- The paper introduces a novel checklist-based RL framework that decomposes instructions into atomic criteria to yield dense, soft rewards.
- It rigorously analyzes the bias–variance tradeoff, showing item-level rewards reduce variance by a factor of 1/K under conditional independence.
- The study demonstrates that self-verification with stabilization mechanisms significantly improves instruction adherence and out-of-distribution transfer.
Soft-SVeRL: Checklist-Based Self-Verified RL for Instruction Following
Soft-SVeRL addresses a central limitation in RL optimization of LLMs: when the reward signal is sparse, noisy, or only partially verifiable, standard RL with binary correctness (as in code or mathematical reasoning) becomes suboptimal. Many instruction-following tasks involve multi-constraint prompts with heterogeneous requirements—formatting, semantic, keyword inclusion/exclusion, length, etc.—where binary rewards fail to capture partial progress, and holistic LLM-based verifiers compress nuanced requirements into a single noisy approval judgement. The paper formalizes this challenge and proposes decomposing instructions into explicit, atomic checklist criteria, each scored by an LLM verifier, then aggregating item-level rewards to compute dense, soft feedback for RL.
This brings forth two new sources of error: noise in item-level judgments, and bias from awarding partial credit to incomplete responses. The paper rigorously analyzes the resulting bias-variance tradeoff, showing that under weakly correlated item-level verification errors, checklist-based rewards reduce reward estimation variance by a factor of $1/K$ (number of checklist items), and only when partial-credit bias remains controlled does decomposition outperform holistic judgment for RL optimization.
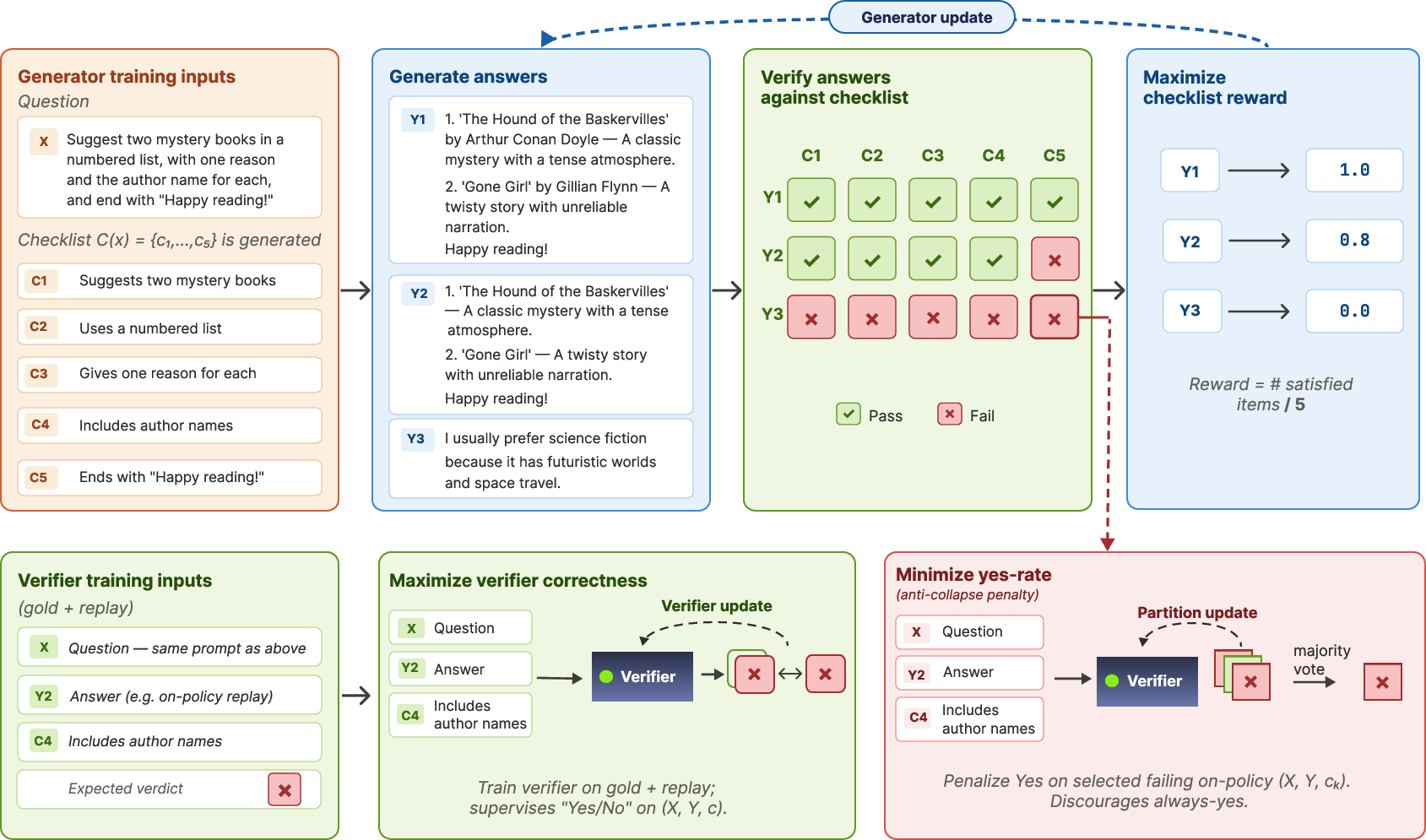
Figure 1: Overview of Soft-SVeRL’s pipeline—prompt decomposition, itemwise LLM verification, reward aggregation, and verifier-side stabilization against reward inflation.
Methodology
Soft-RLVR: Checklist-Based Soft Rewards via LLM Verification
