- The paper introduces SPEAR, which dynamically executes analysis code to optimize prompt engineering and address structural error patterns.
- It employs a flexible agentic loop with tools like evaluate, python, set_prompt, and finish, safeguarded by auto-rollback and guard-metric floors.
- Empirical results show rapid convergence and substantial performance improvements on both industrial judge tasks and public benchmarks.
Authoritative Summary of "SPEAR: Code-Augmented Agentic Prompt Optimization" (2605.26275)
Motivation and Positioning
The paper introduces SPEAR, a code-augmented agentic optimizer for Automatic Prompt Engineering (APE), addressing limitations of prior fixed-pipeline approaches (e.g., OPRO [yang2024opro], EvoPrompt [guo2024evoprompt], TextGrad [yuksekgonul2024textgrad], GEPA [agrawal2025gepa]). In existing models, the optimizer follows a predetermined error-analysis and rewrite pattern, constrained to static strategies that fail to capture structural error clusters such as confused class pairs or label-rule contradictions in the evaluation data. SPEAR adopts the code-as-action paradigm from CodeAct [wang2024codeact], enabling the optimizer itself to dynamically write and execute analysis code over its evaluation DataFrame.
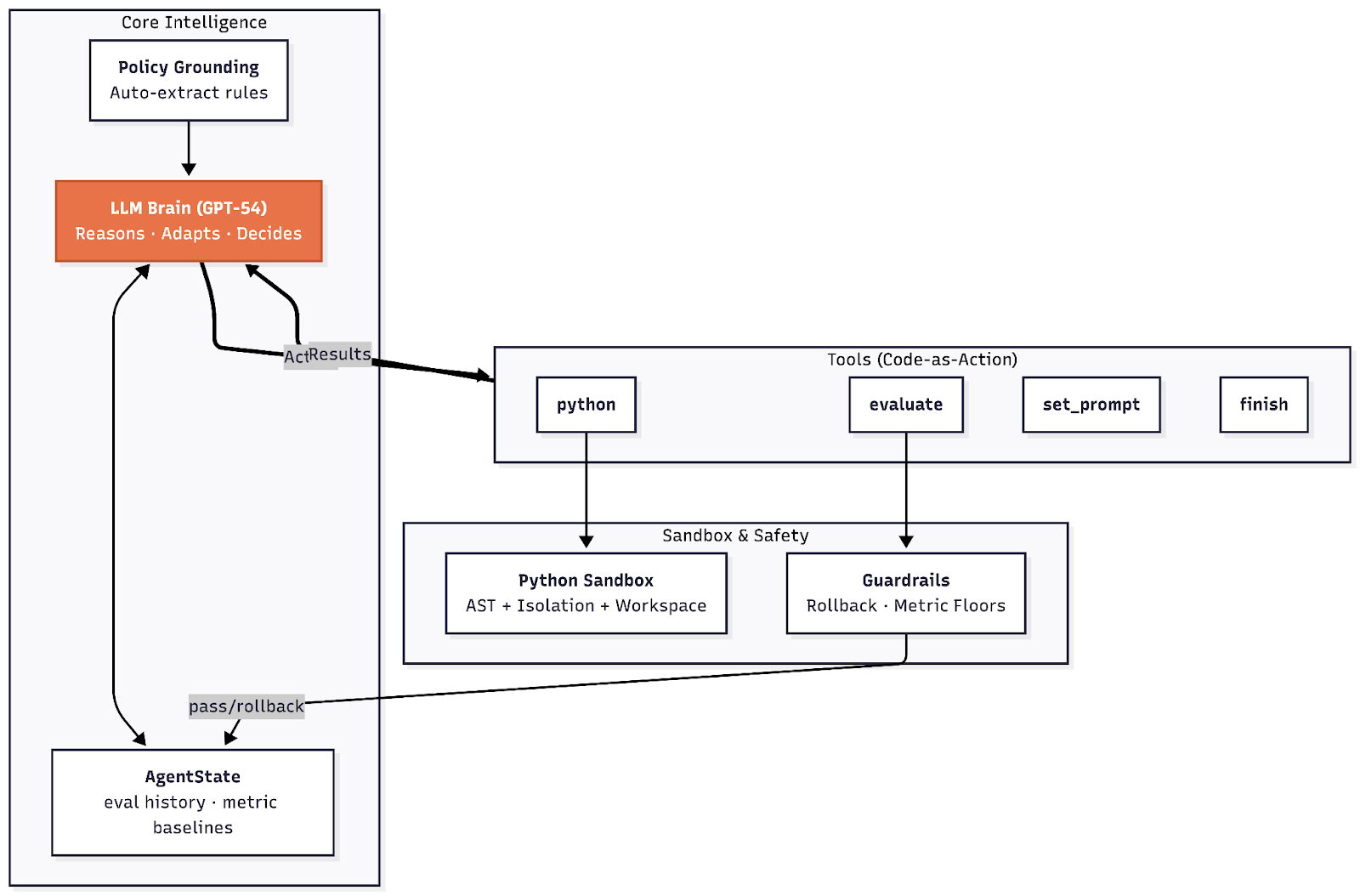
Figure 1: SPEAR architecture—a GPT-5.4 agent brain with four tools (evaluate, python, set_prompt, finish), guarded by auto-rollback and guard-metric floor for monotone improvement.
