- The paper demonstrates a novel dual-encoding approach combining Qwen2.5-VL and a VAE for accurate text rendering and precise image editing.
- It introduces innovative techniques including MSRoPE positional encoding and a progressive curriculum learning strategy to enhance semantic alignment and visual fidelity.
- The report validates Qwen-Image with state-of-the-art results across diverse benchmarks, setting a new standard for unified multimodal tasks.
Qwen-Image: A Foundation Model for High-Fidelity Text Rendering and Image Editing
Introduction
Qwen-Image is introduced as a large-scale image generation foundation model, with a particular focus on complex text rendering and precise image editing. The model addresses two persistent challenges in the field: (1) robust alignment of generated images with complex, multi-faceted text prompts—including multi-line, multi-language, and layout-sensitive text rendering—and (2) high-fidelity, semantically consistent image editing, where only targeted regions are modified while preserving global visual and semantic coherence. The technical report details a comprehensive data pipeline, a progressive curriculum learning strategy, a dual-encoding multi-task training paradigm, and scalable infrastructure optimizations, culminating in a model that achieves state-of-the-art results across a wide spectrum of image generation and editing benchmarks.
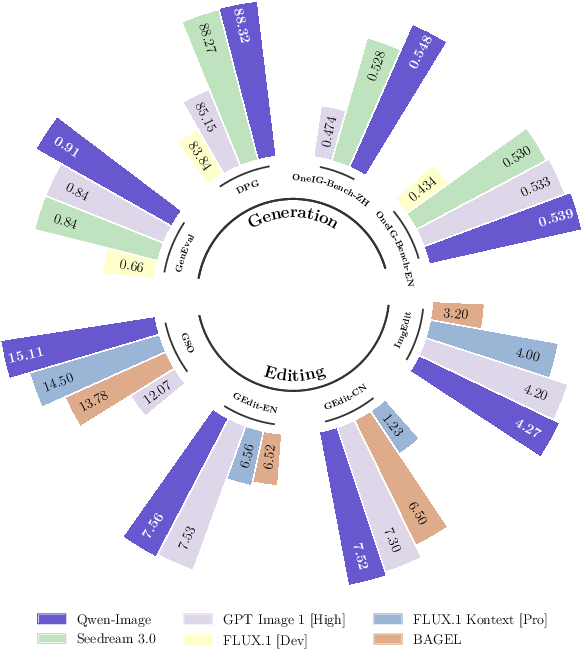
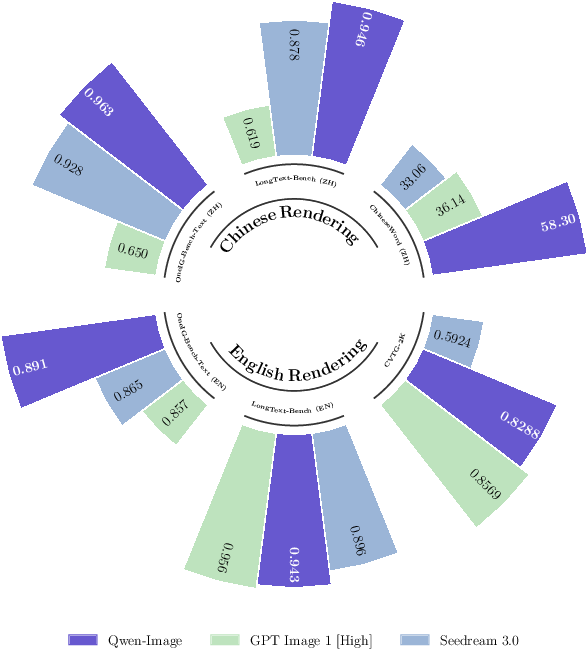
Figure 1: Qwen-Image exhibits strong general capabilities in both image generation and editing, while demonstrating exceptional capability in text rendering, especially Chinese.
Model Architecture
Qwen-Image employs a double-stream Multimodal Diffusion Transformer (MMDiT) architecture, conditioned on both a frozen Qwen2.5-VL (Multimodal LLM) and a VAE encoder. The architecture is designed to jointly model text and image modalities, leveraging a novel Multimodal Scalable RoPE (MSRoPE) positional encoding scheme for improved alignment and scalability.
- Condition Encoder: Qwen2.5-VL is used for extracting semantic features from text and images, benefiting from pre-aligned language and vision spaces and strong multimodal capabilities.
- VAE Tokenizer: A single-encoder, dual-decoder VAE (based on Wan-2.1-VAE) is adopted, with the encoder frozen and the image decoder fine-tuned on a text-rich corpus. This design supports both image and video modalities, facilitating future extension to video generation.
- Diffusion Backbone: The MMDiT backbone models the joint distribution of noise and image latents under text guidance, with MSRoPE enabling effective joint positional encoding for text and image tokens.
The dual-encoding mechanism—feeding both semantic (Qwen2.5-VL) and reconstructive (VAE) representations—enables the model to balance semantic consistency and visual fidelity, particularly in image editing tasks.