The primary framework, Soft-RLVR, casts RL reward construction as prompt decomposition: each instruction is converted to a numbered checklist of essential yes/no verifiable items via LLM-based checklist generation, then candidate completions are evaluated itemwise by an LLM verifier prompted to judge satisfaction for each criterion. The reward is defined as the fraction of items judged satisfied:
Rsoft(x,y;ϕ)=K1k=1∑Kρϕ(x,y,ck)
where ρϕ denotes the verifier's judgment on item ck. Multiple verifier rollouts per item are aggregated to mitigate sampling noise, typically via majority vote or thresholding the empirical pass rate.
This mimics the dense reward structure of unit-test RLVR in code generation, but adapts it to domains lacking exact symbolic checkers. Partial credit is awarded for incomplete responses, distinguishing degrees of compliance and providing shaped feedback to the generator.
Self-Verification and Stabilization in Soft-SVeRL
The self-verifying extension, Soft-SVeRL, merges generator and verifier parameters into a single model. This increases training efficiency and removes the dependence on external reward models, but introduces a critical collapse mode: always-yes reward inflation, where the generator–verifier jointly drift to over-permissive itemwise approval (i.e., the verifier simply says Yes for all items). This can cause measured reward to rise while task performance deteriorates, due to gradient coupling and shared inductive biases.
To counteract reward inflation and correlated bias, Soft-SVeRL introduces explicit stabilization mechanisms:
- Verifier co-training: Gold-labeled item-level examples plus on-policy replay data anchor the verifier toward ground-truth checklist satisfaction, mitigating drift from generator-induced permissiveness.
- Partition-style Yes-rate penalty: Mixed-vote items (partial satisfaction, non-strict successes) receive an anti-collapse regularization term that pushes Yes rates downward, counteracting uniform reward inflation.
Empirical aggregation of multiple verifier votes per item reduces reward noise further, and carefully tuning the relative strengths and thresholds of co-training vs. anti-collapse penalty is essential for stable shared-parameter optimization.