Algorithmic Design
SPEAR's agentic loop exposes four tools: evaluate (scoring prompts on subsets or full splits), python (arbitrary code execution in an AST-restricted sandbox), set_prompt (prompt modification), and finish (termination). Tool outputs update the agent state, which tracks evaluation history and performance baselines, monitored via two guardrails:
- Auto-rollback: Reverts prompt rewrites when the primary metric regresses below the best-seen value.
- Guard-metric floor: Optionally enforces a secondary metric threshold.
The agent is not restricted to any fixed evaluate-analyze-rewrite ordering, granting orchestration autonomy. The Python sandbox supports detailed structural analyses (e.g., confusion matrices, error clustering, per-group metrics) inaccessible through textual-only reflection. The workflow is defined in detail in the agent system prompt, which prescribes thorough error analysis, prompt drafting via LLM calls, and concept-level rule definition.
Experimental Evaluation
Benchmarks span three industrial LLM-as-judge datasets (Hiring Assistant, CMA, Facet Suggestion—totaling 13 judge tasks) and public datasets (BBH-7, GSM8K). Task models use GPT-4o; optimizers run GPT-5.4 except for TextGrad's reflection engine (GPT-4o due to system constraints).
On industrial tasks, SPEAR demonstrates optimal performance across 11 of 12 directly comparable tasks (excluding a train-only row), with κ and F1-macro absolute gaps up to 0.76 versus baselines (GEPA, TextGrad). On BBH-7, SPEAR achieves 0.938 mean accuracy, outperforming GEPA (0.628) and TextGrad (0.484); on GSM8K, all methods tie near 0.96 accuracy.
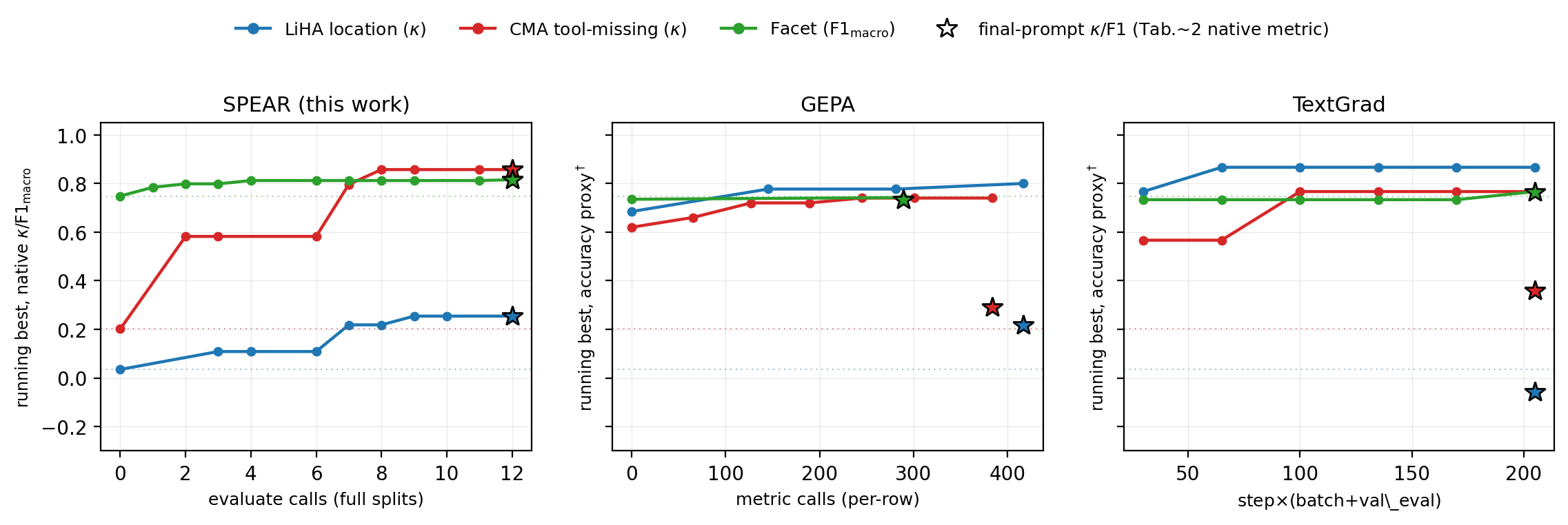
Figure 2: Per-method convergence on three industrial tasks—SPEAR converges rapidly to high native-metric scores, with gaps in optimization-internal scores for GEPA/TextGrad.
