- The paper introduces a paired testing protocol that quantitatively evaluates batch-induced label flips between safety and capability prompts.
- It shows that output instability is a strong predictor of batch fragility, evidenced by a significant correlation (r=0.909) across models.
- The findings demonstrate that enabling batch-invariant kernels eliminates refusal flips, underscoring the need for precise production stack evaluations.
Paired Protocols for Batch-Conditioned Refusal Robustness: Assessment and Implications
Introduction and Problem Framing
Batch inference is now a fundamental element in the scalable deployment of LLMs, with contemporary serving stacks leveraging batched and continuous-request scheduling, tensor-parallel kernels, and dynamic key-value cache management. Traditional safety evaluations, however, commonly treat deployment batch configuration as a static, background parameter, rather than as a variable with potential bearing on safety boundary behavior. "A Paired Testing Protocol for Batch-Conditioned Refusal Robustness in LLM Serving" (2605.27763) addresses this underexplored facet by formally interrogating whether and how serving batch size or composition can induce measurable shifts in model refusal behavior, particularly on prompts designed to probe the refusal–compliance boundary.
The manuscript synthesizes four artifact-backed empirical studies into a rigorous protocol for evaluating batch-conditioned refusal robustness. It targets the comparative question: do batch-conditioned label changes disproportionately affect safety-relevant prompts compared to general capability prompts, and if so, via what mechanisms and at what operational magnitude? The contributions include both empirical findings and a normative testing recommendation for LLM assessment in production.
Methodological Framework
The work comprises four incrementally staged studies:
- Study A (Local Paired Perturbation): An initial discovery protocol evaluates instruction-tuned small LLMs (1B–3B) on matched safety and capability prompts across controlled variations in batch size and scheduling. Output label flips—refusal to compliance or vice versa—are automatically detected and then manually adjudicated to separate genuine boundary-shift events from superficial output variations.
- Study B (Cross-Model Generalization): Expands the protocol to 15 models spanning diverse alignment types and architectures. The analysis scrutinizes whether fragility to batch perturbation generalizes systematically, and examines the predictive value of alignment type versus generic output instability for batch-sensitive label flips.
- Study C (Composition Under Continuous Batching): Assesses whether co-residence with other requests in continuous-batch schedulers can activate additional safety risks through multi-tenant effects, using temporal overlap and batch composition manipulation.
- Study D (Batch-Invariant Kernel Ablation): Tests the causal contribution of non-invariant backend kernels by re-running candidate boundary-flip prompts on vLLM with a batch-invariant execution path, determining if observed flips depend on batch-sensitive low-level numerics.
Primary Findings
Local Rate and Nature of Batch-Induced Refusal Instability
The local paired perturbation study (Study A) finds that output label flips do occur when serving configuration varies, with safety-labeled prompts changing more frequently than capability prompts (0.51 versus 0.14 in the base sample). However, subsequent manual audit and adjudication reduce the set of true behavioral flips substantially—only 17 out of 63 candidates survive as genuine, implying a corrected operational rate of approximately 0.16.
