- The paper introduces a unified distributional OT framework to robustly align SAE features for both matching and compression.
- It leverages Wasserstein distances over activation context distributions to enable precise cross-manifold semantic comparisons and stable supernode grouping.
- Empirical and theoretical analyses confirm improved matching accuracy, efficient circuit compression, and robustness against activation noise.
Semantic Optimal Transport for Sparse Autoencoder Feature Matching and Circuit Compression
Introduction and Motivation
Sparse Autoencoders (SAEs) have become foundational for mechanistic interpretability of LLMs, enabling the disentangling of latent spaces into interpretably structured features. However, there are two principal analytic bottlenecks in scaling interpretability analysis: matching semantically similar features across layers and compressing sprawling feature circuits into tractable, interpretable units. The present work argues that both challenges stem from a unified problem: the robust estimation of cross-manifold semantic distances between SAE features, where each feature's activations reside in potentially distinct latent geometries.
Distributional Semantic Representations and Optimal Transport
Traditional pipeline matches or groups SAE features using their decoder vectors. This approach is fundamentally limited, as decoders capture only pointwise information and do not encapsulate the contextual breadth of feature activations. The proposed methodology instead represents each SAE feature as a distribution over activation contexts, weighted by activation magnitude, and projects these empirical distributions into a shared reference space.
The core of this methodology leverages Optimal Transport (OT)—concretely, the discrete Wasserstein distance—between the activation-weighted feature distributions in the reference space as a rigorous, geometry-agnostic metric of "semantic distance" which is robust to the differences in support and metric between layer-wise manifolds. This makes both feature matching and circuit compression naturally cross-manifold problems, which can be solved as geometric alignment of empirical distributions in shared representation space.
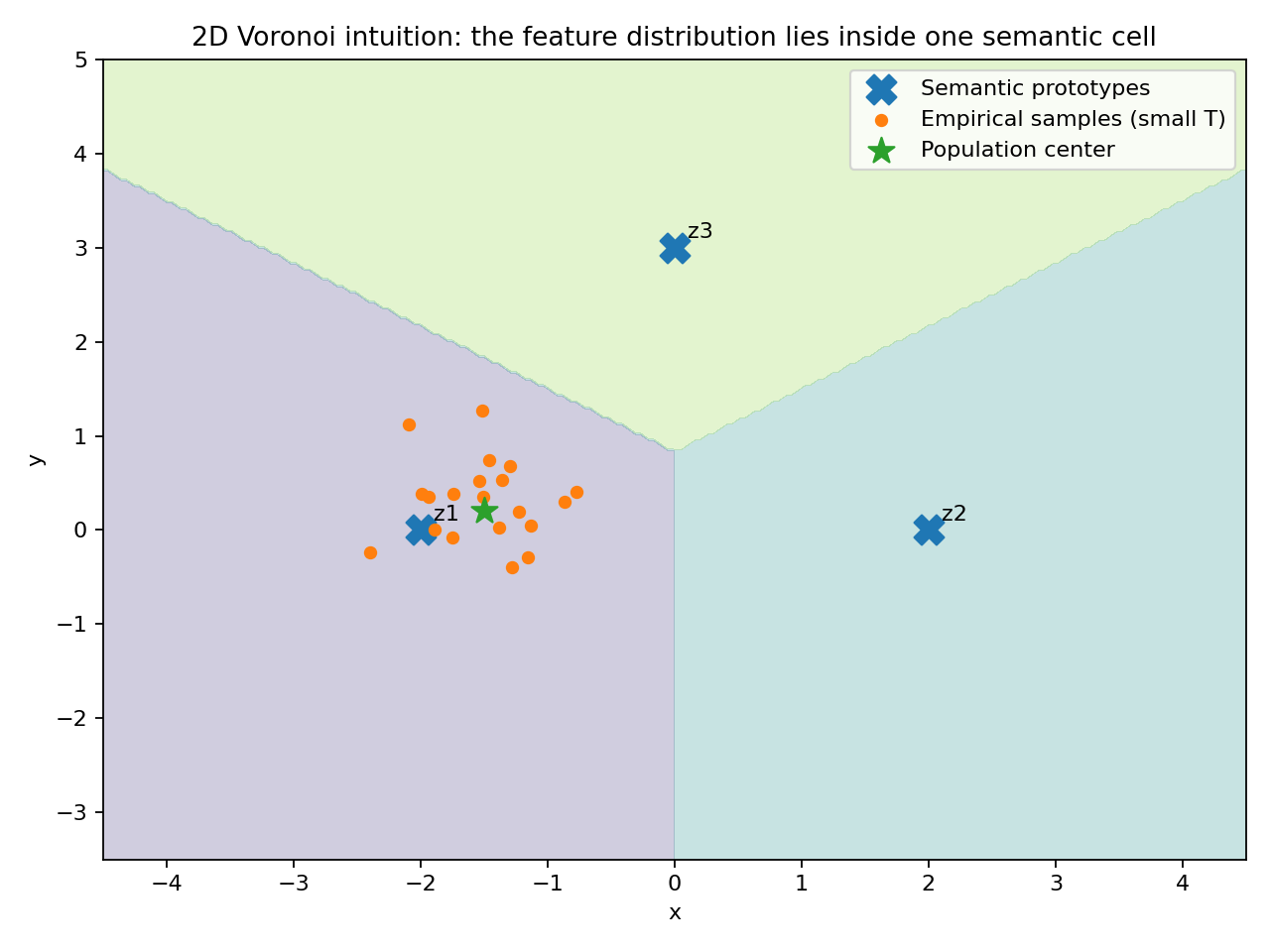
Figure 1: Visualization of Voronoi partitioning induced by semantic prototypes; empirical support of feature activations remains stable under perturbation if far from decision boundaries.
