- The paper introduces a creator-centric benchmark that overcomes limitations of conventional T2I evaluations by incorporating professional artist insights.
- It employs a multi-tiered taxonomy with 56 facets and an expert-in-the-loop prompt pipeline to deliver transparent, rubric-based scoring.
- Findings reveal that while models excel in basic image quality, they underperform in implicit world knowledge and creative reasoning, highlighting improvement areas.
Qwen-Image-Bench: Advancing Creator-Centric Evaluation in Text-to-Image Synthesis
Motivation and Benchmark Design
Qwen-Image-Bench addresses critical limitations in prevailing Text-to-Image (T2I) evaluation frameworks. As state-of-the-art models dramatically improve prompt-following and basic image quality, conventional benchmarks anchored in CLIP-based semantic alignment and coarse aesthetics lose discriminative power and explanatory value. Qwen-Image-Bench is designed with direct involvement from professional artists to mirror authentic creative workflows, and is grounded in the demands of real-world image creation.
The benchmark organizes evaluation via a top-down hierarchical taxonomy spanning three levels: five first-level pillars (Quality, Aesthetics, Alignment, Real-world Fidelity, Creative Generation), 23 second-level sub-capabilities, and 56 third-level facets, each associated with precise rubrics (Figure 1).
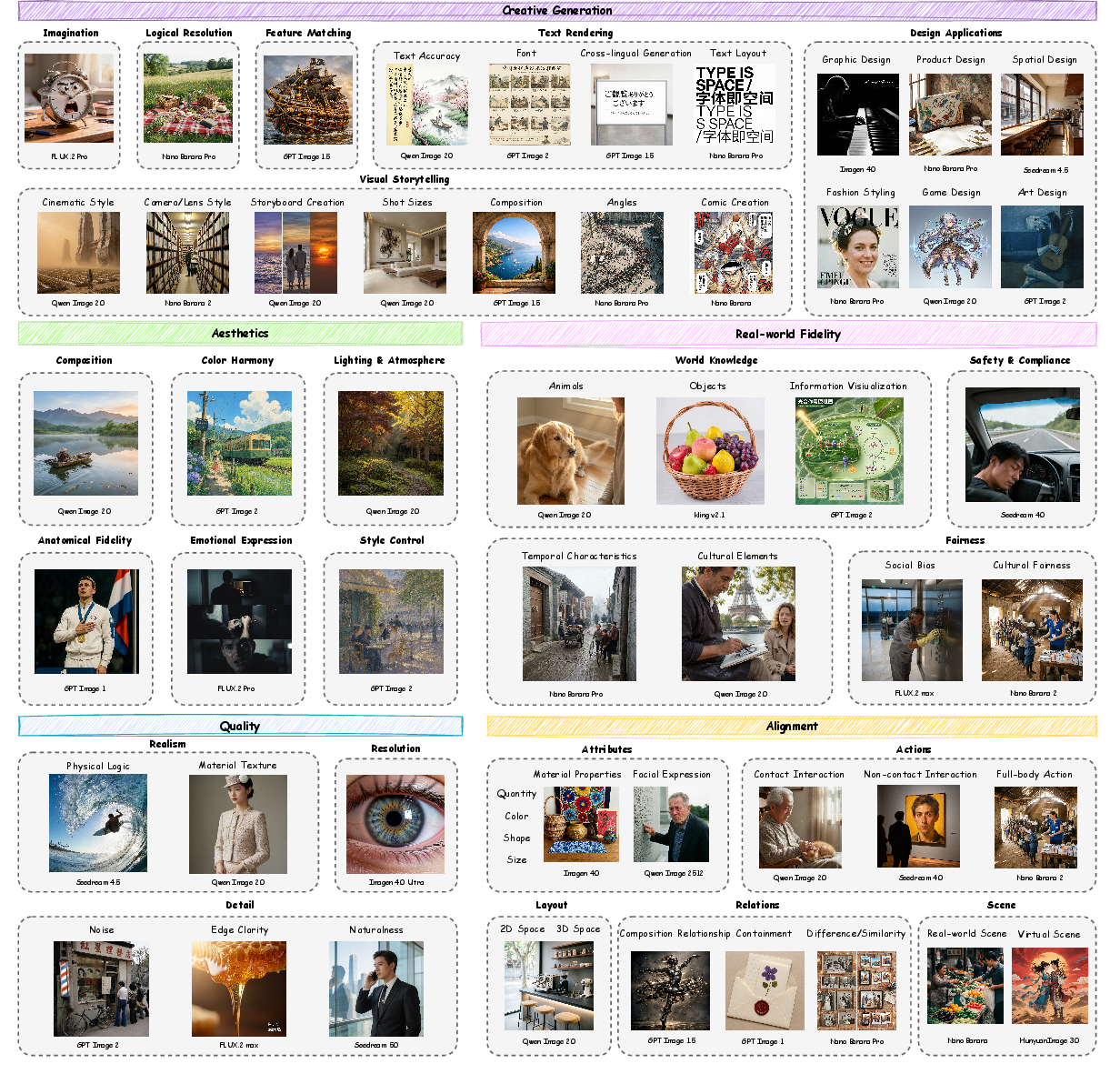
Figure 1: Qwen-Image-Bench Evaluation Dimensions, illustrating the multi-tiered taxonomy that captures nuanced creation-specific capabilities.
