- The paper presents MileStone, a framework that formulates compiler phase ordering as a multi-objective constrained optimization problem using graph-based IR representations, GNN performance prediction, and RL-driven search.
- The methodology leverages control-data flow graph extraction, a two-layer GCN for static performance prediction, and both DQN and PPO methods to explore and optimize pass sequences.
- Empirical results show up to 45% execution time reduction at iso-energy budgets and over 90% matching rate for constraints, setting a new benchmark for compiler optimizations.
MileStone: A Multi-Objective Compiler Phase Ordering Framework for Graph-based IR-Level Optimization
Introduction and Motivation
Compiler phase ordering—selecting and sequencing optimization passes over the intermediate representation (IR)—directly impacts execution time, code size, and energy consumption. The combinatorial complexity of pass orderings, compounded with conflicting objectives, renders classical fixed strategies (such as LLVM’s -O1/-O2/-O3) suboptimal for balancing diverse goals on heterogeneous targets. The "MileStone" framework (2605.23435) formulates compiler phase ordering as a multi-objective constrained optimization problem, representing IR as graphs, leveraging GNN-based static performance prediction, and exploring the phase order space via RL under explicit user constraints for code size, latency, and energy.
The framework is motivated by augmented use-cases found in embedded, edge, and mobile computing, where energy constraints become first-class requirements. Existing approaches typically flatten multi-objective optimization into weighted sums or operate with naïve heuristics, failing to reliably traverse the Pareto front of feasible solutions and rarely capturing program-architecture-adaptive trade-offs.
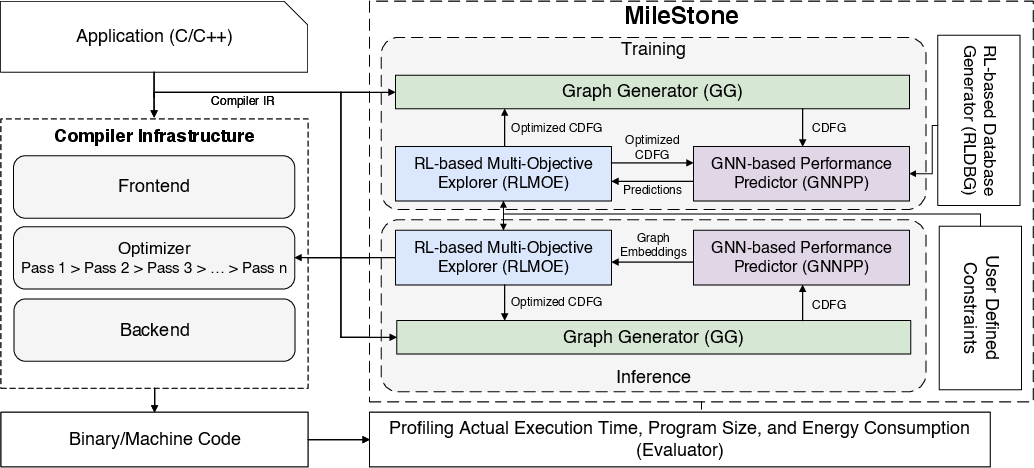
Figure 1: MileStone modular high-level architecture connecting graph extraction, GNN-based prediction, RL-based multi-objective exploration, and a self-optimizing database.
MileStone Architecture
MileStone integrates four principal subsystems:
- Graph Generator (GG): Extracts CDFGs from the LLVM IR to expose control and data flow structures as a basis for pass assignment.
- GNN-based Performance Predictor (GNNPP): Uses program CDFGs and a shared binary/one-hot instruction type encoding to provide vector embeddings and regression outputs for code size, execution time, and energy. It is deployed for both supervised model training and fast inference.
- RL-based Multi-Objective Explorer (RLMOE): Models optimization as an MDP where state vectors concatenate GNN-extracted features and program metadata, and actions correspond to transformation directive allocations; reward is a linear combination of (possibly weighted) prediction metrics, with scalarization adjusted by parameter μ.
- RL-based Database Generator (RLDBG): Iteratively populates a database of pass sequences, program embeddings, and measured objective values, providing supervised datasets for reward and GNNPP estimator validation.
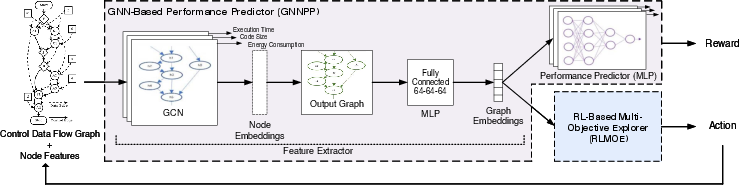
Figure 2: Detailed integration and data flow across GNNPP and RLMOE modules, illustrating embedding construction, reward assignment, and the closed adaptive optimization cycle.
