- The paper demonstrates that regulating latent feature statistics via DyFN reduces scale–shift drift in streaming monocular video, thereby stabilizing 3D geometry.
- The method employs a causal ConvGRU-based module that fine-tunes with only 2% additional parameters, ensuring efficient per-frame geometric consistency.
- Experiments on indoor and outdoor datasets show significant gains, including an 11.9% accuracy boost on ScanNet and robust long-sequence depth estimation.
Stabilizing Streaming Video Geometry via Dynamic Feature Normalization
Motivation and Problem Analysis
Monocular 3D geometry estimation from video is essential for robotics, autonomous driving, and large-scale scene reconstruction, but the application of high-performing single-image Monocular Geometry Estimation (MGE) models to streaming video suffers from severe temporal inconsistency, most prominently manifesting as scale–shift drift between frames. Structural instability resulting from such drift leads to non-rigid warping, layering breaks, and jitter in continuous 3D reconstructions, undermining the suitability of state-of-the-art monocular models for dynamic, real-world deployment.
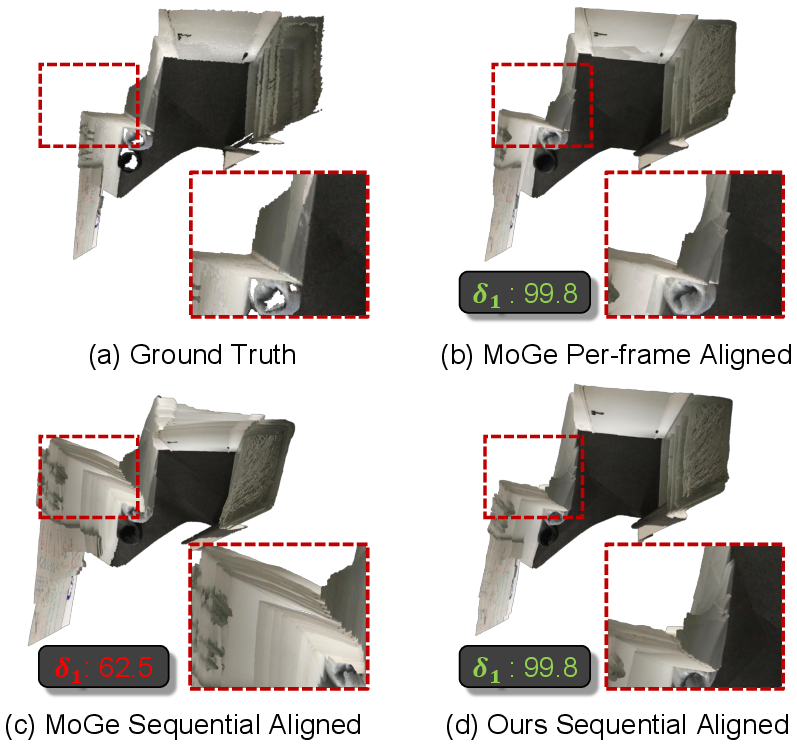
Figure 1: Comparison of per-frame versus sequence-aligned depth in multi-frame fused reconstructions, illustrating catastrophic geometry collapse when a single sequence-wide scale/shift is applied, compared to geometric accuracy with per-frame alignment (δ1 threshold).
While prior works have proposed temporal attention and recurrent memory for video depth stabilization, these strategies require full-network finetuning and large-scale video data, often sacrificing zero-shot generalization and per-frame accuracy. The core hypothesis of this paper is that temporal inconsistency and scale–shift drift arise not fundamentally from geometric deficiencies, but from fluctuations in the mean and variance of latent encoder features—statistics that can be regulated without modifying the backbone, provided an appropriate stabilization mechanism.
Empirical Characterization of Temporal Drift
The study leverages the MoGe monocular model to empirically decouple latent feature statistics from geometric prediction. It is observed that the scale and shift of the depth output are tightly controlled by per-frame feature mean and variance. Artificially modulating these statistics (modifying α,β multipliers) induces large scale/shift changes in the predicted depth, while the relative reconstruction accuracy remains essentially constant post-affine alignment.