Distinctively, Real-world Fidelity and Creative Generation are explicitly evaluated—dimensions systematically neglected in prior benchmarks but central to creator workflows. Real-world Fidelity interrogates models' ability to reconstruct physical laws, structured world knowledge, and cultural context. Creative Generation tests for imaginative expression, stylistic depth, and narrative coherence.
Prompt Construction and Evaluation Pipeline
Prompt generation is executed through a multi-stage expert-in-the-loop process (Figure 2), ensuring each prompt exercises multiple fine-grained facets and is anchored to practical creative scenarios. The prompt suite consists of 1,000 bilingual (Chinese/English) prompts, evenly split between short and long variants to probe robustness across linguistic complexity and creator needs.
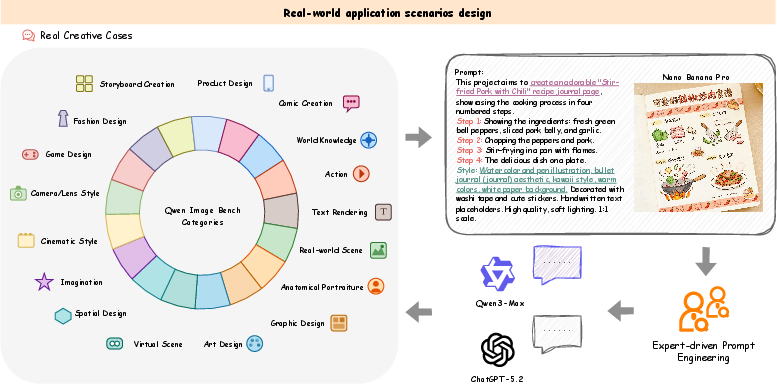
Figure 2: Pipeline for constructing real-world application prompts with taxonomy-driven sampling and artist review.
The evaluation pipeline is centered on the Q-Judger, a unified Judge Model based on Qwen3.6-27B, trained on more than 130,000 prompt-image pairs annotated by 80 professional experts under blind procedures and triple-review protocols. Q-Judger outputs a rubric-grounded score vector across all 56 facets for each prompt-image pair, providing fully attributable diagnostics rather than opaque aggregates. Scores are mapped non-linearly onto a [0,100] scale, emphasizing the practical distinction between unacceptable and acceptable outputs, with bottom-up aggregation yielding sub-capability, pillar-level, and overall scores.
Empirical Findings and Model Differentiation
Eighteen leading T2I models are evaluated, including GPT Image 2, Nano Banana Pro, Qwen Image 2.0 Pro, Seedream 5.0, Imagen 4.0 Ultra, and HunyuanImage 3.0. GPT Image 2 dominantly attains the highest overall score (64.7), outperforming all competitors across every pillar (Figure 3).
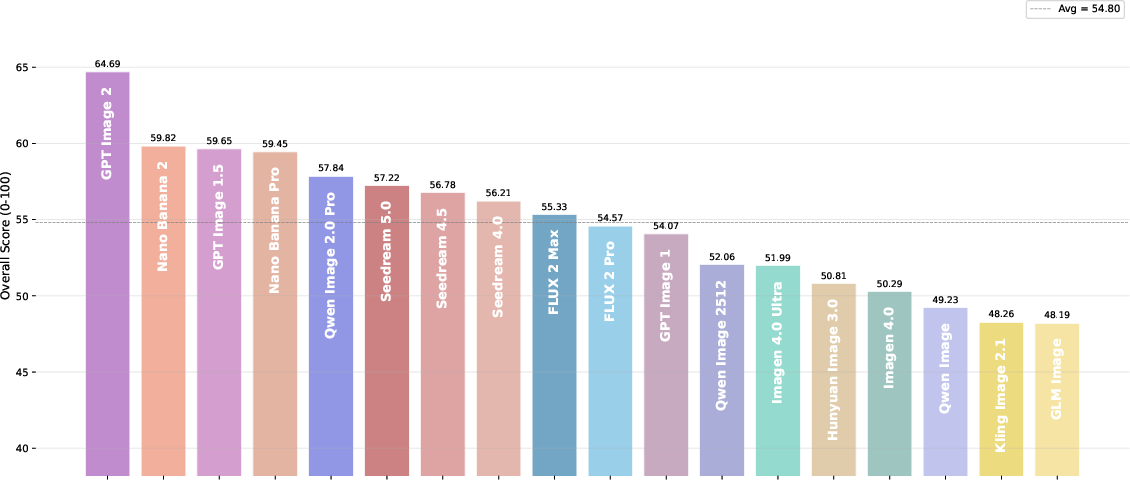
Figure 3: Overall score ranking for 18 T2I models, showing effective separation and clustering across capability tiers.
Capability profiles, visualized via radar charts (Figure 4), reveal structural strengths and systemic weaknesses. The industry-wide bottlenecks reside in facets requiring implicit world knowledge: Physical Logic, Anatomical Fidelity, Animals, Objects, Contact Interaction, where even best-performing models score below 44.