Program CDFGs are processed using a GCN with a layer-wise propagation rule integrating adjacency and degree normalization. Node embedding combines both structural (basic block/instruction) and semantic (operation type) signals, with graph representations aggregated via mean-pooling. Separate predictor heads regress code size, execution time, and energy. Two GCN layers yield optimal predictive performance without suffering from oversmoothing.
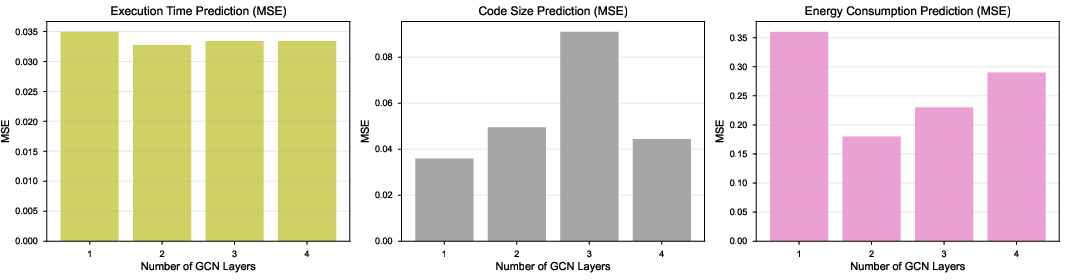
Figure 3: GNNPP prediction error (MSE) versus GCN layer depth; accuracy degrades beyond two layers due to feature homogenization and oversmoothing in the graph.
RL-based Multi-Objective Phase Ordering
RLMOE employs both value-based (DQN) and policy-gradient (PPO) methods to accommodate optimization scenarios of varying CDFG dimensionality and pass space complexity. The RL state is a concatenation of structural graph embeddings and architectural metadata, allowing the agent to generalize across unseen input graphs. The reward function is formulated as:
rt=−α⋅CodeSizep−β∣Energyt−Energyp∣−λ⋅ExecTimep
Final allocation strategies are selected by optimizing expected cumulative reward across the Pareto frontier, subject to explicit user constraints (e.g., energy budgets). Fine-tuning capabilities and large-batch parallel exploration are enabled for rapid model adaptation.
RLDBG: Efficient Data Generation and Model Self-Improvement
The RLDBG subsystem uses RLMOE as an engine to automate exploration and pass sequence construction, compiling, profiling, and analyzing candidate binaries to collect ground-truth objective labels. The self-evolving database accelerates both GNNPP training and reward model calibration, obviating the need for comprehensive runtime profiling with each candidate sequence and enabling more scalable offline optimization.
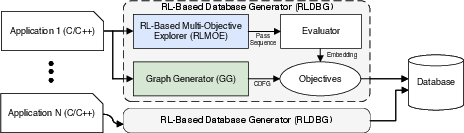
Figure 4: RLDBG workflow: source → CDFG extraction → RL-driven sequence search → ground-truth measurement → labeled dataset generation.
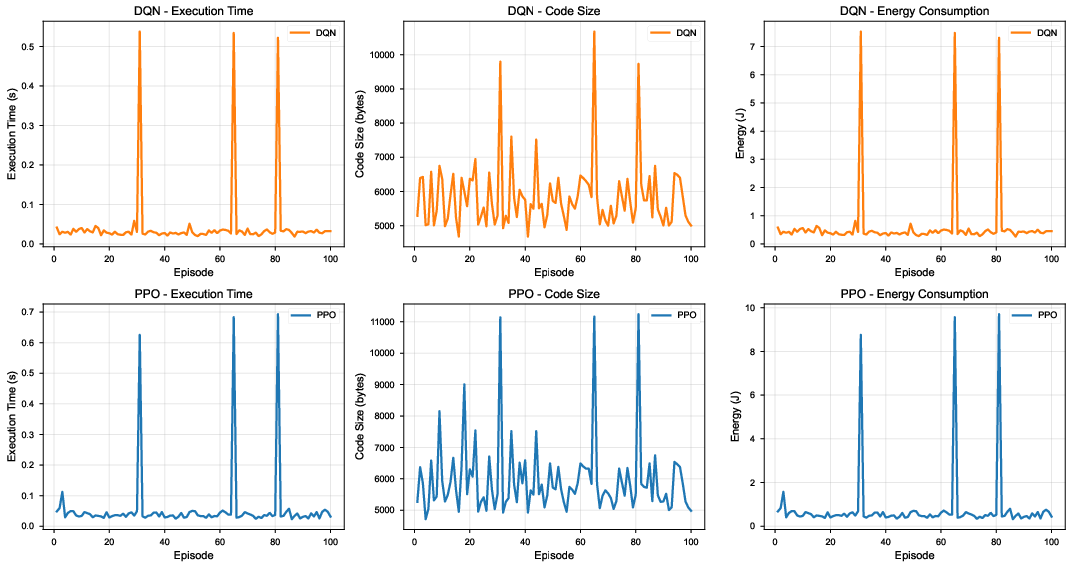
Figure 5: Profiling of execution time, code size, and energy during RLDBG-guided training of DQN/PPO agents, illustrating episodic trade-off and search dynamics.