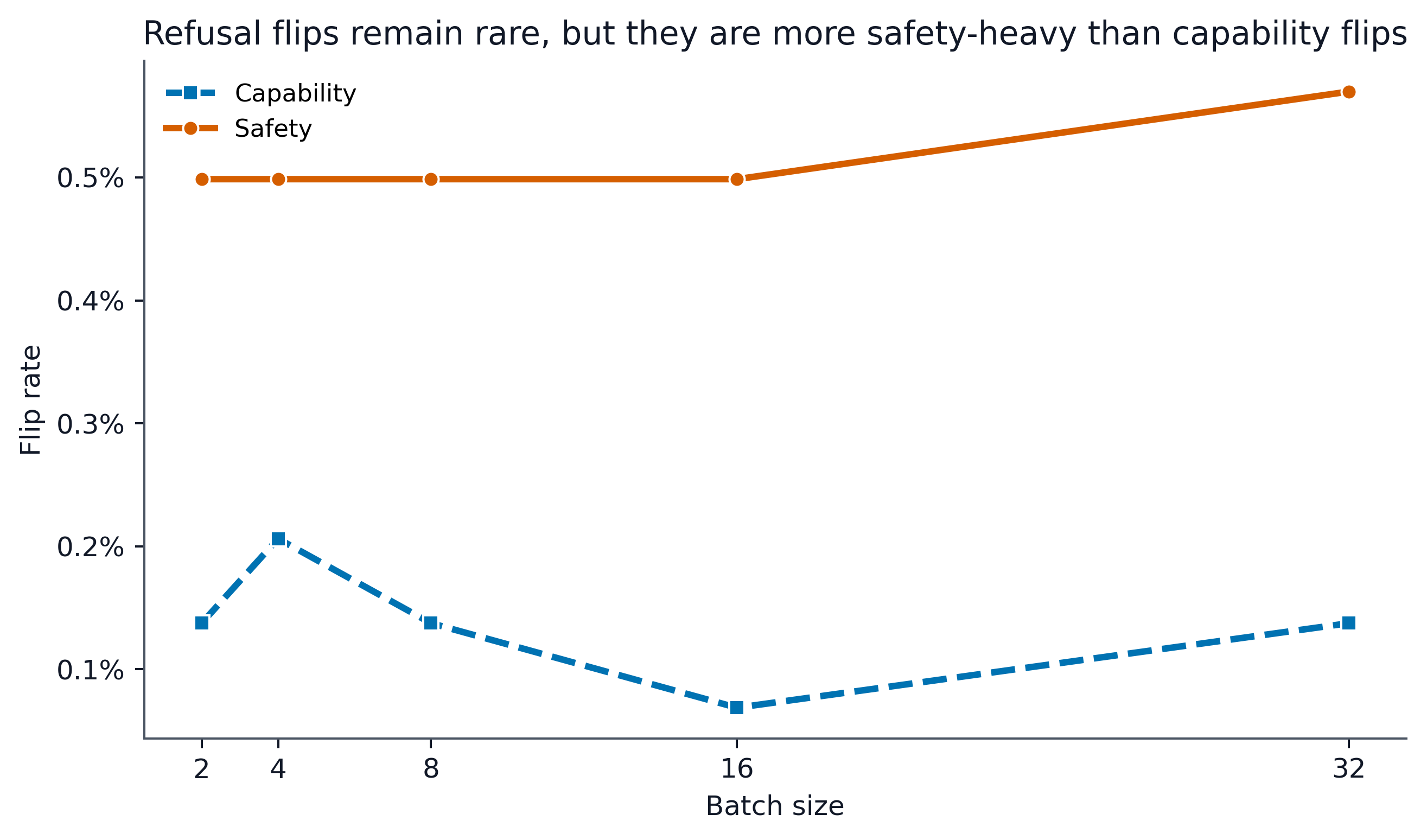
Figure 1: Study A safety versus capability flip rates by batch size. Safety flips exceed capability flips in the local discovery setting, identifying a refusal-boundary signal while leaving the absolute rate low.
This validates the existence of batch-conditioned refusal flips but demonstrates that the vast majority of output variation is benign or not safety-central.
Cross-Model Heterogeneity and Predictors of Batch Fragility
Extending to a broader set of 15 models (Study B), the previously observed safety-over-capability asymmetry does not generalize: the safety-to-capability flip ratio approximates parity, indicating that batch-induced refusal fragility is not a universal property of all models or alignment styles. Critically, analysis via ANOVA finds no statistically detectable association between alignment type and observed flip rates (p=0.942, η2=0.033), and per-group means fall within a narrow band. Instead, the strongest predictor of batch fragility is output instability (correlation r=0.909), underscoring that observable output churn is more diagnostically useful than model categorization.