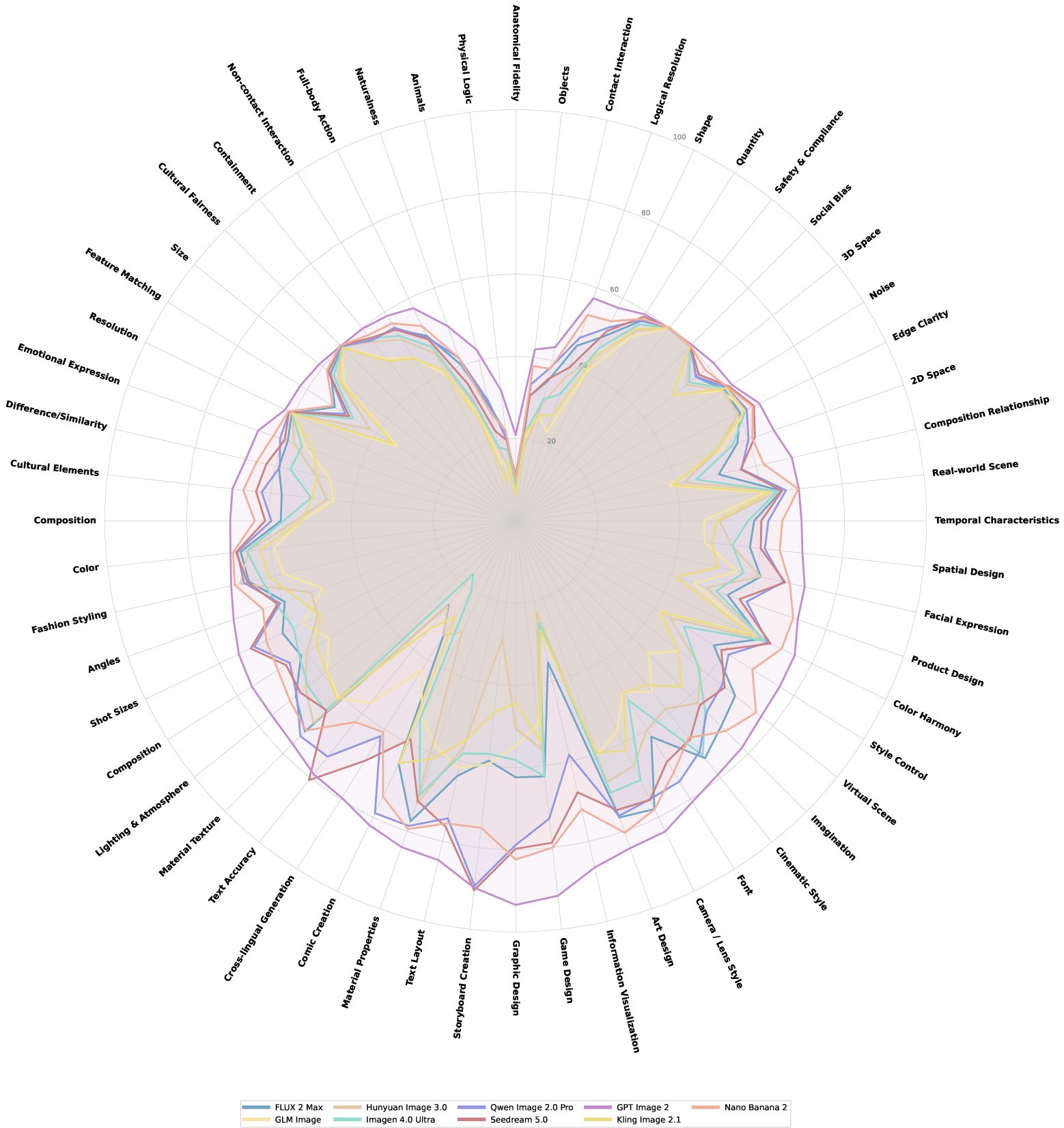
Figure 4: L3-level radar chart mapping capability profiles across all 56 third-level facets, exposing capability ceilings and strengths.
Variance analysis (Figure 5) establishes that Creative Generation and Real-world Fidelity are the most discriminative axes, exhibiting exceptionally high inter-model variance and thus separating frontier models from mid-tier competitors.