Case studies illustrate SPEAR's capability to autonomously discover and address structural errors:
- Hiring Assistant (job location): The SPEAR agent leverages python tool for clustering failure modes and reveals a dataset label-rule contradiction, prompting a rule-level rewrite that achieves κ=0.76 (seed 0.035; ceiling 0.74).
- CMA (tool-missing): SPEAR constructs confusion matrices to identify and resolve class-pair misclassifications via targeted rewrites (seed κ=0.20 to κ=0.95+).
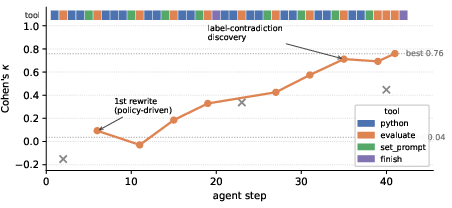
Figure 3: SPEAR agent trace for Hiring Assistant job location—tool sequence (python, evaluate, set_prompt), κ trajectory, and the label-contradiction-driven prompt rewrite.
Ablation and Component Analyses
Extensive ablation studies isolate component contributions:
- Python tool removal: Largest degradation (−0.35κ Hiring Assistant location, −0.79κ CMA tool-missing), directly linking the analytic affordance to performance lift.
- Orchestration autonomy: Replacing the agent with a rigid loop (same tools, fixed order) incurs substantial metric loss (e.g., −0.27κ Hiring Assistant location).
- Model quality: Downgrading the agent from GPT-5.4 to GPT-4o results in near-total failure on complex tasks.
- Auto-rollback and guard-metric floor: Do not improve mean performance but reliably prevent runs terminating below seed (across 78 runs).
Cost analysis indicates SPEAR converges in $2$–$3$ full evals (compared to κ=0.760500 for GEPA) while maintaining cost parity (within κ=0.761) when including all sandbox LLM calls.
Architectural Implications
The primary architectural advance is SPEAR's coupling of agentic autonomy, active code execution, and monotone improvement guardrails. SPEAR is the first APE optimizer with active code analysis over structured evaluation output. Prior work in code-as-action (ReAct [yao2023react], Reflexion [shinn2023reflexion], ADAS [hu2024adas]) achieves free-form reasoning, but in non-APE domains. Prior APE systems (e.g., OPTO/Trace [cheng2024opto]) treat execution traces as passive feedback, lacking active analysis.
Theoretical and Practical Implications
By enabling the optimizer to autonomously group and analyze errors, SPEAR achieves rapid and robust improvements on tasks where error structure is non-trivial and text-only critique fails (multi-class confusion, label contradictions). Its architecture scales to industrial judge tasks, and the performance evidence indicates best-in-class optimization on such benchmarks. For tasks where output format mismatches dominate (some BBH-7 dimensions), SPEAR's advantage reflects its ability to rapidly rewrite output contracts, not deeper reasoning.
Practical impact includes reduction in convergence iterations, reliability of improvement, and empirical robustness across held-out splits and transfer to new task models. The Python tool is load-bearing for complex tasks, and SPEAR's flexible workflow makes it a plausible generalization for production APE deployments.
Limitations and Reproducibility
The optimizer model (GPT-5.4) is an internal deployment not publicly released; partial reproducibility is provided via released harness, prompts, and public benchmark data. Prompts for proprietary industrial tasks cannot be released, constituting a reproducibility gap. The threat model is cooperative; sandbox security is not adversarial-grade. Small-κ=0.762 dev sets may induce metric variance.
Speculation on Future Developments
The SPEAR paradigm suggests broader adoption of agentic, code-augmented APE in domains requiring high-fidelity prompt optimization, especially where error structure eludes simple textual feedback. Future work may extend SPEAR's workflow to meta-optimization (optimizing optimizers), integrate adversarial sandboxing, and pursue cross-task transfer learning of prompt engineering strategies.
Conclusion
SPEAR leverages code-as-action in an agentic loop to outperform fixed-pipeline APE optimizers, with substantial performance gains on structurally complex judge tasks and competitive results on format-divergent public benchmarks. The active Python tool is uniquely load-bearing, and orchestration autonomy is empirically critical. The methodology is theoretically significant for automatic prompt engineering, and practically robust for industrial deployment scenarios.