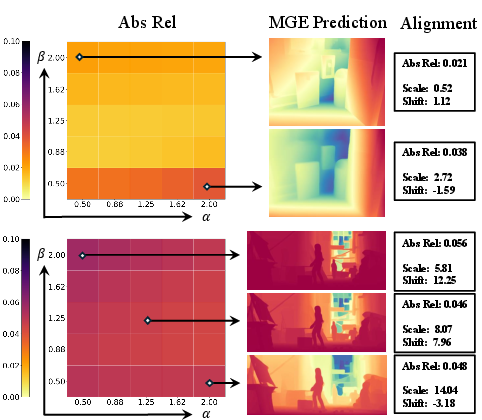
Figure 2: Modulation of latent feature statistics and its effect on output scale/shift (left: AbsRel error, right: qualitative and quantitative results across sampled parameters), indicating geometric stability despite major scale–shift perturbations.
This evidence shows that state-of-the-art MGE backbones are geometrically robust and that scale–shift instability is the direct consequence of unregulated per-frame feature statistics, not model capacity or training set limitations.
Dynamic Feature Normalization (DyFN) Approach
Motivated by this analysis, the Dynamic Feature Normalization (DyFN) module is introduced as a lightweight, causal recurrent mechanism that regulates the feature statistics over time. DyFN operates as an intermediate module between the (frozen) encoder and decoder of a monocular model, dynamically predicting the required mean and variance for each frame based on historical temporal context.
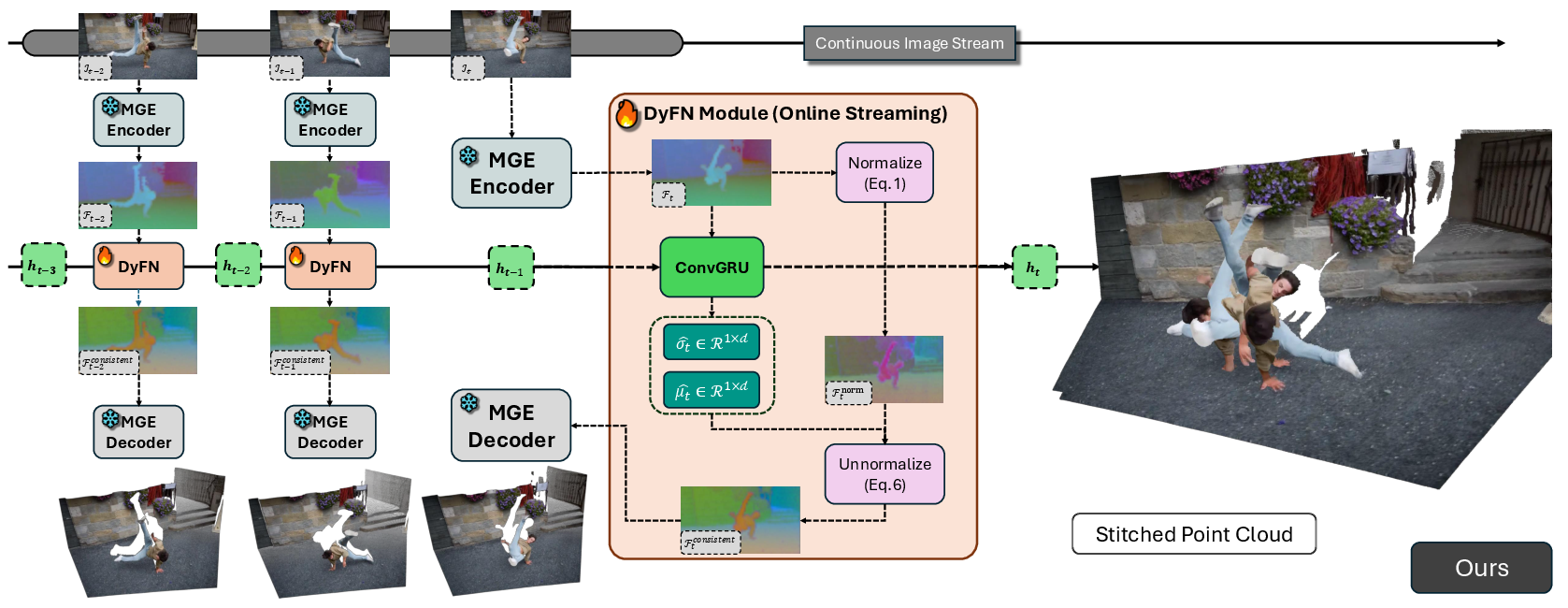
Figure 3: High-level system pipeline: consistent geometry estimation is achieved by a shared encoder, the recurrent DyFN (with ConvGRU), and a frozen decoder, yielding stabilized per-frame features for the 3D reconstruction pipeline.