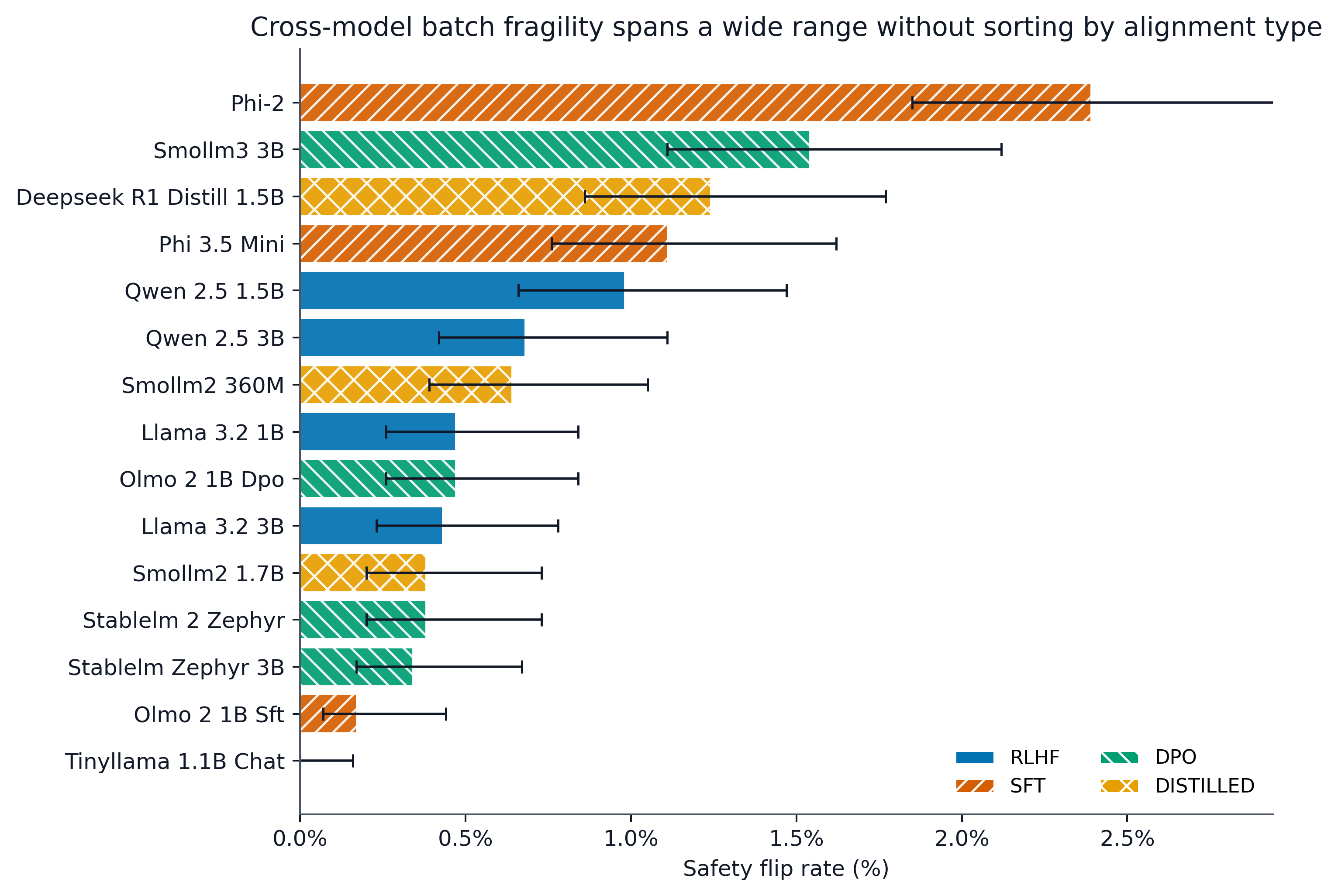
Figure 2: Cross-model fragility ranking from the 15-model extension. Safety flip rates span 0.00 to 2.39, with error bars showing 95% Wilson confidence intervals. High- and low-fragility models appear across multiple alignment categories rather than forming a clean alignment-type ladder.