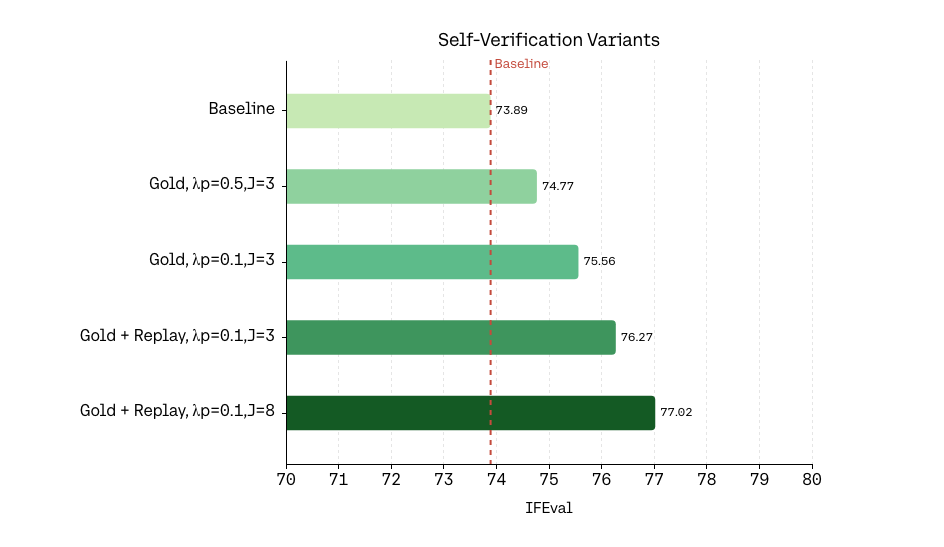
Figure 2: Self-verification ablations showing the impact of co-training, replay, multiple verifier votes, and partition penalty on instruction adherence.
Theoretical Analysis
The paper provides a mathematical characterization of checklist verification’s bias–variance tradeoff. Assume strict success target S∗ and partial credit Sˉ∗; let p,q denote sensitivity and specificity of holistic verifiers, and p′,q′ for item-level verifiers. Checklist decomposition reduces reward variance (conditionally independent item-level errors) but admits partial credit bias for non-strict responses.
Key results:
- Variance Reduction: Under conditional independence, variance drops as O(1/K).
- Bias Control: Checklist rewards outperform holistic only when item-level sensitivity is higher and partial-credit bias is sufficiently small.
Checklist quality and verifier specificity are critical; increasing item count cannot compensate for poor decomposition or permissive judgments. These analytical predictions are empirically validated.
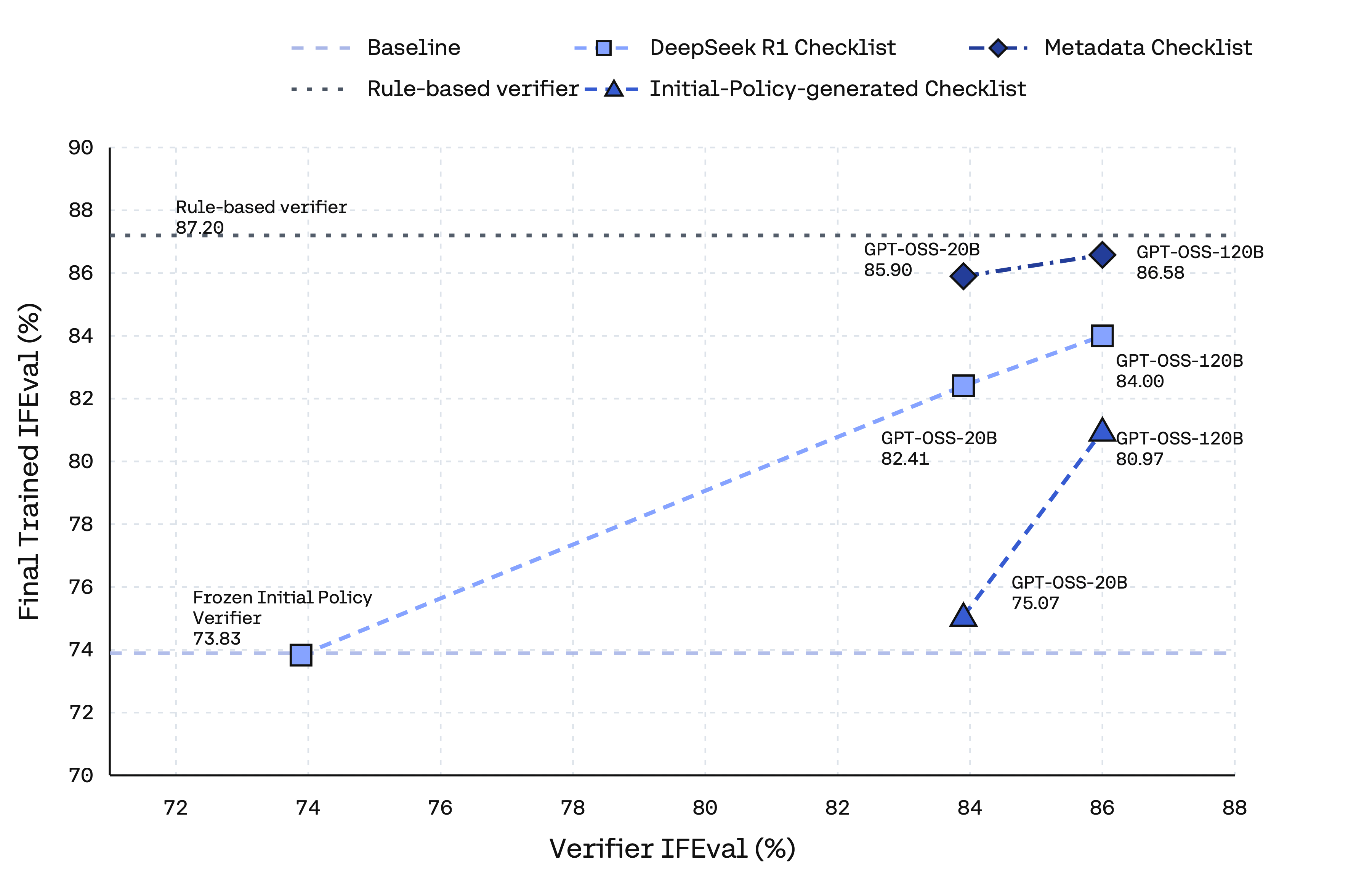
Figure 3: Verifier and checklist quality effect—stronger verifiers and high-fidelity checklists drive higher task compliance, with metadata constraints (ground-truth) representing upper bound.
Empirical Evaluation
Training on the Llama-Nemotron dataset using DeepSeek-R1 generated checklists, the paper demonstrates substantial gains on IFEval (instruction-following evaluation), with Soft-RLVR increasing adherence by over 10 points compared to baseline. Out-of-distribution transfer is observed for MATH500 and AIME benchmarks, indicating that RL with item-level rewards does not degrade mathematical reasoning capabilities.
Checklist and verifier quality are ablated: gold metadata checklists and rule-based verifiers represent oracle upper bounds, while initial policy and DeepSeek-R1 checklists, paired with weaker or stronger external verifiers, show that both components are pivotal. Self-verification, while removing the need for external reward models, requires explicit regularization to avoid collapse.
Checklist-based training consistently outperforms holistic (non-checklist) verification when the verifier is noisier, aligning with theoretical bias–variance arguments. As verifier scale increases, the gap narrows, with checklist-based methods retaining an edge on structure-rich benchmarks like math.