Theoretical Properties
Three main theoretical guarantees substantiate the approach:
- Invariance to Activation Rescaling: Feature representations, as empirical distributions of activation contexts, are invariant to global scaling of activations, mitigating issues stemming from non-comparable activation magnitudes across layers.
- Wasserstein Score Robustness: The feature distances computed via OT are stable under measure perturbations, with error bounded by the Lipschitz constant of the underlying cost and the Wasserstein distance between empirical and population distributions (see Section 4.1).
- Margin-Based Recovery Conditions: The empirical nearest neighbor assignments (matching and grouping) are provably stable under finite-sample noise, provided the true margin (gap to next-best matching) exceeds twice the estimation error. This is formalized both for feature matching and for circuit compression/group assignment through the Voronoi recovery theorem.
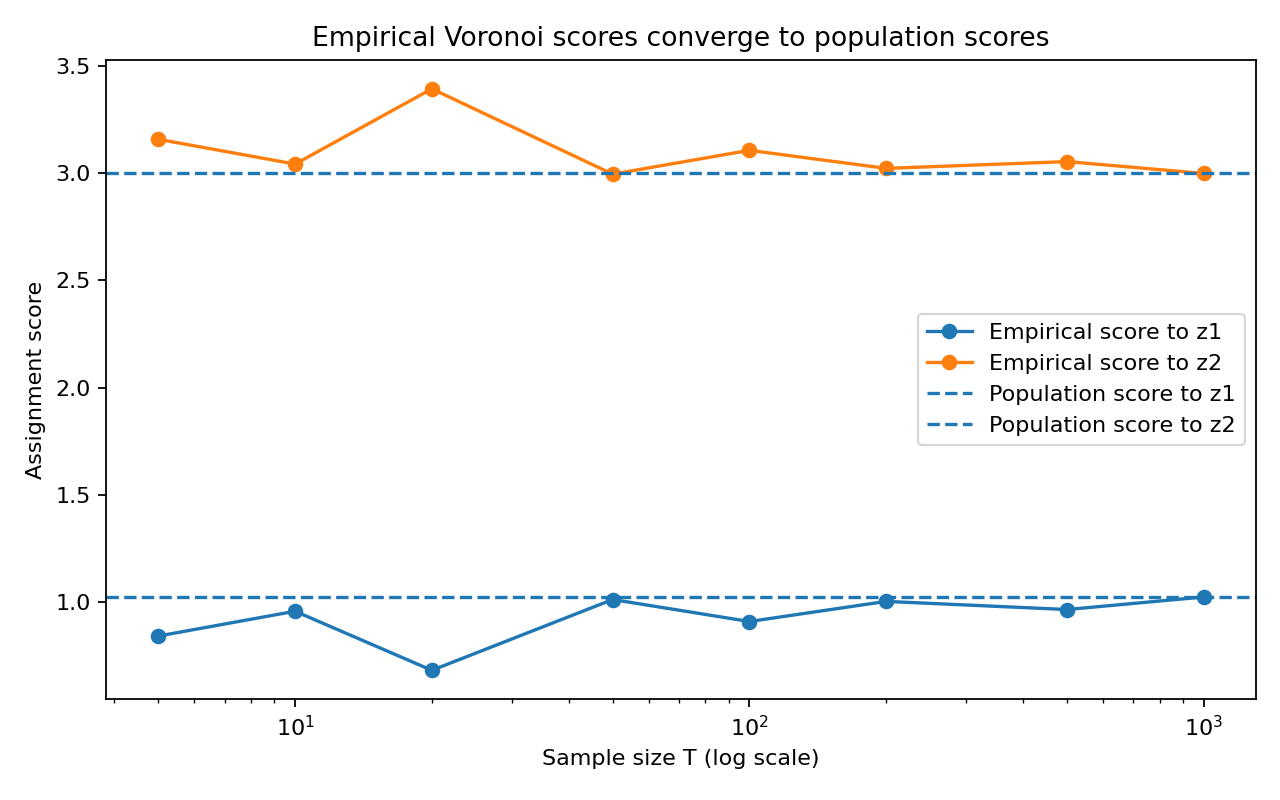
Figure 2: Empirical assignment scores for each semantic center concentrate to their population values; stable matching is obtained once the empirical score gap is positive.
