these challenges with a modular, configuration-driven framework that systematizes both the architectural and hyper-parameter optimization of RAG pipelines.
Architectural Overview
AutoRAGTuner introduces a modular architecture that decouples pipeline stages via a component registration system. Each component adheres to a unified interface and is implemented in C++ or Python, allowing a balanced trade-off between computational efficiency and development velocity. This design enables seamless extensibility and interoperability across diverse pipeline modules.
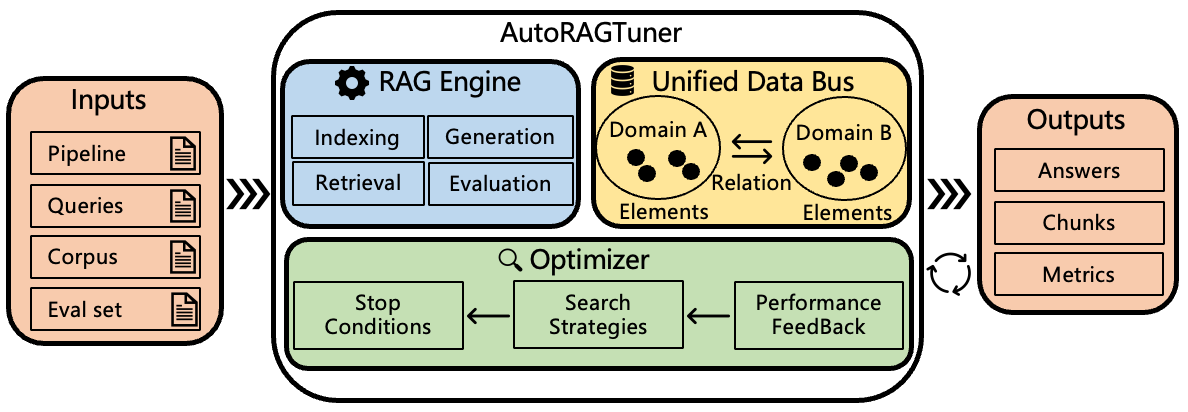
Figure 1: AutoRAGTuner’s system overview highlights a modular control flow, component registration, unified data abstraction, and Bayesian optimization for hyper-parameters.
A central innovation is AutoRAGTuner’s declarative orchestration, enabled via a flexible JSON-based configuration language. This configuration paradigm allows for the specification of pipeline composition, transformation logic, and optimization strategies without altering the underlying implementation, directly supporting the "Edit-and-Run" workflow essential for rapid experimentation.

Figure 2: Example AutoRAGTuner JSON configuration enabling declarative pipeline specification and component-level orchestration.
To further ensure minimal coupling and maximal extensibility, the framework introduces the Domain-Element Model (DEM) for data abstraction. DEM models all RAG data forms—text chunks, entities, relations—as atomic elements with extensible properties and explicit, bidirectional relations via pointers. This abstraction simultaneously supports standard hierarchical structures and complex graph topologies (such as hyperedges), with all cross-domain data dependencies clearly defined in the JSON configuration.
At runtime, Data Bus coordination maintains end-to-end data consistency, isolating component-level changes from the rest of the system and enabling live pipeline modification without upstream or downstream code refactoring. This design paradigm offers strong separation of concerns and promotes architectural agility.
Automated Pipeline and Hyper-Parameter Optimization
AutoRAGTuner’s optimization regime centers on an adaptive Bayesian automatic tuning engine. The optimization process starts with random exploration to establish an informative hyper-parameter prior, and subsequently exploits high-potential hyper-parameter configurations using an Expected Improvement–based acquisition function. To address the high cost of end-to-end experiments, the engine supports epsilon convergence criteria, a configurable upper bound on iterations, and warm-start strategies via reuse of previous traces for faster convergence and fewer wasted evaluations.
Declarative optimization is fully integrated: developers specify which hyper-parameters are tunable in the JSON orchestration layer, after which the optimization engine explores and exploits pipeline variants according to the given specification. This architecture transparently supports both vanilla RAG and structurally complex pipelines such as graph-based RAG architectures, e.g., HippoRAG.
Experimental Evaluation
AutoRAGTuner is evaluated on two canonical RAG pipelines—a vanilla "retrieve-and-generate" pipeline and a graph-based RAG instantiation, HippoRAG. Baseline hyper-parameter configurations follow standard or official settings. For Vanilla RAG, chunk size and overlap ratio are optimized; for graph RAG, the cosine similarity threshold for synonym relationship construction, entity linking threshold, and the damping factor for Personalized PageRank are exposed for tuning.