The DyFN employs a ConvGRU that aggregates observations across frames. At each timestep, the ConvGRU summarizes prior context and predicts spatially-varying statistics—replacing the per-frame statistics with temporally smoothed ones. This stabilizes the scale and shift of the depth predictions over time, substantially reducing structural drift. Notably, DyFN can be finetuned with only 2% additional parameters, with the backbone frozen, efficiently adapting pretrained MGE models for streaming applications.
Quantitative and Qualitative Evaluation
Extensive benchmarks on diverse datasets—for both indoor (ScanNet, Bonn), outdoor (KITTI), and in-the-wild scenes (Sintel)—demonstrate that DyFN achieves state-of-the-art performance in streaming video depth estimation. Under the strict sequence-wide global alignment protocol, DyFN yields large improvements in δ1 accuracy and Absolute Relative Error over both static monocular and video-specific architectures.
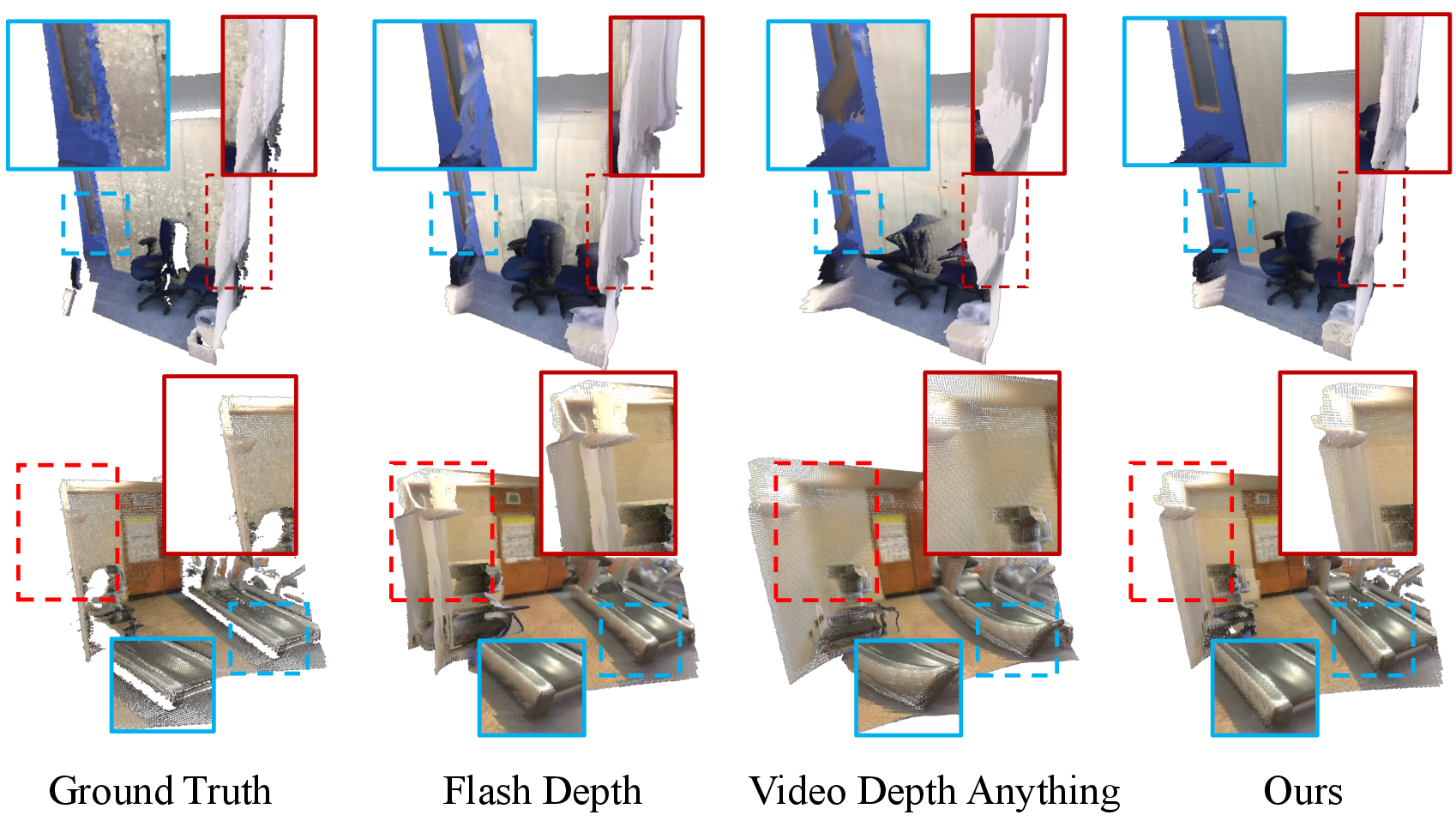
Figure 4: Qualitative comparison across indoor sequences, highlighting minimized non-rigid warping and superior geometric consistency versus FlashDepth and VDA baselines.