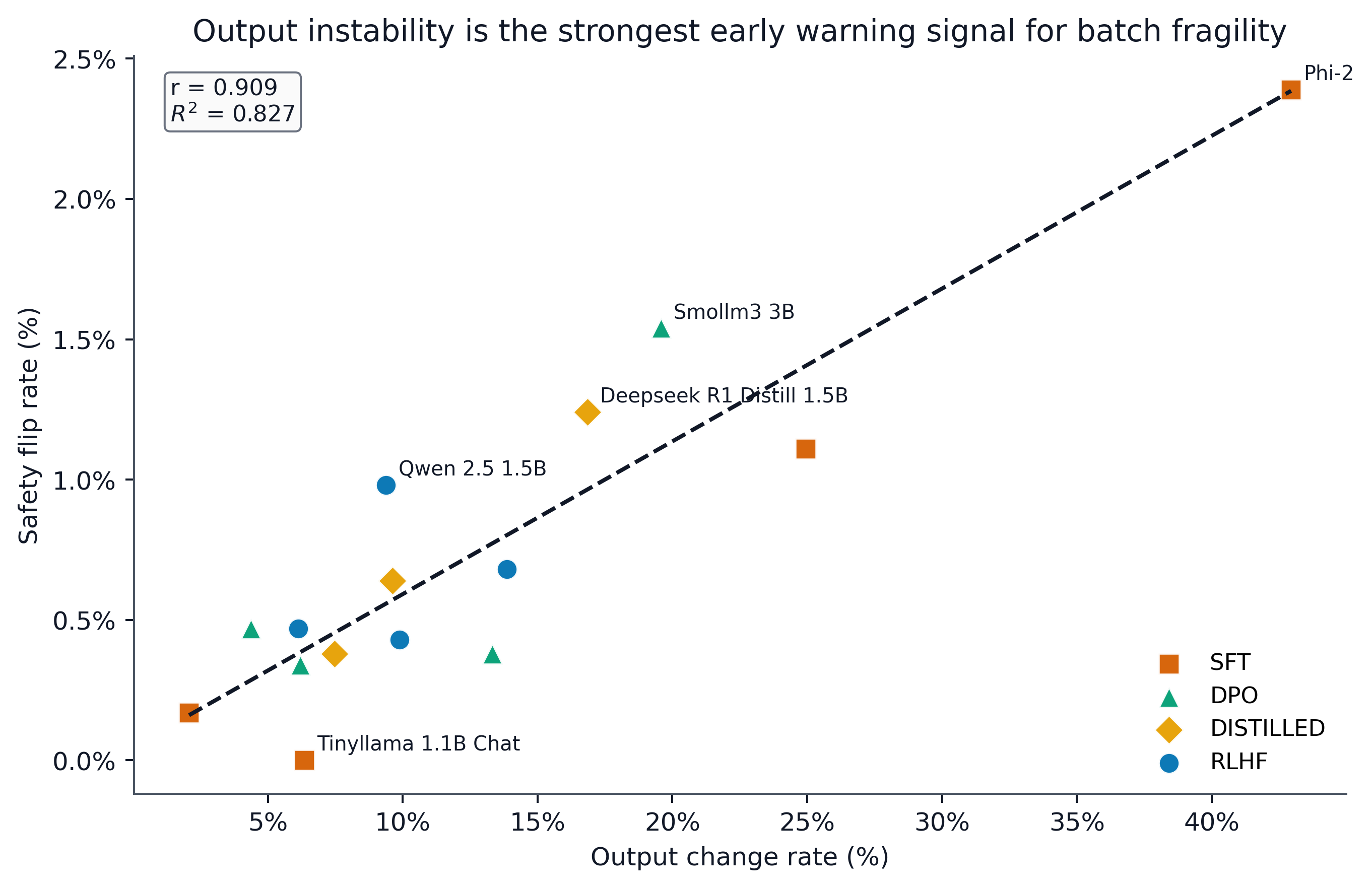
Figure 3: Output instability versus safety fragility across the same 15-model extension. The dashed line is the least-squares linear fit. Models with larger output-change rates under batching also exhibit higher refusal fragility (r=0.909), which makes output instability a more useful screening signal than alignment type.
True-batching versus synchronized-dispatch configurations yield nearly identical patterns, disfavoring a pure artifact explanation linked solely to scheduling or prompt-list order.