Data Pipeline and Curriculum Learning
A critical component of Qwen-Image's success is its data pipeline, which emphasizes quality, diversity, and balance over sheer scale. The pipeline comprises:
- Data Collection: Billions of image-text pairs are collected and categorized into Nature, Design, People, and Synthetic Data, with careful balancing to ensure broad coverage and high-fidelity annotations.
- Multi-Stage Filtering: A seven-stage filtering process progressively refines the dataset, removing low-quality, misaligned, or unrepresentative samples, and introducing synthetic data at later stages to enhance text rendering capabilities.
- Annotation: An advanced captioning and metadata extraction framework is used, generating both detailed natural language descriptions and structured metadata (e.g., image type, style, watermarks) in a single pass.
- Text-Aware Data Synthesis: To address the long-tail distribution of textual content, especially in logographic languages, a multi-stage synthesis pipeline generates pure, compositional, and complex layout text images, ensuring exposure to rare characters and complex layouts.
A curriculum learning strategy is employed, starting with non-text images and simple prompts, and progressively introducing more complex text rendering and high-resolution images. This staged approach enables the model to first master general visual generation before specializing in text rendering and layout-sensitive tasks.

Figure 2: Showcase of Qwen-Image in complex text rendering, including multi-line layouts, paragraph-level semantics, and fine-grained details. Qwen-Image supports both alphabetic languages (e.g., English) and logographic languages (e.g., Chinese) with high fidelity.
Training and Optimization
Qwen-Image is pre-trained using a flow matching objective, which provides stable learning dynamics and is equivalent to maximum likelihood estimation. The training infrastructure is optimized for large-scale distributed training:
- Producer-Consumer Framework: Data preprocessing (VAE encoding, filtering) is decoupled from model training, enabling asynchronous, high-throughput operation across GPU clusters.
- Hybrid Parallelism: Megatron-LM is used for model parallelism, combining data and tensor parallelism for efficient scaling.
- Memory and Compute Optimization: Distributed optimizers are preferred over activation checkpointing to balance memory usage and training speed.
A multi-stage pre-training strategy is adopted, progressively increasing image resolution, introducing text rendering, refining data quality, balancing data distribution, and augmenting with synthetic data. Post-training includes supervised fine-tuning (SFT) on high-quality, human-annotated data, followed by reinforcement learning (RL) using Direct Preference Optimization (DPO) and Group Relative Policy Optimization (GRPO) for further alignment with human preferences.
Multi-Task and Image Editing Paradigm
Qwen-Image is extended to multi-task settings, supporting text-to-image (T2I), text-image-to-image (TI2I), and image-to-image (I2I) tasks within a unified framework. For image editing, both the original image (via VAE) and semantic features (via Qwen2.5-VL) are used as conditioning signals, enabling precise, context-aware modifications while preserving global consistency.
The MSRoPE positional encoding is further extended with a frame dimension to distinguish between pre- and post-editing images, facilitating complex editing operations such as style transfer, object manipulation, pose editing, and novel view synthesis.
Experimental Results
Qwen-Image is evaluated extensively on public benchmarks for both image generation and editing:
- General Image Generation: Achieves state-of-the-art or highly competitive results on DPG, GenEval, OneIG-Bench, and TIIF, demonstrating strong prompt adherence, compositionality, and style diversity.
- Text Rendering: Outperforms all prior models on Chinese text rendering (ChineseWord), achieves near-SOTA on English (CVTG-2K), and excels in long text rendering (LongText-Bench), with notable margins over commercial and open-source baselines.
- Image Editing: Demonstrates superior performance on GEdit, ImgEdit, and GSO, with strong semantic consistency and perceptual quality, and competitive results in novel view synthesis and depth estimation—approaching or surpassing specialized discriminative models in some cases.
Qualitative results further highlight Qwen-Image's ability to render complex, multi-line, and multi-language text with high fidelity, maintain style and content consistency in editing, and perform spatially coherent manipulations.
Implications and Future Directions
Qwen-Image represents a significant advance in the integration of text rendering and image editing within a single generative framework. The model's ability to handle complex, layout-sensitive, and multi-language text prompts positions it as a foundation for vision-language user interfaces (VLUIs), where visual explanations and structured multimodal outputs are essential.
The dual-encoding and multi-task training paradigm demonstrates that generative models can approach, and in some cases match, the performance of specialized discriminative models on classical vision tasks (e.g., depth estimation), suggesting a path toward unified multimodal understanding and generation.
The adoption of a video-compatible VAE and the demonstrated generalization to 3D and video-related tasks indicate that Qwen-Image is well-positioned for future extensions to video generation and spatiotemporal modeling.
Conclusion
Qwen-Image establishes a new standard for image generation foundation models, particularly in the domains of complex text rendering and high-fidelity image editing. Its architectural innovations, data-centric pipeline, and curriculum learning approach yield robust, scalable, and generalizable performance across a wide range of multimodal tasks. The model's strong results in both generation and understanding tasks underscore the potential of unified generative frameworks for the next generation of multimodal AI systems, where perception and creation are seamlessly integrated.