DyFN sets notable improvements over prior works, including a +11.9% increase in accuracy (δ<1.25 on ScanNet) over MoGe-v1, and consistently surpassing heavier non-causal video baselines. Crucially, per-frame single-image accuracy is perfectly preserved—DyFN achieves identical results to the backbone under per-frame alignment evaluation, unlike other temporal adaptation methods.
Robustness under long sequences (500 frames) is also established: DyFN uniquely maintains high accuracy and minimal error drift, compared to substantial degradation observed with previous recurrent or sliding window approaches.
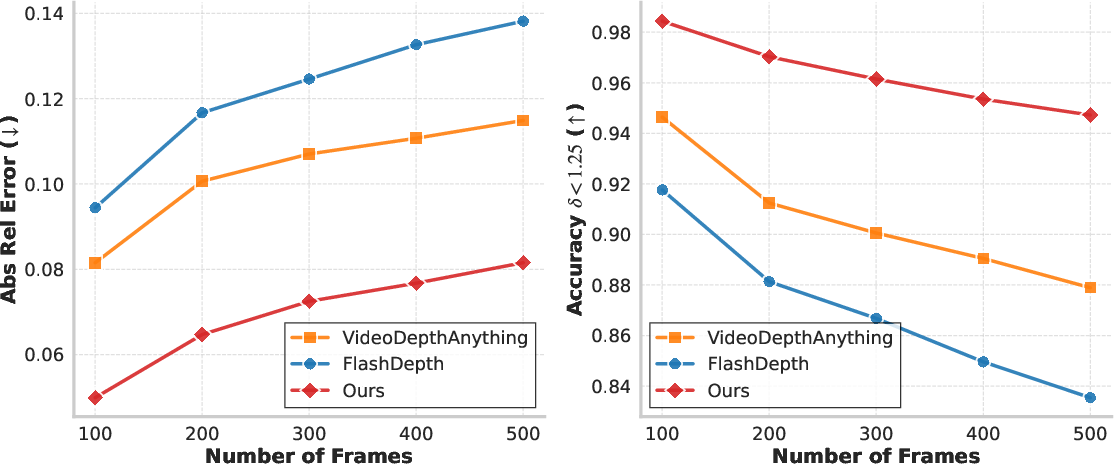
Figure 5: Analysis of long-sequence robustness: DyFN exhibits minimal decay in both AbsRel error and accuracy at increasing sequence lengths—outperforming FlashDepth and VDA as frame interval grows.

Figure 6: Visual reconstructions in diverse, challenging environments; DyFN delivers stable and reliable 3D structure over long continuous streams and dynamic content.