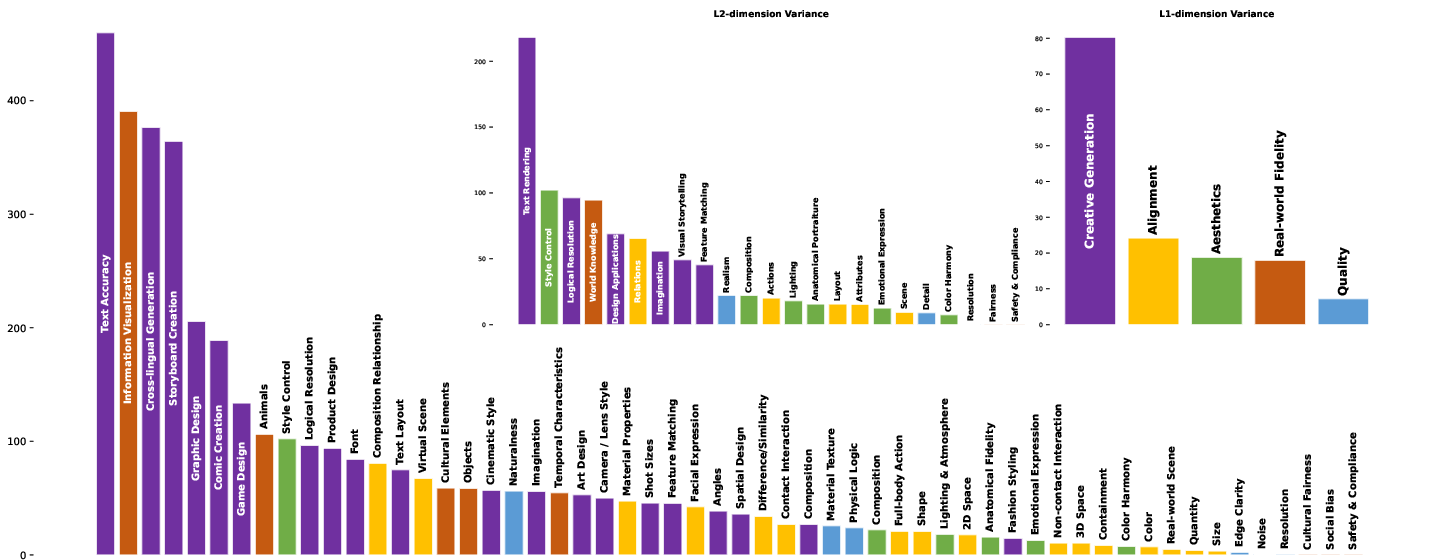
Figure 5: Inter-model variance across taxonomy levels; highest at L3 for knowledge, design, and creative tasks.
Sub-capability and facet rankings (Figure 6) highlight dimensions most valued by creators yet poorly served by extant models. Graphic Design, Game Design, Text Accuracy, and World Knowledge induce sharp tier boundaries and threshold effects.