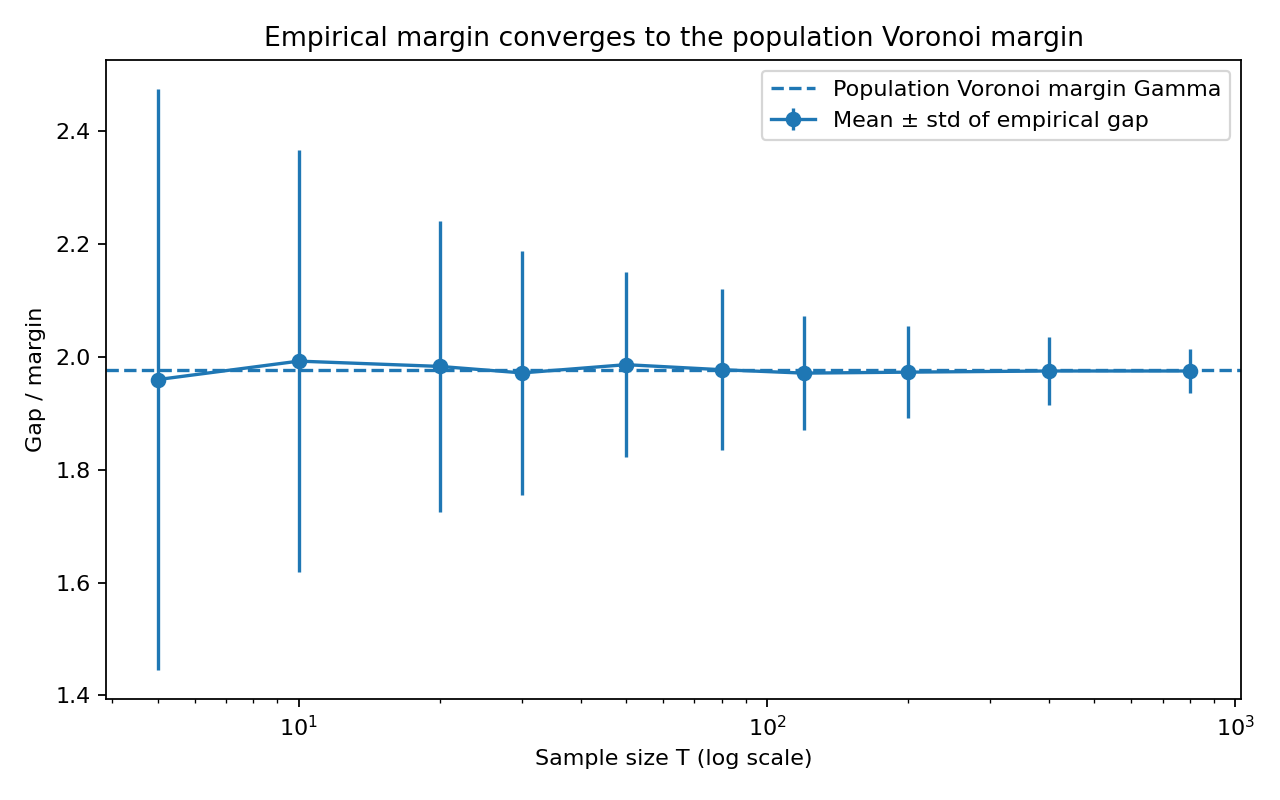
Figure 3: Empirical margin of semantic assignment concentrates around the population Voronoi margin, substantiating margin-based recovery threshold.