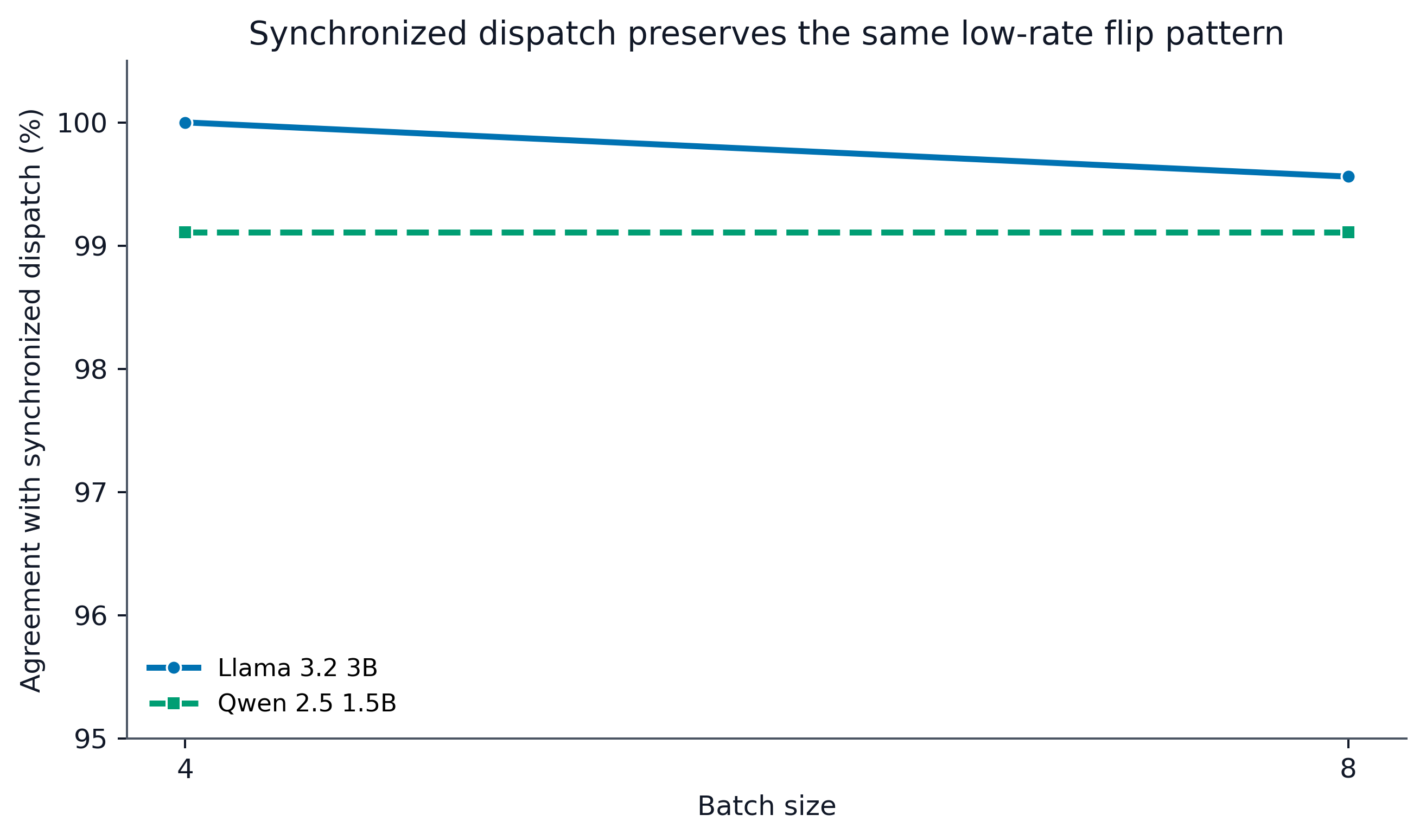
Figure 4: True-batch agreement with synchronized dispatch across model--batch-size conditions. The y-axis is zoomed to 95--100.5% to expose small differences. Near-100% agreement argues against a pure synchronized-dispatch artifact while preserving the low-rate interpretation.
