- The paper introduces a critic-free policy optimization method that assigns local credit using high-entropy summary anchors in multi-round retrieval interactions.
- It employs counterfactual branching to evaluate reasoning-to-summary influence and residual stability, ensuring precise credit propagation.
- Empirical results on BRIGHT and BEIR benchmarks show RICE-PO outperforms prompt-based agents and RL baselines in reasoning-intensive tasks.
RICE-PO: Converting Retrieval Interactions to Local Credit Signals for Reasoning Agents
Recent advances in information retrieval are trending toward interactive reasoning agents that iteratively reformulate queries and leverage multiple rounds of evidence retrieval. Instead of single-shot matching, a reasoning agent must reason over retrieved documents, identify information gaps, and refine its query, resulting in a complex agent-environment interaction trajectory. This paradigm introduces a critical credit assignment challenge: executable actions (queries/summaries) are observable and evaluable by retrieval metrics, while latent reasoning steps are not directly measurable and may only influence outcomes through later actions. Naïve outcome-level reward assignment is insufficient; attributing final rewards to all prior steps can misassign credit due to the indirect and variable influence of intermediate reasoning decisions.
RICE-PO Framework: Critic-Free Local Credit Assignment
RICE-PO addresses retrieval interaction credit assignment using a critic-free policy optimization framework grounded in three branch diagnostics: policy uncertainty, reasoning-to-summary influence, and residual stability. The agent generates latent reasoning spans and executable summaries over multiple retrieval rounds, leveraging high-entropy summary anchors as critical decision points for local credit estimation.
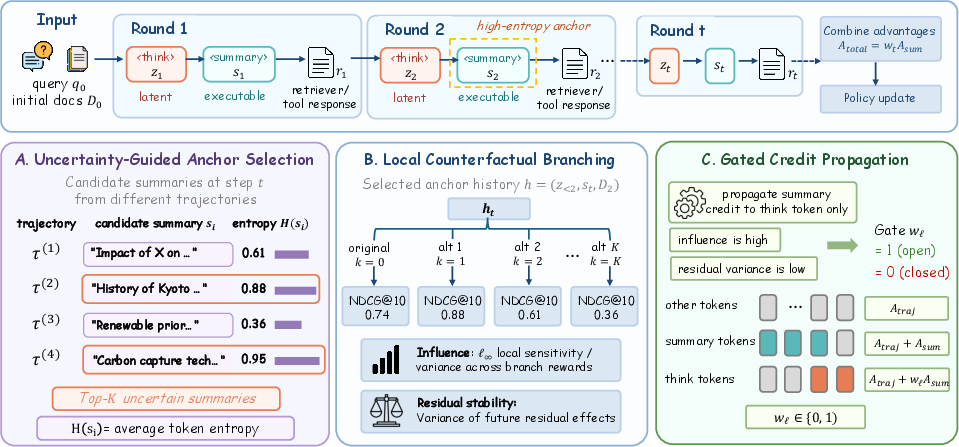
Figure 1: RICE-PO overview—multi-step agent interaction, anchor selection by uncertainty, local branch diagnostics, and gated credit propagation mechanisms.
Anchor Selection via Policy Entropy
High-entropy summaries are more likely to encapsulate ambiguous, pivotal decision points. RICE-PO pools summary actions across trajectories and selects top-K anchors with elevated token entropy, focusing local credit analysis on segments where the policy is most uncertain and where alternative continuations may lead to substantively different outcomes.
Counterfactual Branching: Influence and Residual Effect
For each anchor, RICE-PO estimates reasoning-to-summary influence by branching at the reasoning span and observing the variance in retrieval rewards across alternative summaries. Residual stability is measured by propagating each branch to terminal retrieval and comparing final rewards against intermediate summary rewards. If downstream steps consistently preserve or amplify local reward differences, the summary’s feedback is deemed reliable for backward credit propagation.
Gated Credit Propagation
Credit is assigned to reasoning spans only if:
- Reasoning-to-summary influence is strong (significant variance in immediate summary rewards across counterfactuals),
- Residual effect is stable (low variance in difference between final and intermediate rewards across branches),
This dual gating prevents propagation of spurious or overridden signals from poorly attributable decision points.
Policy Optimization
Token-level advantage is synthesized from three credit sources:
- Trajectory-level advantage (final reward, broadcast to all tokens),
- Summary-level advantage (local retrieval metrics for high-entropy summaries),
- Reasoning-level advantage (gated backward propagation from summary anchors to paired reasoning tokens),
The final PPO-style objective clips token ratios and applies KL regularization, optimizing policy without learned critics or process reward models.
Experimental Results and Empirical Analysis
RICE-PO is evaluated on BRIGHT (reasoning-intensive retrieval across domains) and BEIR (general retrieval) benchmarks, outperforming prompt-based agents and group-based RL baselines under identical retriever settings.
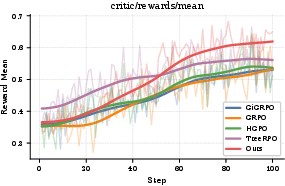
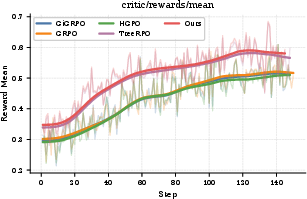
Figure 2: BRIGHT performance—RICE-PO surpasses alternative approaches in NDCG@10 across all task categories.
Ablation Studies
RICE-PO’s branch diagnostics are individually validated: ablations demonstrate that neither always propagating local summary credit nor outcome-level reward alone provides robust credit assignment. The combination of uncertainty-triggered gating and simultaneous influence/effect diagnostics consistently improves performance, especially in reasoning-intensive tasks. Entropy-based anchor selection further outperforms random selection, providing broad task-level gains.
Practical and Theoretical Implications
RICE-PO demonstrates that retrieval interaction structure itself can provide actionable supervision for training reasoning-based agents, obviating the need for learned critics or external judges. The method generalizes across different retriever architectures and backbone sizes, showing especially large gains for smaller LLMs where credit assignment is more critical due to limited parameter capacity. From a theoretical perspective, RICE-PO aligns with reinforcement learning principles by refining advantage estimation to latent actions, improving sample efficiency and policy reliability in complex multi-turn settings.
Future Directions
RICE-PO’s methodology, grounded in interaction-derived signals and critic-free optimization, opens avenues for:
- Integration with adaptive retriever modules,
- Scaling to larger LLM backbones,
- Designing more efficient influence and stability estimators,
The framework could generalize to other multi-step agentic systems beyond retrieval, including tool-augmented language agents and long-horizon decision processes.
Conclusion
RICE-PO advances credit assignment for reasoning-based retrieval agents by leveraging observable retrieval signals and gating backward propagation through rigorous branch diagnostics. The approach delivers consistent performance improvements in both reasoning-intensive and general retrieval settings, and its critic-free paradigm aligns learning with the intrinsic structure of agent-environment interaction. These results highlight the ongoing importance of aligning reinforcement learning methods to the unique characteristics of language-agent systems, paving the way for more effective reasoning and decision-making in AI-powered retrieval.