- The paper presents a novel LLM-guided approach for synthesizing fine-grained, semantics-preserving compiler hints to optimize code.
- It combines a retrieval-augmented generation pipeline with execution-guided refinement, yielding significant performance gains up to 6.88× over -Ofast.
- Empirical results on benchmarks like PolyBench and HumanEval_CPP demonstrate robust correctness (97–98%) and localized optimization improvements.
LLM-Based Compiler Hint Synthesis for Optimization: An Expert Review of HintPilot
Background and Motivation
With the stagnation of Moore's law and the increasing heterogeneity and complexity of hardware, software performance optimization is more critical—and more challenging—than ever. Traditional compilers rely on global, expert-designed heuristics and static phase orderings, often failing to exploit fine-grained or context-specific optimization opportunities in large codebases. Recent work has explored two main avenues for leveraging LLMs in code optimization: direct source-to-source transformation via LLM-generated edits (risking semantic regressions), and the selection of global compiler flags or pass orderings (missing localized, non-transitive optimization opportunities) [Gong_2025; pie24; llmcompiler]. However, both paradigms exhibit substantial limitations, such as poor semantic guarantees and insufficient granularity (see Figure 1).

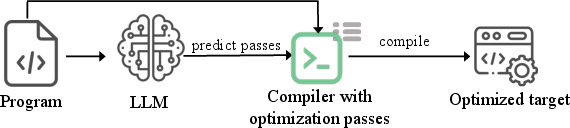
Figure 1: Overview of three LLM-augmented code optimization paradigms: direct transformation, global flag selection, and fine-grained compiler hint synthesis.
To address these deficiencies, "HintPilot: LLM-based Compiler Hint Synthesis for Code Optimization" (2604.15041) introduces a novel paradigm: leveraging LLMs for the automated, semantics-preserving insertion of fine-grained compiler hints (e.g., pragmas, function/variable attributes, targeted annotations). This approach constrains LLM interventions to valid, compiler-validated declarative hints, combining the contextual pattern-matching and code understanding of LLMs with the strong semantic preservation guarantees of the underlying compiler.
Technical Approach
HintPilot operationalizes this idea through an integrated retrieval-augmented generation (RAG) and execution-guided self-refinement pipeline. Its workflow is as follows:
- Structured Context Extraction: Uses GCC's parser to construct an explicit code abstraction, identifying well-typed, valid locations for potential hint insertion (functions, variables, statements).

Figure 2: Program representation highlighting hint-insertion points.
- Semantic Retrieval and Prompting: A curated knowledge base, derived from official compiler documentation, provides semantic descriptors and usage patterns for 46 rigorously selected, semantics-preserving hints. The model retrieves candidate hints and their applicability conditioned on the local program context, augmented with official and synthetic usage examples.

Figure 3: Prompt template guiding LLMs with structured code context and retrieved hint information.
- LLM-Based Synthesis: The system prompts an LLM (experiments evaluate both open-source and proprietary models, and control for backbone model capacity) to propose sets of hint insertions, grounded by the retrieved semantics and code context.
- Execution-Guided Iterative Refinement: Candidate hint sets are applied, then the code is compiled and tested for both correctness and runtime performance on a supplied input set. Compilation errors, test failures, or performance regressions trigger a feedback-guided refinement loop, where compilation/test results and performance logs are furnished to the LLM to guide subsequent generations (see Figure 4).

Figure 4: The refinement prompt structure for iteration, integrating execution feedback.
By constraining LLM suggestions to a validated subset of hints and locations, HintPilot maintains semantics preservation—sidestepping correctness regressions induced by direct code transformations. Its locality-aware strategy affords optimization at the granularity of individual loops, functions, or variables, subsuming traditional approaches to both pass selection and blanket flag specification.
Empirical Evaluation
Experimental Setup
HintPilot was evaluated on two challenging optimization benchmarks:
- PolyBench: 34 numerical computation kernels, commonly used for evaluating low-level and high-performance code optimizations.
- HumanEval_CPP: 164 general-purpose C++ tasks (algorithmic and real-world), supporting evaluation beyond predictable numerical optimization patterns.