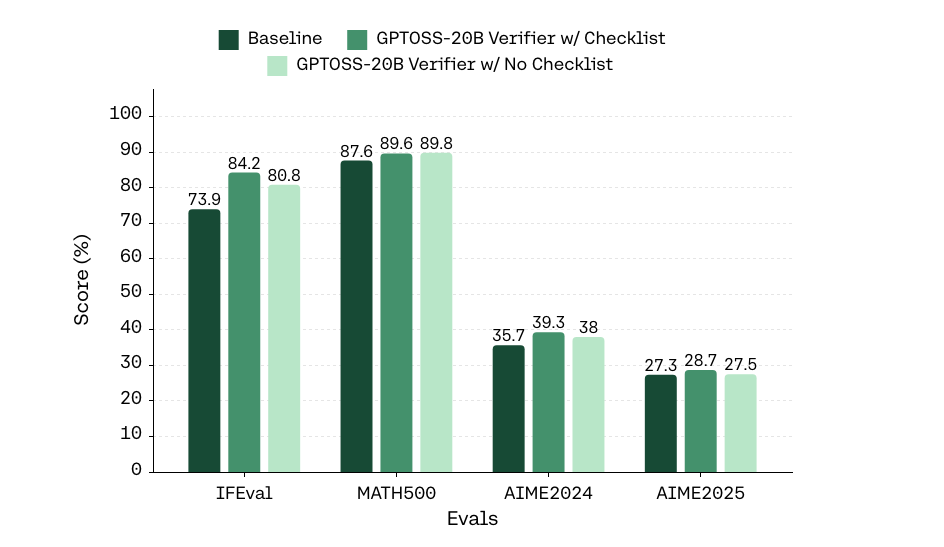
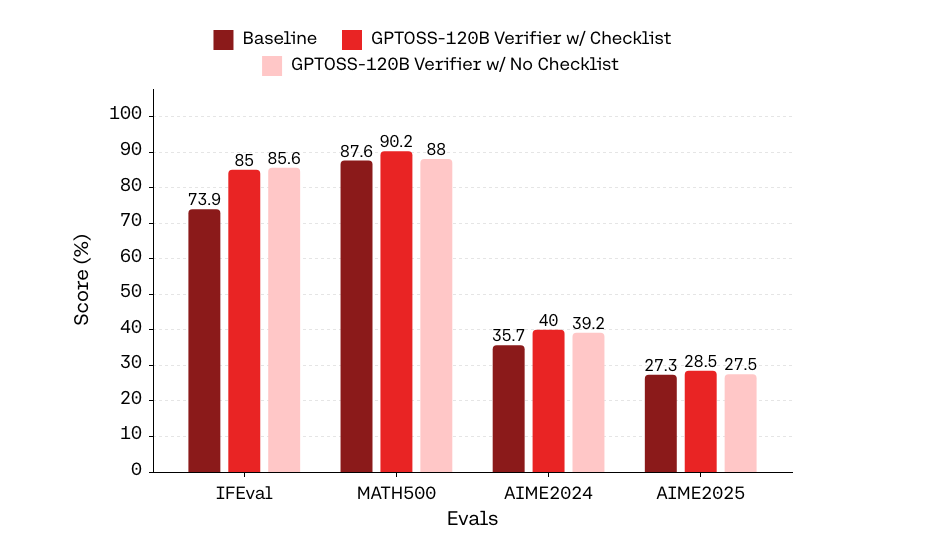
Figure 4: Checklist-based vs. holistic verification performance comparison across verifier scales, highlighting decomposition advantage in noisy scenarios.
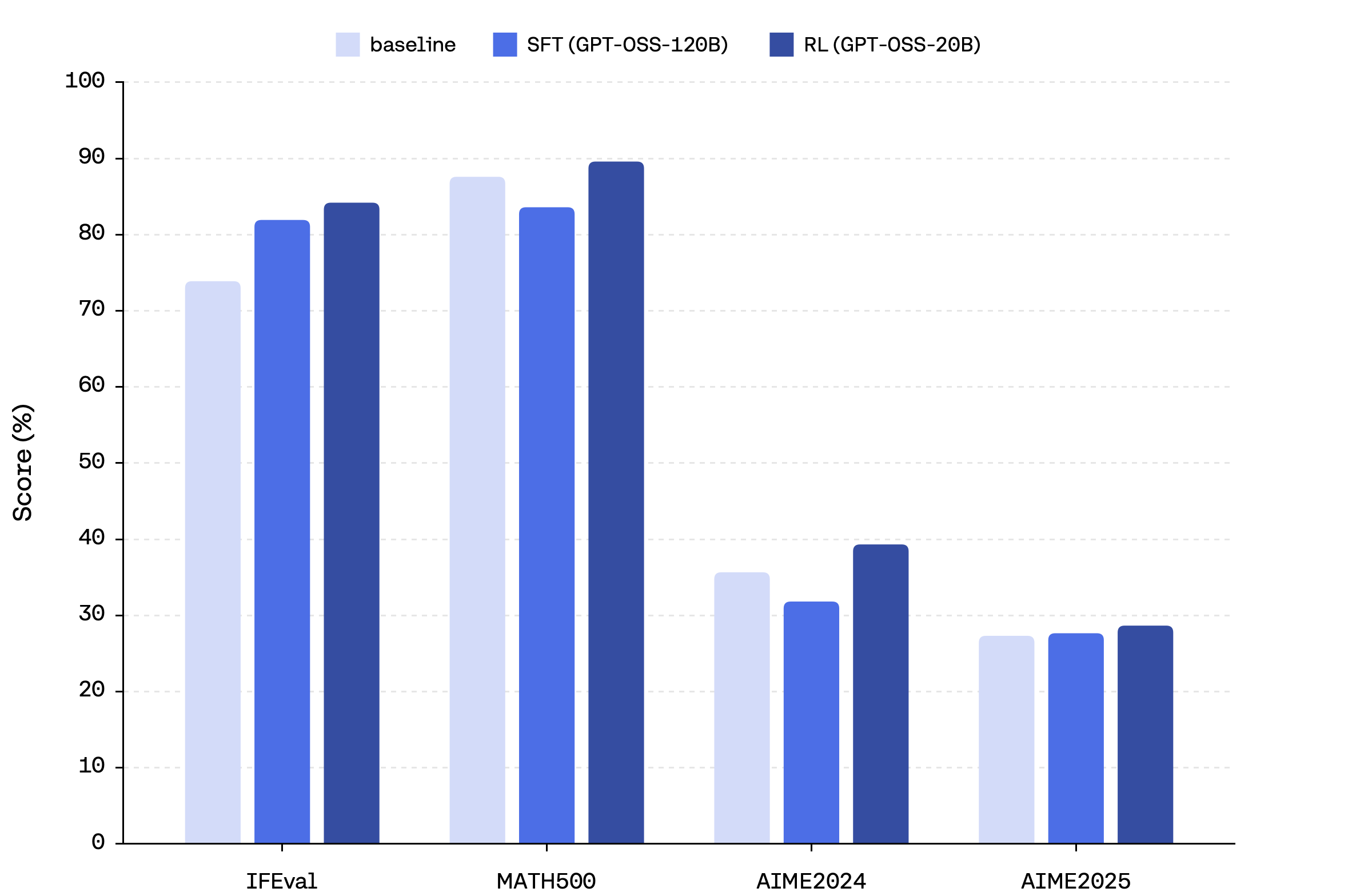
Figure 5: RL with smaller LLM-based verifier outperforms SFT with larger outputs, especially avoiding math performance degradation.
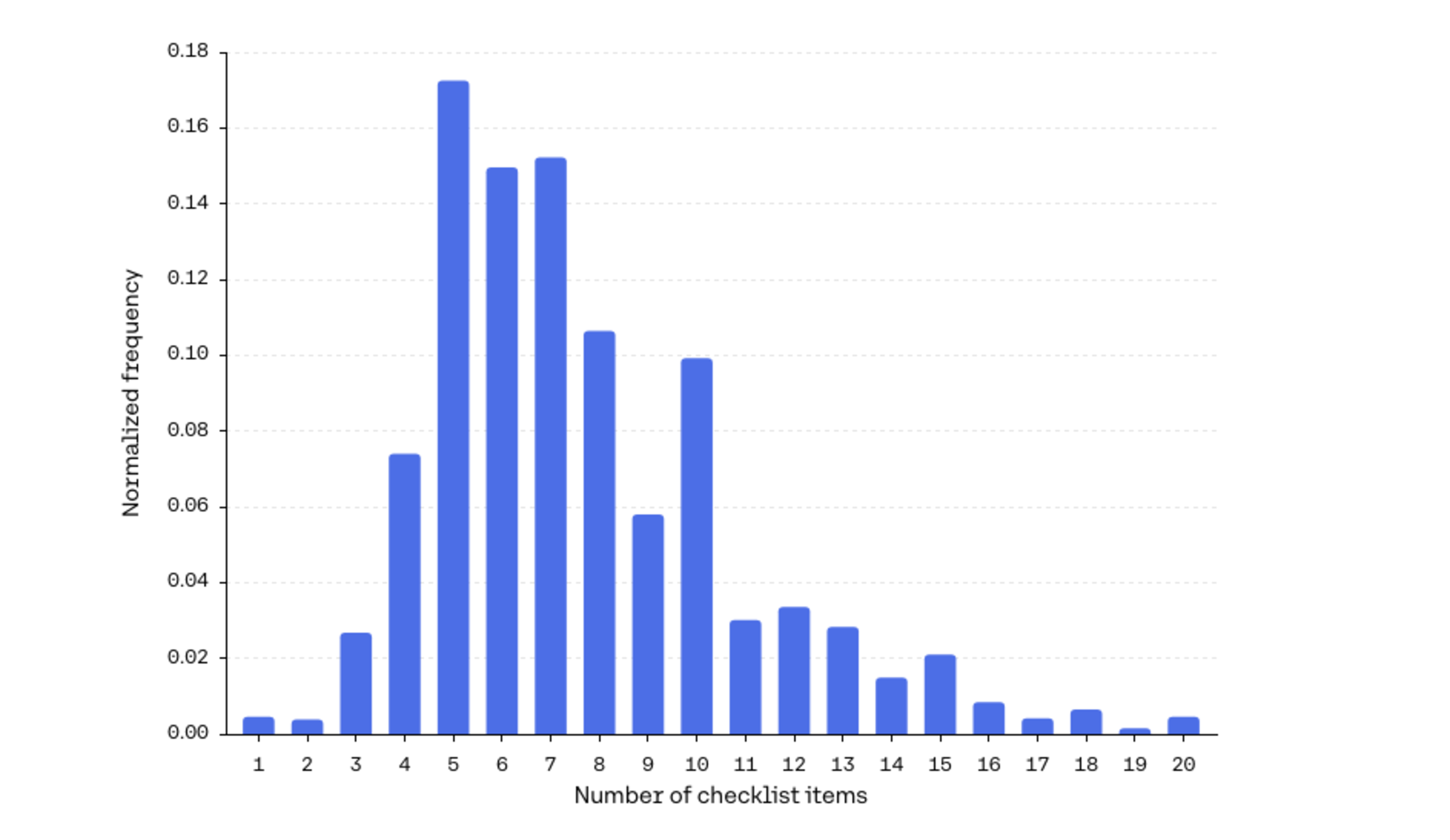
Figure 6: Distribution of generated checklist lengths, indicating typical prompt decompositions contain 5–8 items.
Implications and Future Directions
This framework generalizes dense RL reward shaping to tasks and domains lacking symbolic verifiers. Practically, checklist-based RL enables effective optimization for open-ended instruction following, complex output formats, and compositional prompts. Theoretical implications include rigorous bias–variance tradeoff analysis for RL reward modeling and new stabilization methods for self-verifying agents.
Limitations are noted: checklist decomposition assumes atomic, necessary criteria, which may not hold for highly subjective or holistic tasks (e.g., creative writing, nuanced dialog). The approach demands high-quality checklist generation and item-level supervision, and shared-parameter self-verification remains challenging at larger model scales and broader task domains.
Future work should extend these techniques to unconstrained, subjective multi-turn dialog, explore scalable checklist generation, and further advance reward modeling beyond exactly verifiable domains. Soft verification via dense, decomposed criteria may prove foundational for robust RL optimization of generalist LLMs.
Conclusion
Soft-SVeRL establishes a principled, empirically effective framework for RL optimization in non-verifiable instruction-following tasks via checklist decomposition and itemwise LLM verification. Theoretical and empirical analyses affirm the importance of reward structure and verifier specificity, and stabilization techniques are essential for shared-parameter self-verification. Dense, actionable reward signals constructed from decomposed criteria enable RLVR beyond exact symbolic domains, and checklist-based soft verification is positioned as a key technique for advancing instruction adherence and generalist LLM behavior (2605.28561).