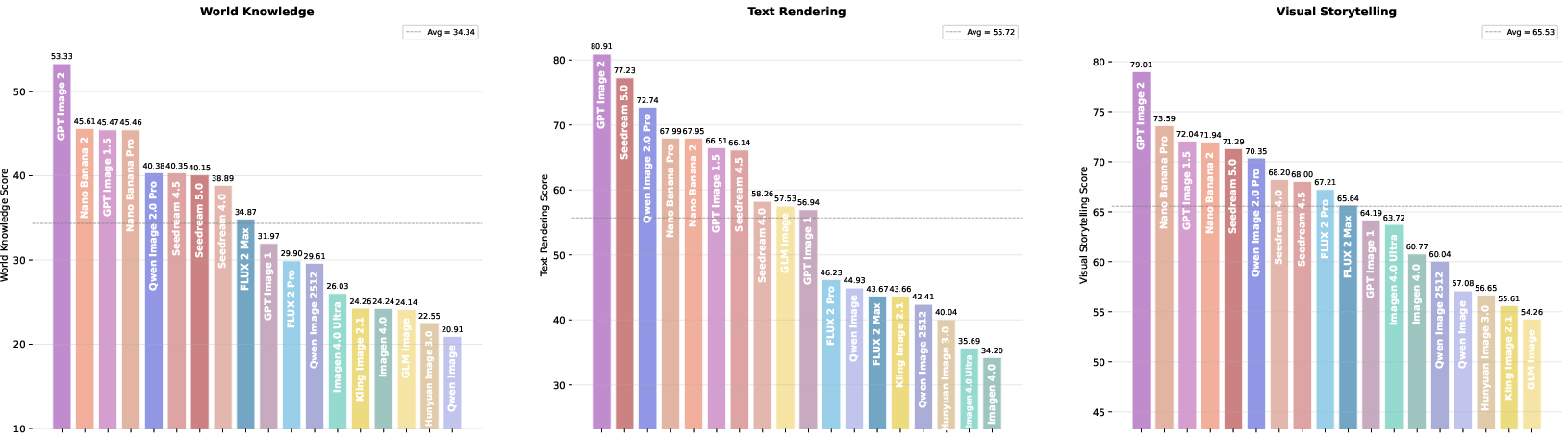
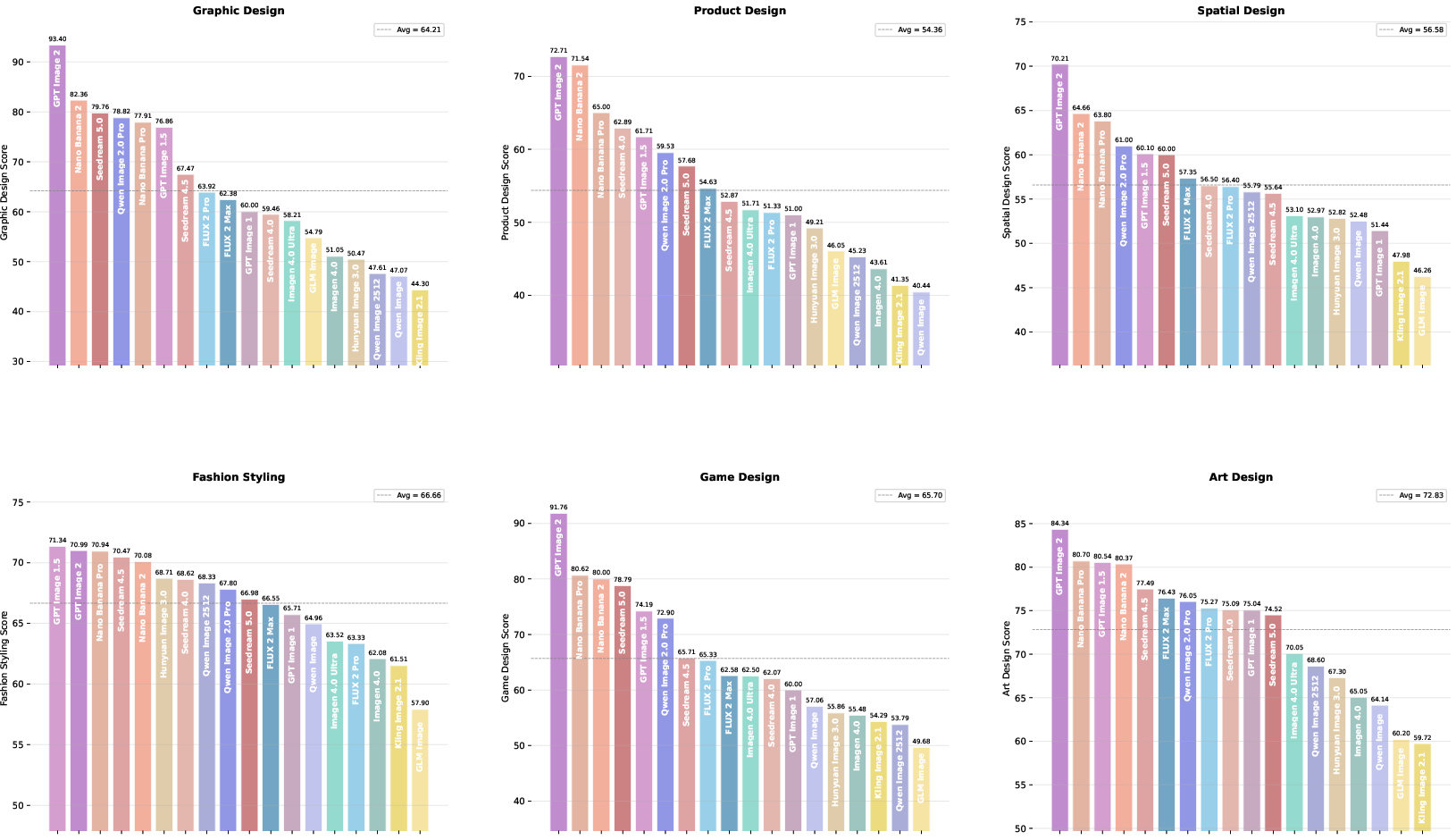
Figure 6: Sub-capability and facet-level rankings, emphasizing creator-driven dimensions and fine-grained specialization.
Per-pillar rankings (Figure 7) and capability landscape visualizations (Figure 8) further expose that industry-wide convergence exists only for basic