Cross-Layer Feature Matching
Given the challenge of comparing features arising from distinct layers—and thus different representation manifolds—the method uses the reference space of a target layer as the semantic basis to project both target and source feature activation contexts. Then, Wasserstein distances between these projected distributions define semantic similarities for matching. This OT-based semantic alignment outperforms decoder-only baselines (e.g., L2 or cosine similarity of decoders) and LLM-based selection—especially as the number of layers between features grows, where decoder-vector-based approaches fail due to increasing divergence between latent distributions.
Circuit Compression and Semantic Grouping
Feature circuits can contain hundreds of nodes when tracing the causal flow in LLMs with SAEs, becoming analytically intractable. The proposed methodology clusters circuit nodes into "supernodes" by minimizing within-group semantic distances in the reference space. Agglomerative clustering is applied over the pairwise Wasserstein distance matrix. This facilitates large-scale, automated grouping yielding semantically coherent supernodes, enhancing interpretability of high-level circuit motifs.
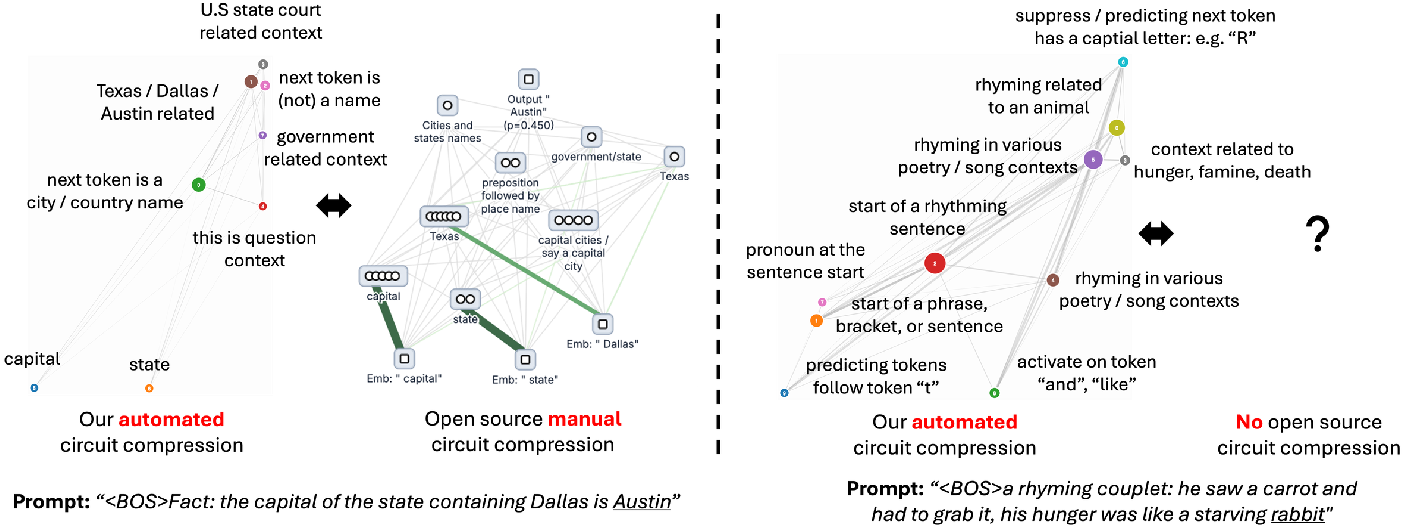
Figure 4: Automated circuit compression compared to manual open-source grouping, demonstrating identification of supernodes consistent with expert annotations and scalability to larger graphs.
Notably, the shared reference space for compression is built by concatenating the hidden states from all layers for each activation context, ensuring that cross-layer functional relationships are preserved.
Empirical Analysis
The empirical suite includes cross-layer and multi-layer matching tasks on both GPT-2 and Gemma-2-2b models using JumpReLU and TopK SAEs. The OT-based approach demonstrates superior LLM-evaluated similarity, higher matching accuracy, and lower cross-entropy and improved variance explained when substituting matched features in downstream LLM tasks. Particularly, performance gaps amplify with increased manifold mismatch (non-consecutive layers), where decoders/embed-based baselines degrade.
Semantic Sensitivity
Matching tests on "digit addition" circuits—where feature semantics are subtle and ground truth interpretable—demonstrate that OT-based distributional matching better captures non-trivial semantic structure of arithmetic reasoning in the model compared to alternative methods.