Composition Null and Directional Caveat
In the continuous-batching composition study (Study C), no aggregate multi-tenant effect is detected at a 4.7 percentage-point minimum detectable effect; statistical tests (McNemar, Cochran's Q, Mantel–Haenszel) remain null. Nevertheless, rare label flips that do occur in these settings display a consistent directional bias toward unsafe flips (28/31 in pooled multi-prompt settings), although with a denominator insufficient for operational significance. The composition dimension does not emerge as a dominant practical risk channel under current configurations.
Batch-Invariant Kernels as a Mechanism Control
The kernel ablation (Study D) provides decisive causal evidence: under standard vLLM, 22 out of 55 candidate rows manifest label flips; when re-run with batch-invariant execution enabled (VLLM_BATCH_INVARIANT=1), all flips evaporate. This directly ties observed refusal fragility to underlying kernel-level nondeterminism in batching, rather than model weights or prompt content.
Operational Implications and Recommendations
The various studies collectively justify a narrow but robust doctrine for refusal robustness evaluation in LLM deployment:
- Batch-conditioned flips are real but low-rate and model-specific. The risk is not negligible in critical applications, but batch-induced refusal instability does not broadly dominate variance among outputs.
- Alignment class and vendor family are uninformative predictors of batch fragility; output instability under batching is a more actionable signal for screening models likely to benefit from paired testing.
- Exact-stack validation is required: refusal behavior should be evaluated under the precise batch settings, scheduler, and backend kernels employed in intended production deployments, as small changes in these parameters can surface nontrivial boundary effects.
- Refusal robustness should be assessed using paired safety and capability controls to distinguish safety-specific instability from general output churn.
- Batch-invariant kernel paths provide an effective fix for batch-conditioned flips—where supported by the backend, enabling these paths eliminates the detected flips at the tested scale.
In practical terms, this positions batch-configuration robustness checks as an integral element of LLM safety testing pipelines, secondary only to higher-magnitude deployment effects such as quantization, and suggests that practitioners should treat batch configuration not as invariant infrastructure, but as a modifiable and consequential evaluation parameter.
Limitations and Scope
The findings operate in a rare-event regime with wide confidence intervals and are constructed from an overview of multiple targeted studies with single-reviewer adjudication at key points. The tested models and serving configurations do not include very large-scale LLMs, tensor-parallel serving, or stochastic decoding settings. Furthermore, scoring-stack and scheduler-level heterogeneity mean that the results are more operationally instructive than numerically generalizable; all claims are anchored to the tested vLLM (0.19.1) on H100 hardware.
Theoretical and Practical Significance
From a theoretical perspective, the work substantiates that batch-conditioned behavioral shifts can, in principle, influence model refusal behavior at safety boundaries, but are neither universal nor alignment-family-linked. The strong explanatory power of output instability for batch fragility aligns with emerging literature emphasizing the pertinence of deployment-time output sensitivity for downstream risk assessment.
Practically, the work delineates a lightweight yet robust protocol for batch-robustness evaluation and demonstrates that production safety evaluation must be matched to the actual serving stack. The results further call for broader adoption and extension of batch-invariant kernels and advocate for their inclusion in safety-critical ML deployment pipelines.
Future Directions
Future research should generalize this protocol to larger model scales, tensor-parallel and distributed serving clusters, stochastic decoding regimes, and a broader spectrum of backend frameworks. Automated and multi-reviewer adjudication pipelines will be valuable for refining operational flip-rate estimates. Prospective benchmarks can further clarify the interplay between batching, quantization, and other deployment-time optimizations on LLM refusal robustness and overall trustworthiness.
Conclusion
Batch-induced refusal instability is a measurable, low-rate phenomenon, model- and stack-specific, and mechanistically linked to backend kernel nondeterminism. Model alignment type is not a reliable predictor of batch fragility; output instability is the key screening variable. Refusal robustness assessment should be conducted on the precise production stack using paired safety/capability controls and, where possible, batch-invariant kernels. Batching is not a dominant threat to safety in its own right, but warrants explicit evaluation in LLM deployment due to its capacity to trigger, albeit infrequently, nontrivial safety boundary shifts (2605.27763).