image quality, not for high-level creative or reasoning tasks.
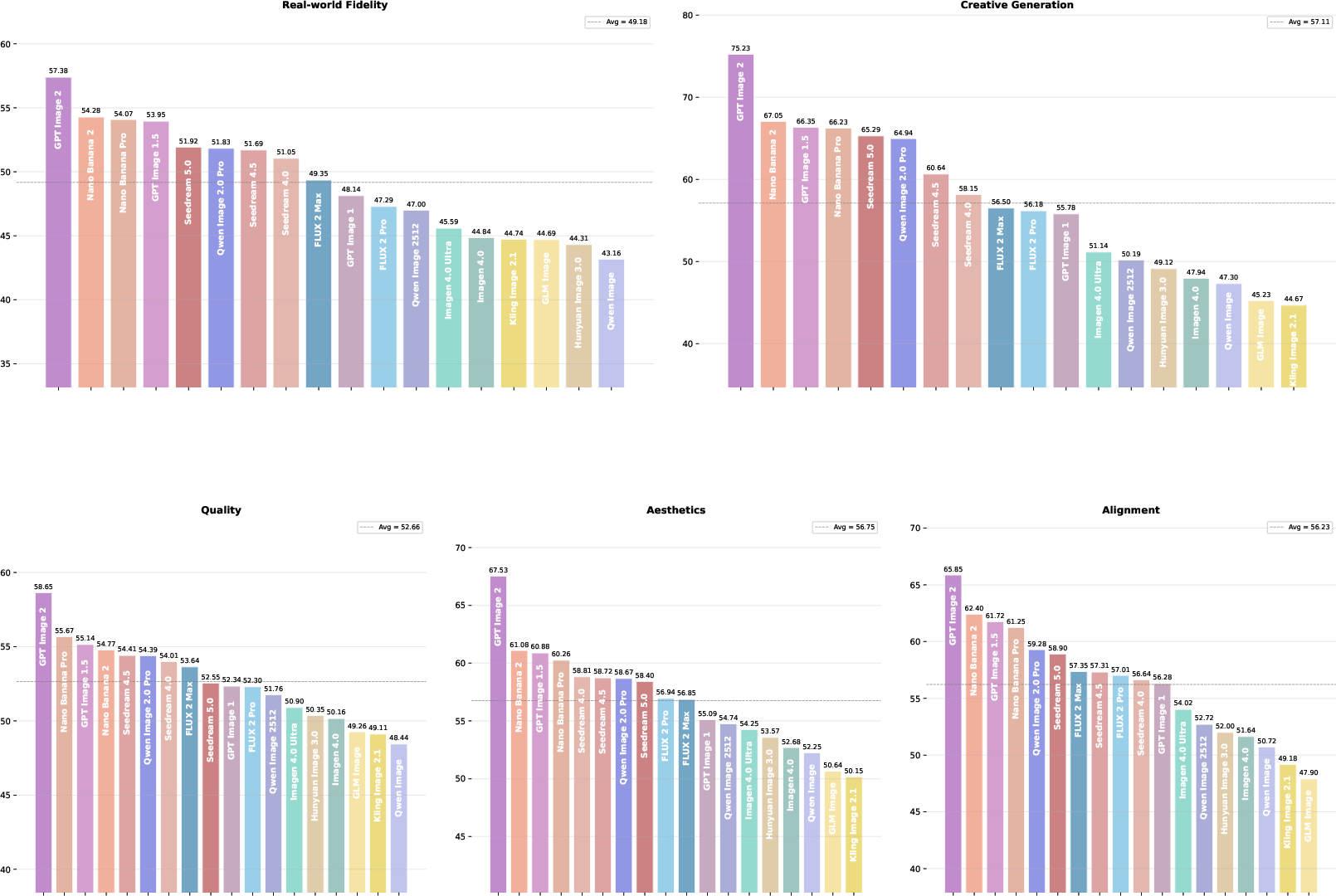
Figure 7: Per-pillar model rankings reveal dimension-specific strengths rarely predicted by single-score metrics.
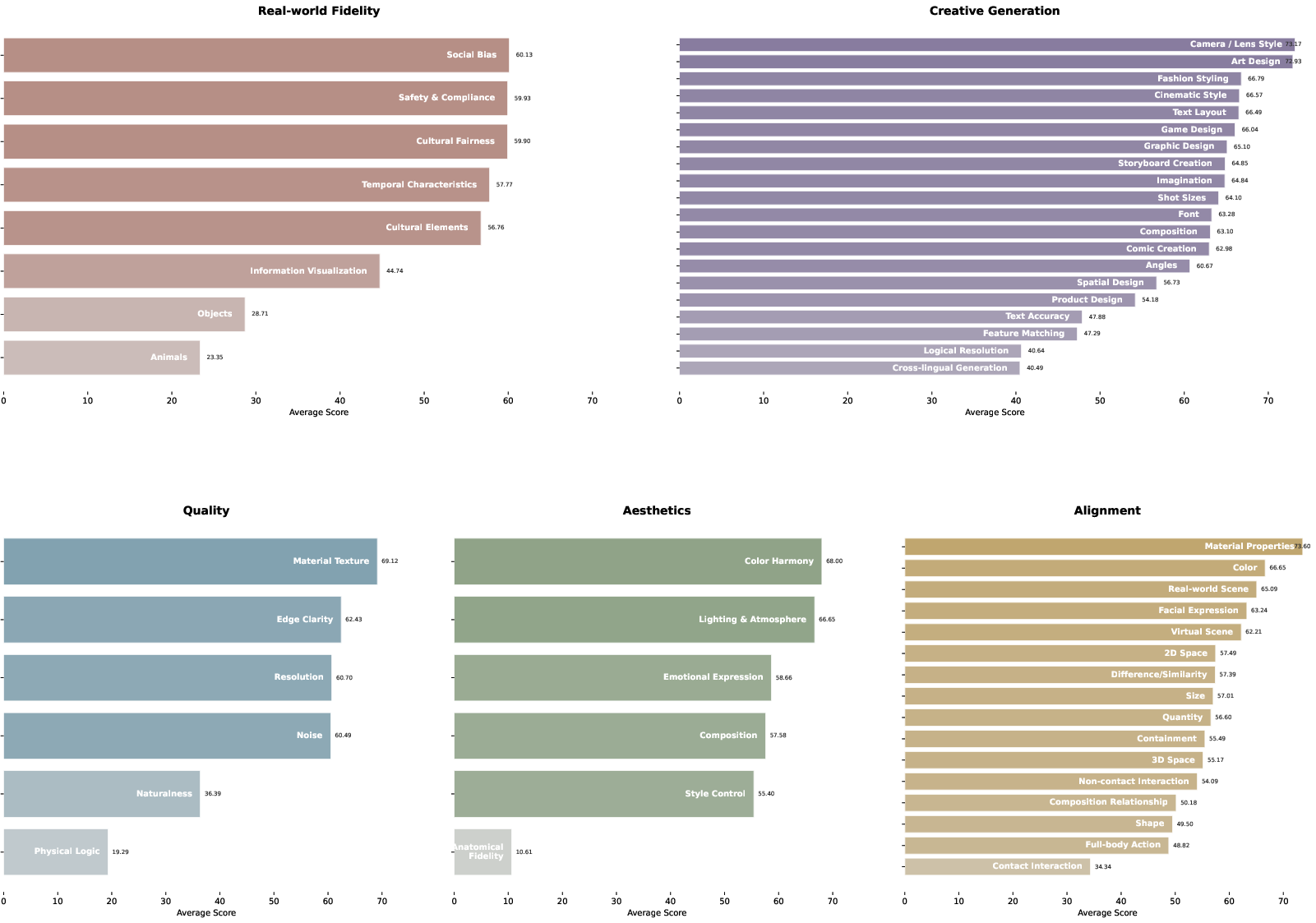
Figure 8: Mean scores for each L3 facet across models, grouped by pillar, mapping the aggregate capability landscape.