Empirical Evaluation
Baseline Comparison
MileStone’s performance is benchmarked against heuristic (GA, PSO), standard compiler levels (-O1/-O2/-O3), and established RL or hybrid approaches (standalone DQN/PPO, POSET-RL, FlexPO, MiCOMP, etc.). Baselines generally lack explicit multi-objective optimization and structural program encoding.
Pareto-Optimality and Multi-Objective Trade-offs
MileStone achieves denser and more contiguous Pareto fronts, consistently outclassing baselines in all three objectives—especially under stringent energy targets, where LLVM’s fixed -O3 sequence fails to satisfy constraints.
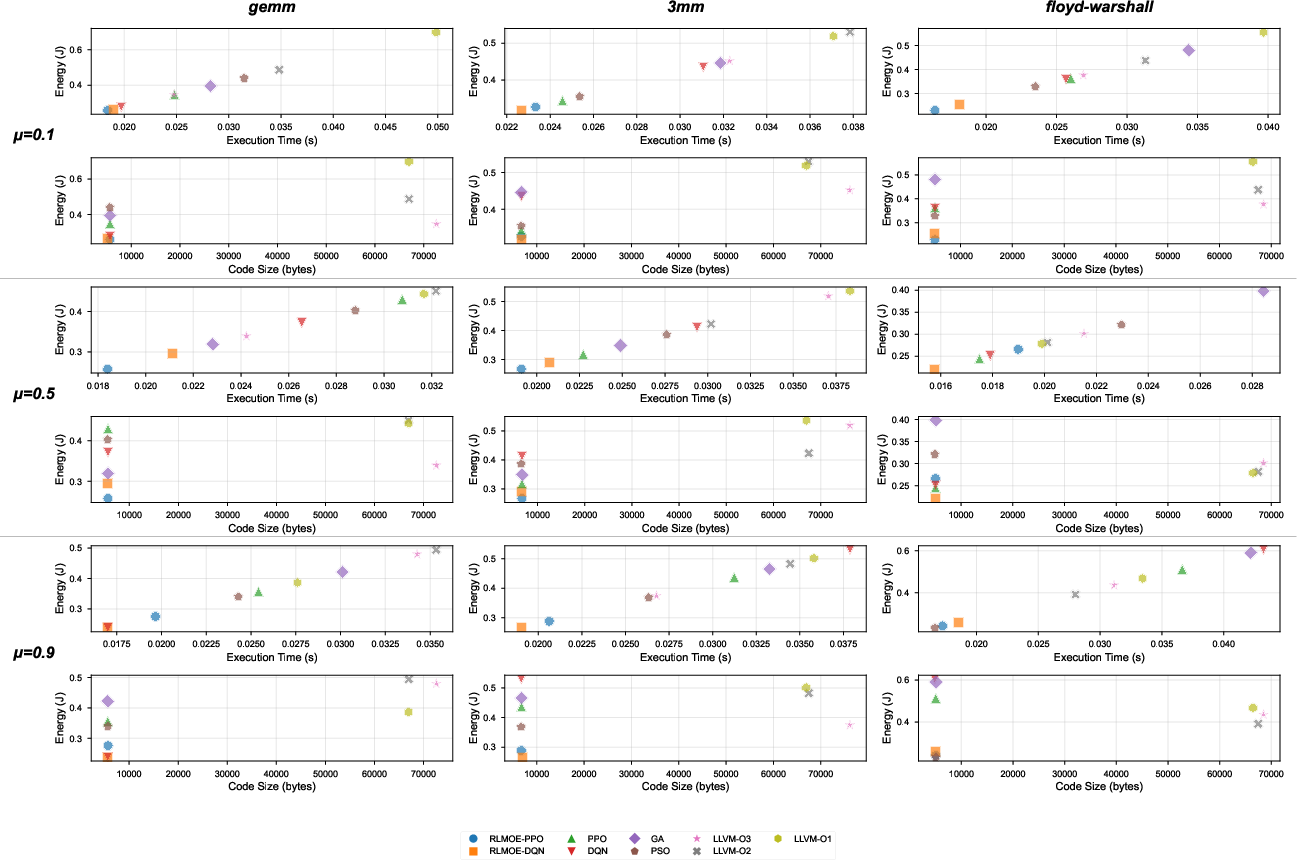
Figure 6: Comparative inference performance: RLMOE, PPO, DQN, GA, PSO, and LLVM optimization levels on real-world benchmarks, highlighting RLMOE’s superior energy-constrained pass orderings.