Baselines include:
- GCC -O3 and -Ofast, representing strong global compiler heuristics.
- LLM-Compiler (CodeLlama-13B) [llmcompiler], a recent LLM-based optimization-pass selector.
- Diverse backbone LLMs (Qwen3-Coder-Plus, GPT-5.2, Codestral, Claude-Sonnet-4.5, etc.) to assess the effect of model capacity and architecture.
Experiments are controlled for compilation hardware, and speedups are reported as geometric means over repeated runs.
Numerical Results
HintPilot delivers geometric mean speedups of up to 3.53× over -O3 and 6.88× over -Ofast on HumanEval_CPP, and up to 2.10×/1.63× on PolyBench, contingent on backbone model and refinement hyperparameters. This constitutes a substantial performance gap compared to both baseline and the prior SOTA LLM-Compiler flag prediction (Figure 5, Figure 6).
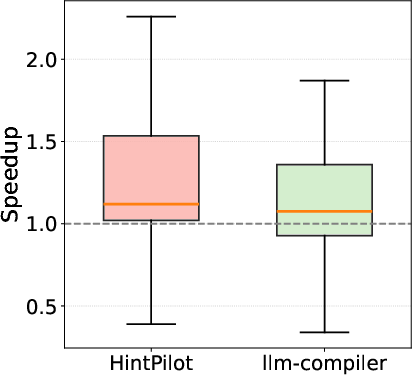
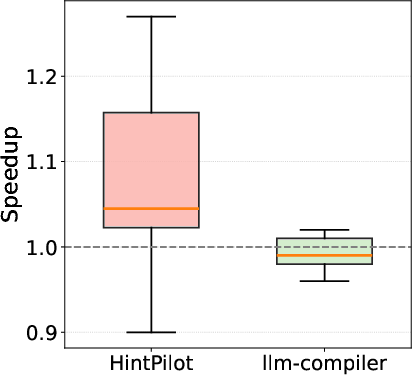
Figure 5: HumanEval_CPP results quantifying speedup over -O3.
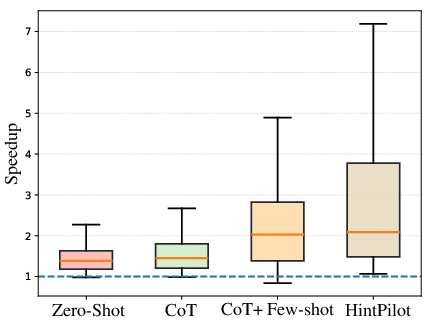
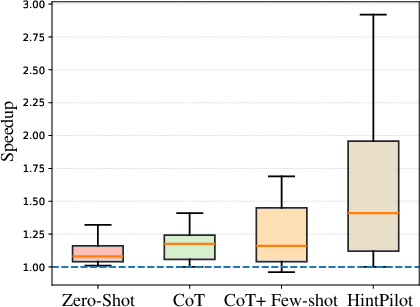
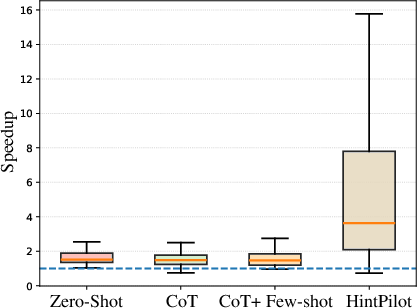
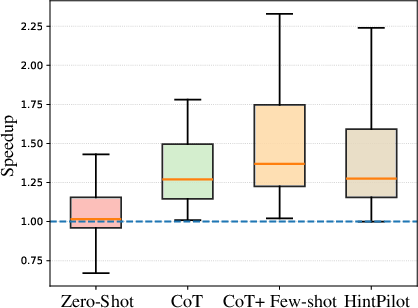
Figure 6: Speedups on HumanEval_CPP relative to -Ofast.