Ablation and Module Architecture
Ablation confirms the significance of each component: the DyFN module itself, the global sequence alignment loss, and the use of ConvGRU over vanilla RNNs or other normalization strategies. The method achieves peak efficiency—requiring only a single ConvGRU recurrent update and two 1×1 convolutional heads—supporting practical deployment at large scale.
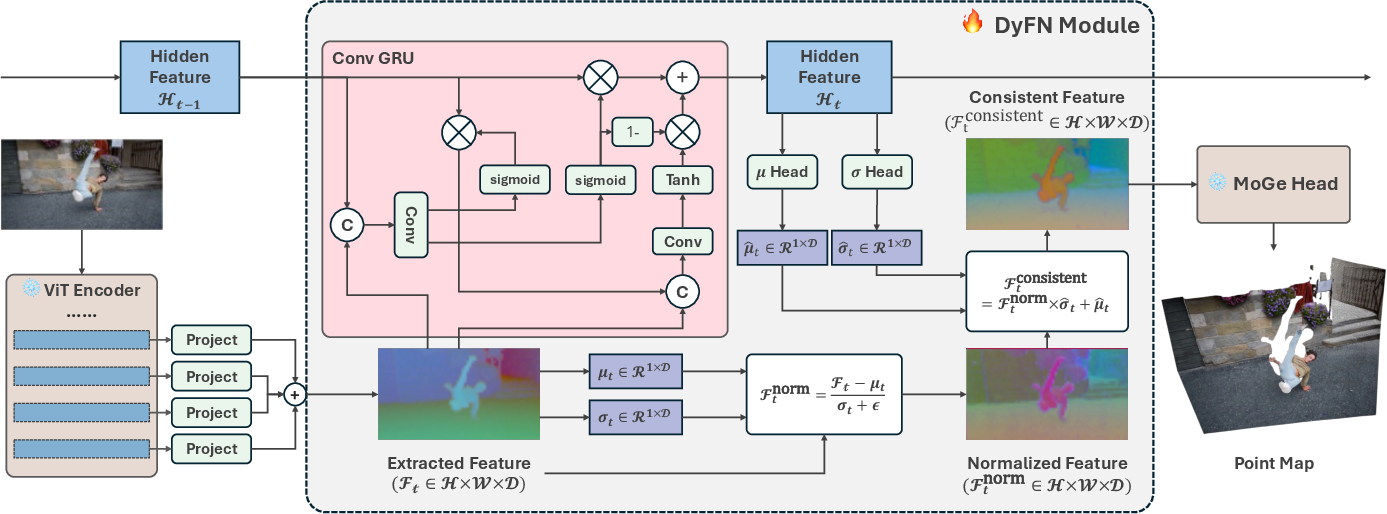
Figure 7: The ConvGRU-based DyFN architecture, integrating feature normalization with recurrent temporal summarization.
Implications and Future Directions
This work establishes that latent feature statistic normalization, applied causally in the temporal domain, is sufficient to render modern, frozen monocular geometry models temporally consistent for streaming input, without any loss in single-frame generalization. In effect, it dissociates the need for full-network retraining or heavy temporal architectures from the stabilization problem, providing a route to cost-effective, adaptive streaming 3D perception in dynamic and resource-constrained settings.
Potential future research directions include integrating multi-frame geometric cues within DyFN to further surpass the per-frame bounds of the backbone, combining with multi-scale and attention-based mechanisms for enhanced spatial-temporal reasoning, and extending the approach to other sequential dense prediction tasks such as optical flow, normal estimation, or generative video modeling.
Conclusion
By precisely characterizing the cause of temporal inconsistency in monocular video geometry—frame-to-frame drift in latent statistics—and introducing the causal DyFN normalization module, this work enables efficient, plug-and-play streaming adaptation of leveraged monocular models. The strong empirical results, minimal computational overhead, and theoretical implications for other sequence modeling domains underscore the broader utility and impact of this approach for 3D perception research and deployment.
Reference: ["Stabilizing Streaming Video Geometry via Dynamic Feature Normalization" (2605.25308)]