Experiments conducted on HotPotQA and 2WikiMultiHopQA demonstrate robust improvements. AutoRAGTuner consistently yields gains of 5–8% in Recall@5 and up to 4% in F1 score relative to hand-tuned vanilla and graph RAG baselines.
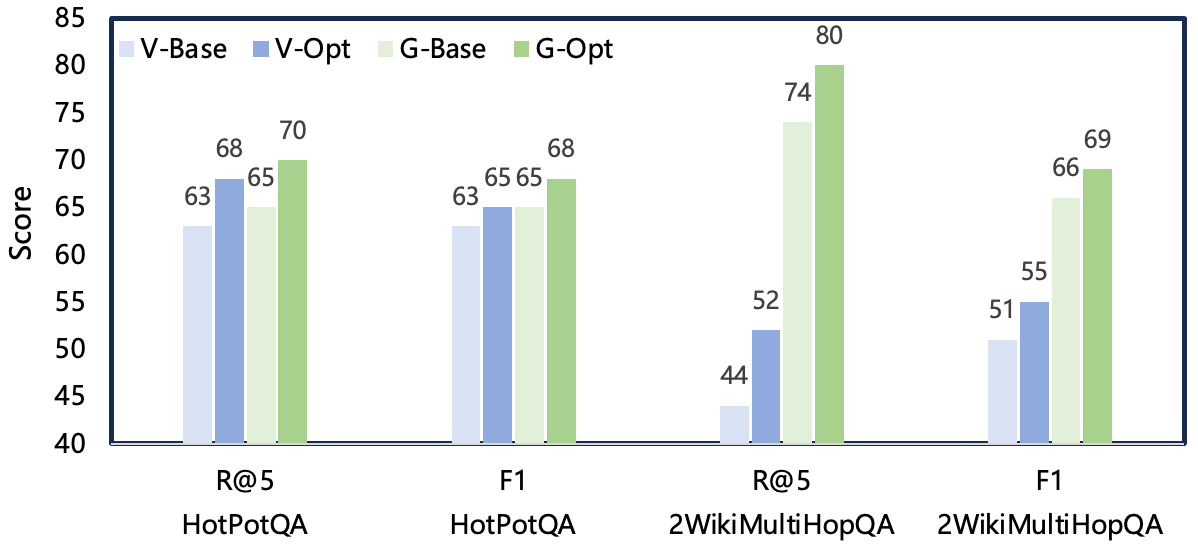
Figure 3: Performance improvements in Recall@5 and F1 for both Vanilla RAG and HippoRAG using AutoRAGTuner’s Bayesian-optimized pipelines.
In addition, the declarative abstraction dramatically reduces pipeline engineering costs. Empirical results indicate a reduction of up to 95% in code modifications (lines of code changed), with all architectural or strategy adjustments localized to the configuration layer instead of throughout the pipeline codebase. Tuning workflows are also accelerated from approximately two weeks (manual) to around ten hours (AutoRAGTuner-based optimization).
Implications and Prospects
AutoRAGTuner provides a robust, evolvable, and reproducible foundation for constructing and optimizing RAG systems under both standard and advanced retrieval paradigms. Its Domain-Element Model unifies data representation, supporting heterogeneous retrieval strategies and enabling advanced graph-based RAG research. The declarative, configuration-driven approach systematically minimizes recoupling and maximizes repeatability, setting a template for future pipeline frameworks seeking modularity, reproducibility, and automated optimization.
This framework has immediate practical consequences for rapid development cycles in industry and research, and it offers a flexible workbench for architectural search in RAG, particularly as research moves toward more complex modular and graph-based reasoning. The abstraction principles applied in AutoRAGTuner may further generalize to other multi-stage NLP and IR pipelines, with potential extension to real-time adaptation and neural pipeline search paradigms.
Conclusion
AutoRAGTuner systematically automates and abstracts both the architectural and hyper-parameter search space of RAG pipelines. By decoupling pipeline stages through modular architecture, unifying data via the Domain-Element Model, and supporting fully declarative orchestration, it achieves significant performance improvements and engineering efficiency. Its generality and extensibility make it a strong foundation for future research and real-world deployment of complex retrieval-augmented generation architectures.