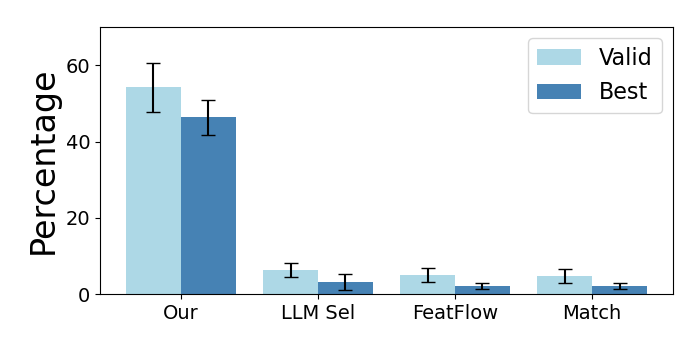
Figure 5: Human evaluation of feature matching on "digit addition" features demonstrates higher agreement for the proposed OT-based method.
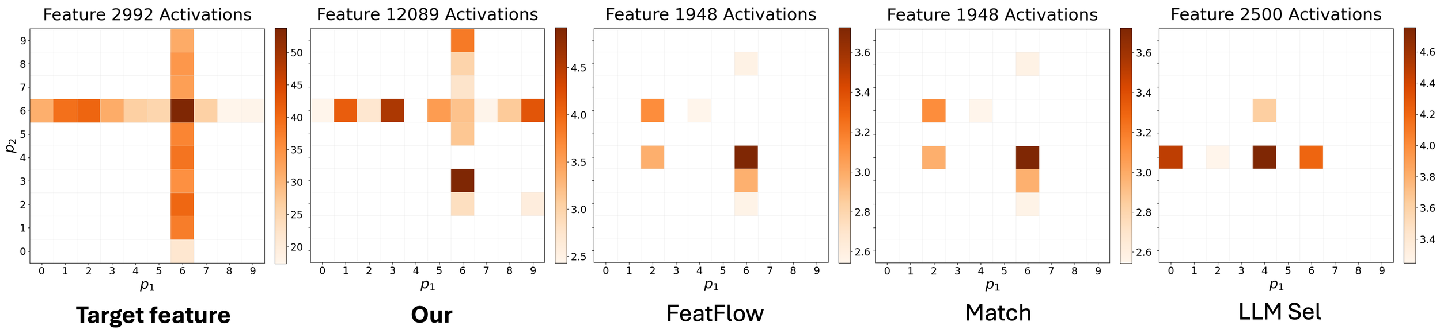
Figure 6: Example—distributional matching accurately recovers features tracking the same arithmetic function, while decoder-matching fails.
Circuit Compression Benchmarking
The method yields higher LLM-assessed alignment of compressed supernodes to human-interpretable functional groups compared to clustering on decoders or LLM-selection-based grouping, especially as circuit size increases.
Ablation: Necessity of Distributional Representation
An ablation replacing distributional features with their mean embedding shows consistent performance degradation on both matching and compression tasks, underscoring that the distributional geometry of activations—not just the average—contains critical semantic signal.
Modular Feature Group Discovery
The methodology further enables unsupervised discovery of functionally modular feature groups recurring across circuits. By tracking supernode co-occurrence across many compressed circuits and applying spectral clustering, feature modules corresponding to distinct algorithmic behaviors or syntactic operations are revealed.

Figure 7: Automatically discovered modular groups in "incrementing sequences" circuits, capturing induction and bracket-detection mechanisms.

Figure 8: Modular decomposition in HTML end-tag prediction circuits surfaces separate functional groups for tag and end-tag detection.
Implications and Future Directions
This work provides a mathematically principled, scalable, and empirically validated solution to two critical bottlenecks in model interpretability for SAEs: cross-manifold feature matching and automated circuit compression. By treating features as empirical distributions and operationalizing semantic similarity via OT in a shared reference geometry, these tasks are unified under a robust, geometry-agnostic framework.
The theoretical results highlight a practically actionable criterion—margin-based recovery certificates—for determining match and grouping stability in finite, noisy samples, supporting their use as confidence estimates in interpretability pipelines. Empirical analyses establish that capturing the full activation context distribution is vital, and distributional geometry cannot be fully collapsed into a single embedding without loss of critical information.
Potential future work includes learning geometry-aware ground cost functions attuned to the curvature or manifold structure of LLM latent space, and generalizing to settings where token alignment across layers is nontrivial or unavailable. The integration of this framework into automated, model-wide interpretability toolchains could catalyze new advances in mechanistic understanding, repair, and steering in large foundation models.
Conclusion
This work introduces a unified, theoretically grounded, and empirically robust distributional OT framework for cross-layer SAE feature comparison and scalable circuit compression. The approach enables precise semantic alignment between features from disparate latent spaces and supports the systematic reduction of complex causal circuits into actionable, interpretable supernodes, providing a scalable path forward for mechanistic analysis in modern LLMs (2605.28567).