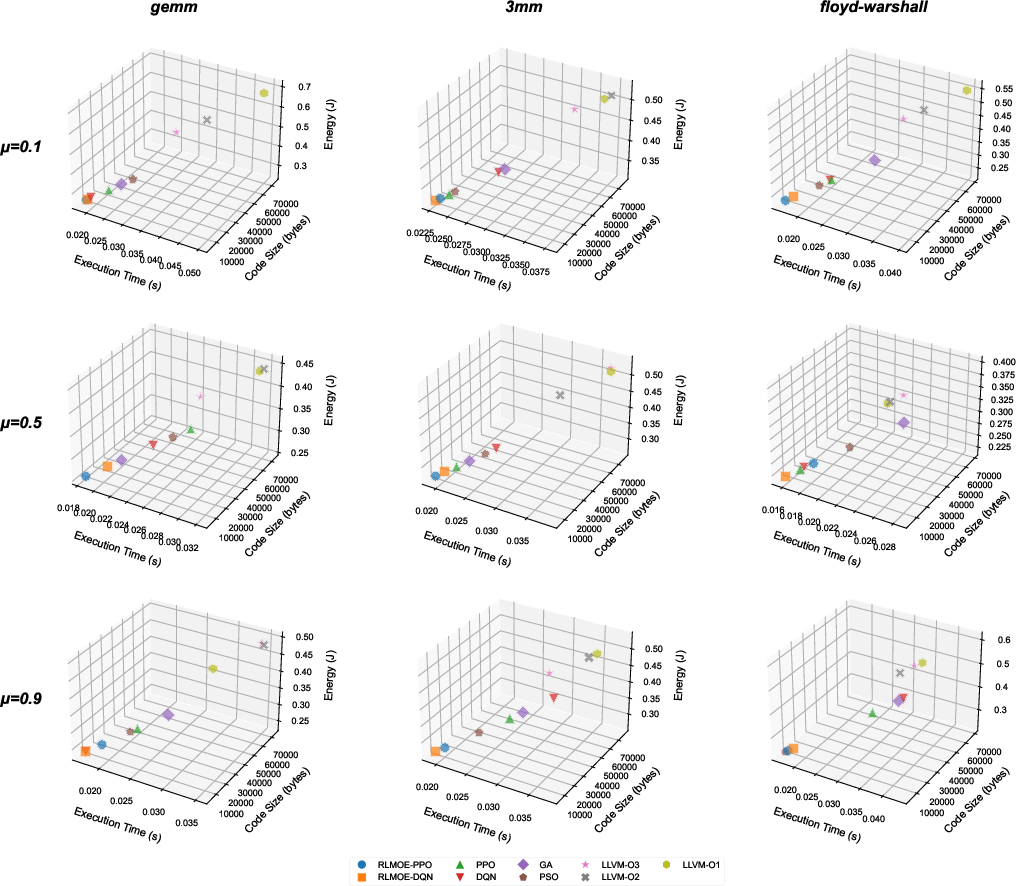
Figure 7: 3D Pareto front analysis for execution time, code size, and energy; RLMOE solution clusters dominate the feasible trade-off space.
Constraint Satisfaction and Matching Rate
For 336 (energy, code size, exec time) constraints, RLMOE-PPO attained a matching rate exceeding 90% for all μ settings—20–30 points above classic or metaheuristic baselines.