Notably, HintPilot maintains semantic correctness by construction (compilation and correctness rates are consistently 97–98%), while the LLM-Compiler baseline exhibits correctness regressions (due to unsafe flag combinations) and much lower, less reliable speedups. The ablation analysis demonstrates:
- Retrieval-augmented, context-aware prompting (with few-shot and CoT) greatly outperforms naive zero-shot prompting.
- Increasing the number of candidates (N) per iteration enhances performance gains, while excessive refinement iterations can introduce noise.
- Larger backbone LLMs are correlated with more sophisticated optimizations and more reliable plan generation.
Failure Analysis and Limitations
Failure modes primarily arise from:
- Syntax hallucination (20% of failures): LLMs propose invalid hint syntaxes; these are typically cheaply detected at compile time.
- Contextual mismatch (79%): Hints applied to ineligible locations or requiring unavailable flags.
- Profiling instability (<1%): Execution feedback overfits to measurement noise.
Despite systematic retrieval and filtering, false positives in LLM hint location selection remain. Rule-based and LLM-powered checkers reduce, but do not eliminate, such issues. The performance-critical coverage, however, is sufficient for production-grade deployment in common use cases, and safety is not compromised—incorrect hints are simply ignored or trigger compile-time diagnostics.
Implications and Theoretical Impact
By establishing a semantics-preserving, interpretable, and fine-grained interface between LLMs and classical optimizing compilers, HintPilot redefines the trade-off landscape of ML-based code optimization:
- Safety: Direct code transformations by LLMs, as surveyed in [Gong_2025; Dong_2025; Acharya2025; Gao_2024], deliver strong mean speedups only when allowed to sacrifice correctness, which is unacceptable in many real-world settings.
- Expressivity: Compiler flag selection (e.g., [llmcompiler]) is inherently global and non-local, missing many “hidden” optimization opportunities revealed by code context or across function or variable boundaries.
- Adaptability: RAG-based hint generation enables rapid porting to new targets (Clang, RISC-V, ARM, etc.)—the knowledge base can be auto-populated for new architectures.
Furthermore, the method offers an orthogonal axis of optimization to classical ML-for-compilers literature (e.g., phase ordering via RL, supervised unroll factor prediction, graph learning for cost modeling [Baghdadi, trofin20MLGO, mendis2019ImitationLearning]).
Looking forward, the integration of LLM-synthesized hints with global pass schedules, learned code transformation pipelines, and reinforcement learning over large per-codebase optimization spaces is a promising future direction. Improved static verification of candidate hint insertions and hardware-adaptive feedback protocols will further enhance robustness.
Broader Impact and Comparative Analysis
This work positions LLM-guided hint synthesis as a middle ground between untrusted, high-variance edits and underpowered global flag selection, and achieves superior empirical performance across a diverse set of program patterns, datasets, and base models. Unlike black-box optimizer-guided evolutionary or RL-based phase ordering [supersonic; staticrl; Lamour_2025], HintPilot offers interpretable and localized suggestions, which can be audited and post hoc justified by compiler engineers.
Comparatively, recent LLM-based efforts in code efficiency benchmarks (EFFIBENCH [Huang_Qing_Shang_Cui_Zhang_2025], Mercury [mercury2024], COFFE [Peng_Wan_Li_Ren_2025]) reinforce the criticality of evaluating both correctness and efficiency, echoing the comprehensive approach of HintPilot.
Conclusion
HintPilot demonstrates that the synthesis of structured, semantics-preserving compiler hints by LLMs—grounded by RAG from documentation and refined through execution feedback—can consistently yield state-of-the-art code performance improvements. The method achieves both high correctness and significant speedups across heterogenous codebases and models, with interpretability and extensibility beyond prior paradigms. Its effectiveness highlights the necessity of co-design between AI systems and traditional compilers, rather than complete replacement or naive pass selection.
The methodology is directly extensible to broader classes of program annotations and compiler infrastructures. Advances in context-aware reasoning, larger and more targeted LLMs, and improved code understanding will further amplify this effect. As ML-for-code moves toward industrial-scale, compliant, and auditable deployments, HintPilot establishes an effective, practical template for LLM-augmented code optimization frameworks.