Score heatmaps (Figures 9 and 10) clearly visualize sharp transitions across tiers and uniform collapse on systemic ceilings, reinforcing that benchmarks must evolve to maintain meaningful discrimination at the frontier.
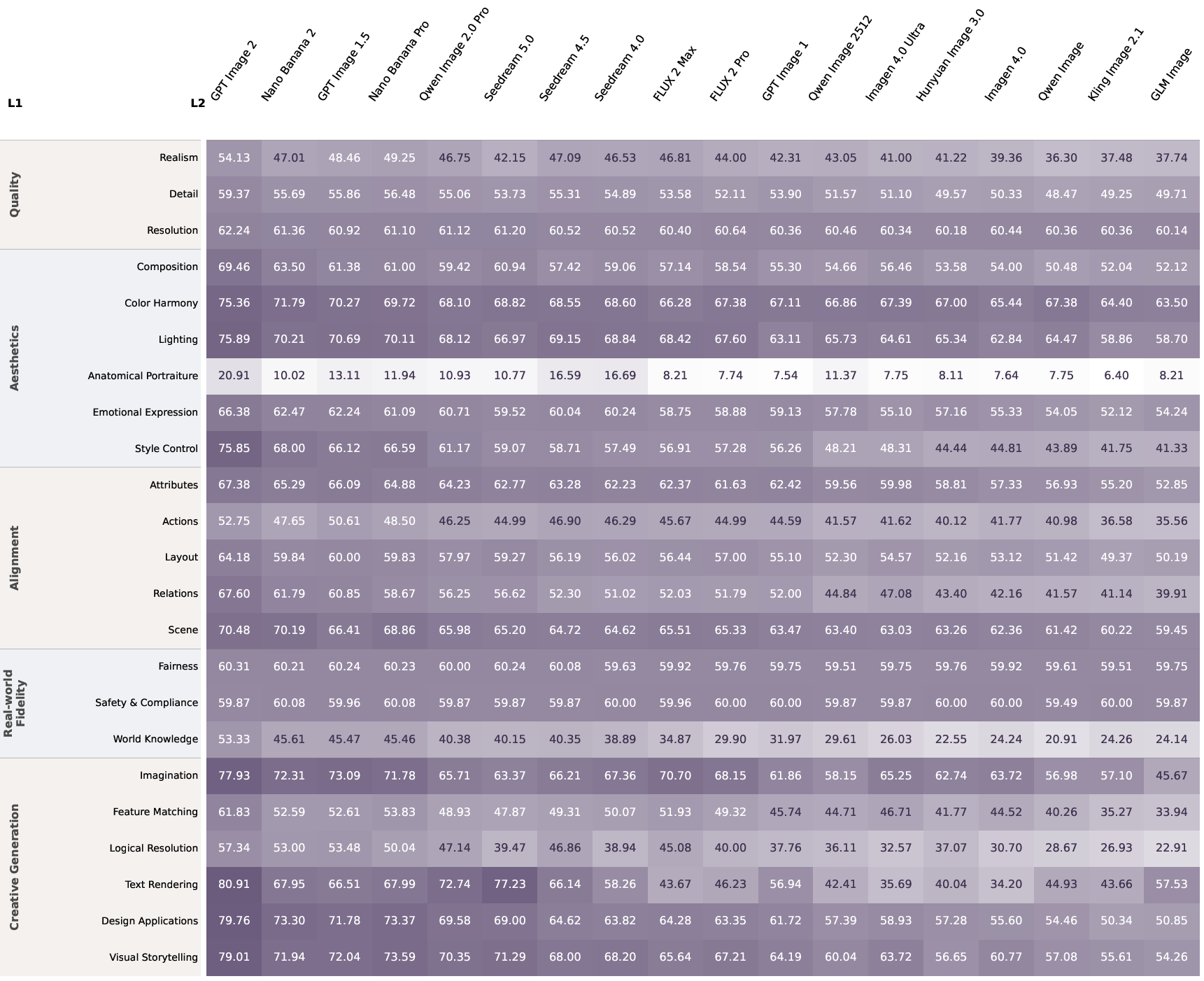
Figure 9: Aggregated score heatmap at the L2 sub-capability level, confirming specialization and convergence patterns.