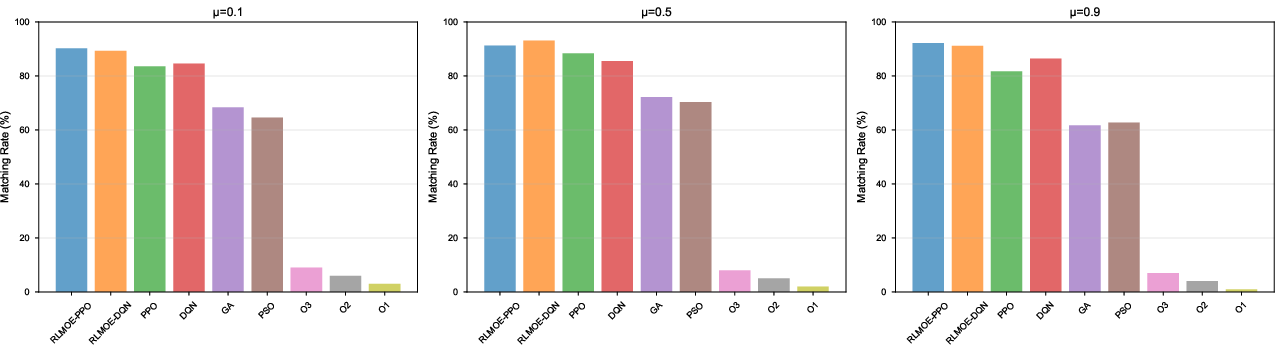
Figure 8: Matching rate of discrete energy constraints; RLMOE methods achieve the highest coverage, demonstrating precise objective control.
Execution Time Reduction at Iso-Energy
MileStone yields execution time reductions of 15–45% under equivalent energy budgets relative to LLVM-O3 and up to 9% over the next best RL baseline (POSET-RL), with the largest margins at intermediate μ levels.
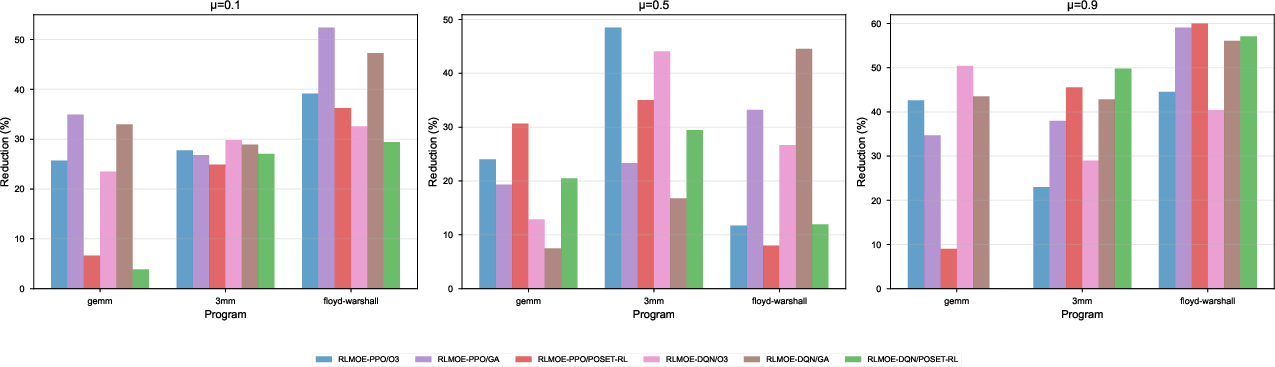
Figure 9: Execution time reduction for RLMOE (DQN/PPO) at fixed energy, compared to O3, GA, and DQN; large gains achieved, especially on computationally intensive benchmarks.
Theoretical and Practical Implications
MileStone provides a generalizable approach for exposing optimization-leverage in IR-level phase ordering, integrating structural program features via GNNs with policy search. Moving beyond monolithic, architecture-agnostic pass sequences, it enables user-constraint-driven compilation, robust cross-program knowledge transfer, and the ability to model fine-grained Pareto surfaces of conflicting objectives. The modular design admits further extension, such as incorporation of hardware microarchitectural models or dynamic profiling signals for hardware-adaptive tuning.
On the practical side, the framework reduces profiling overhead and accelerates data generation via the RLDBG feedback loop, supporting rapid iteration and transfer to new program domains or energy-constrained application classes.
Conclusion
MileStone establishes a scalable, modular paradigm for multi-objective compiler phase ordering via integration of GNN-based static prediction, RL-based adaptive exploration, and automated rich database construction. It sets a new standard for fulfillment of user-specified performance and resource constraints in compilation, outperforming traditional heuristic and RL systems in both objective fidelity and constraint matching. The formalization as a Pareto optimization problem, combined with graph-based program understanding, has wide-ranging implications for autotuning, energy-aware computing, and adaptive systems. Future work should explore scaling to larger or industrial codebases, further granularity in objective space modeling, and integration with online/just-in-time compilation scenarios.