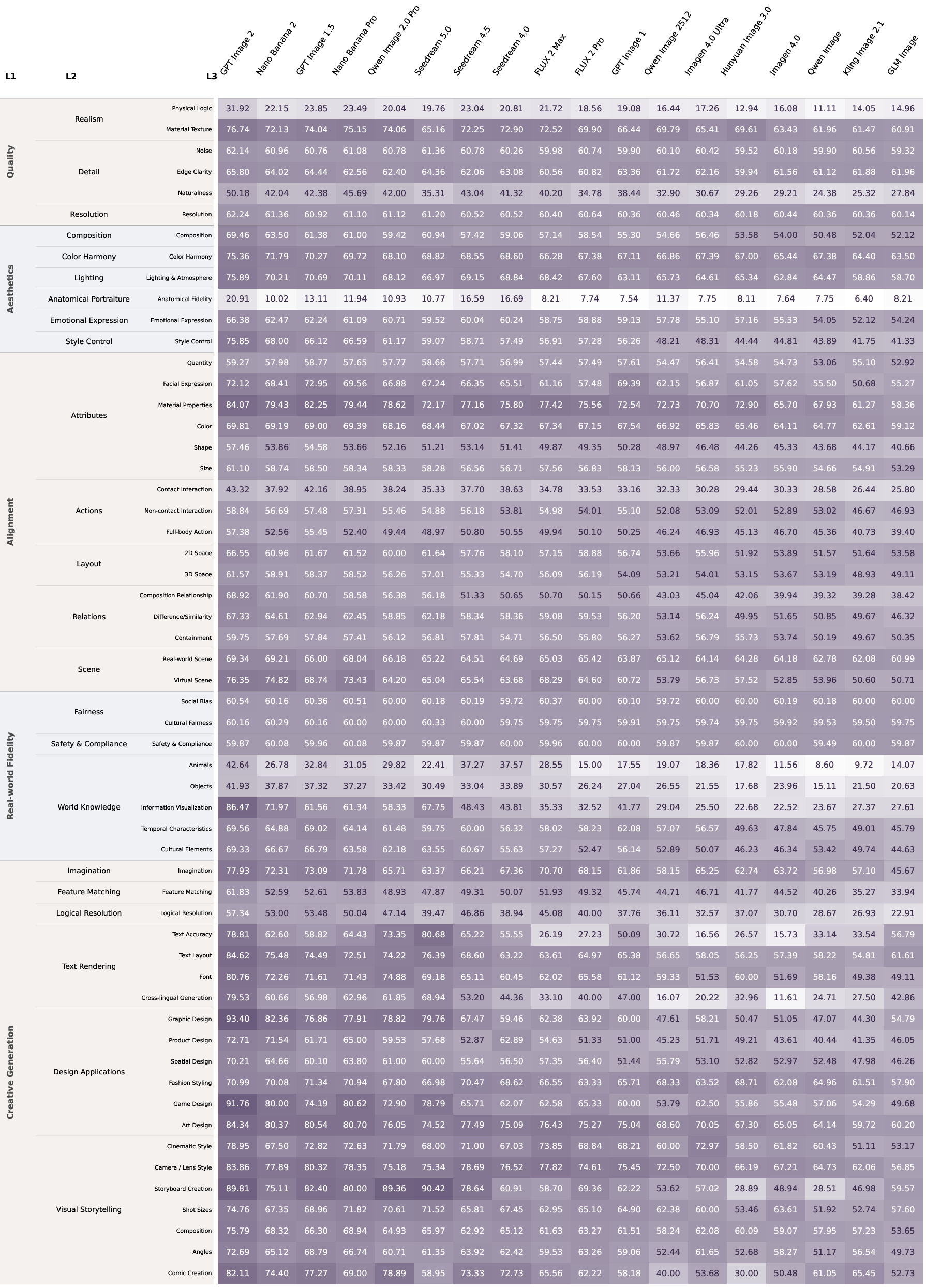
Figure 10: Full L3-level heatmap, showing left-to-right gradients and dimension-specific bottlenecks.
Implications for T2I Research and Future Directions
Qwen-Image-Bench demonstrates that basic prompt-following and image quality have saturated; practical utility pivots on knowledge-grounded realism, creative generation, and precise execution. The explicit taxonomy and fine-grained rubric-driven evaluation expose actionable gaps in anatomical fidelity, physics, narrative structure, and text rendering. Tier-gap analyses indicate that lower-tier models can approach frontier performance by targeting design execution, logical reasoning, and language-understanding-heavy facets.
Crucially, current models exhibit a pronounced perception-to-cognition divide: surface reproduction (style, color, composition) is reliably mastered, but implicit reasoning and world knowledge remain elusive. Bridging this gap likely demands architectural integration of external knowledge sources, reasoning modules, or structured abstraction layers rather than simple scaling of data or parameters.
For systematic benchmark evolution, the authors propose dynamic prompt set refreshes, expansion towards video and interactive modalities, and automated leaderboard systems—critical steps to sustain discriminative robustness in a rapidly advancing ecosystem.
Conclusion
Qwen-Image-Bench sets a new standard for creator-centric T2I evaluation, capturing nuanced capabilities overlooked by prior benchmarks and achieving high alignment with professional judgment (ρ=0.92 Spearman). Its multi-dimensional rubric and transparent aggregation empower explainable, actionable diagnostics and reliably separate leading models into distinct tiers. As T2I synthesis becomes integral to creative workflows, benchmarks modeled on practical creator standards, underpinned by fine-grained expert annotation, are essential for guiding the next phase of research: moving from perceptual fidelity to authentic cognition, reasoning, and creative expressivity in generative models (2605.28091).

