- The paper introduces a depth-guided multi-scale fusion to combine RGB and depth cues for robust 3D human mesh reconstruction.
- It employs the D-MAPS module to enforce metric consistency via bone-length calibration and a MoDAR module for motion-depth alignment.
- Experimental results demonstrate state-of-the-art spatial and temporal accuracy on datasets like 3DPW and Human3.6M, enhancing resilience to occlusions.
Depth-Guided Metric-Aware Temporal Consistency for Monocular Video Human Mesh Recovery
Introduction
Monocular video-based 3D human mesh recovery is inherently ambiguous due to depth ordering and metric scale uncertainties. While prior approaches predominantly utilize RGB visual cues and temporal smoothing for temporal coherence, these methods are intrinsically limited by their inability to robustly solve depth-related ambiguities such as scale drift, depth ordering errors, and instability under occlusion. The proposed framework in "Depth-Guided Metric-Aware Temporal Consistency for Monocular Video Human Mesh Recovery" (2602.04257) introduces a rigorous depth-guided paradigm for addressing these challenges, leveraging recent advances in monocular depth estimation to provide geometric priors that enhance metric fidelity and temporal stability.

Figure 1: Overview of the architecture for depth-guided monocular human mesh recovery, highlighting the integration of RGB, depth-guided multi-scale fusion, D-MAPS, and MoDAR modules.
Methodology
Depth-Guided Multi-Scale Fusion
The approach begins with joint extraction of RGB and depth features from video frames using ResNet-50 and Depth Anything v2 (DAv2). Instead of direct depth value utilization—which is susceptible to noise and calibration artifacts—the framework employs deep feature activations from DAv2. The multi-scale feature fusion mechanism integrates these geometric representations with RGB features via a confidence-aware gating and masking strategy, ensuring the network emphasizes high-confidence, foreground-pertinent cues. The fusion incorporates adaptive gating vectors to dynamically balance the contributions of appearance and depth cues, mitigating adverse effects from unreliable depth predictions.
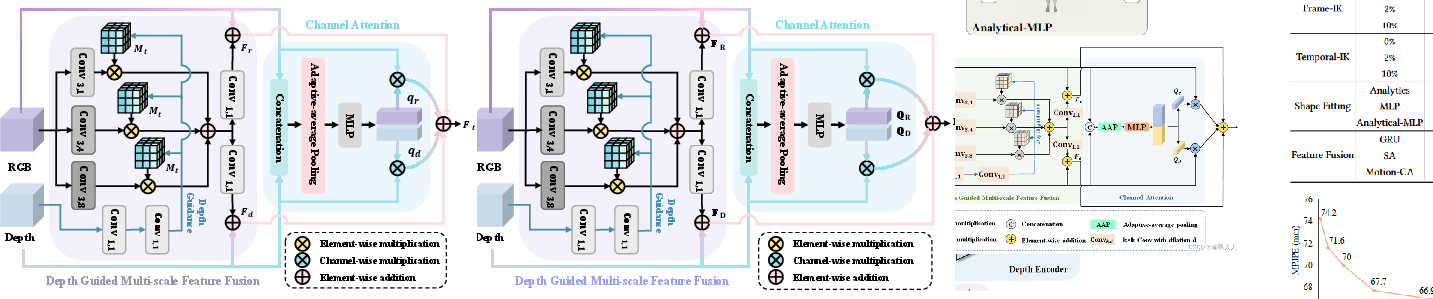
Figure 2: Depth-Guided Multi-Scale Fusion module, showing adaptive integration of depth and RGB features via quality-aware gating.
D-MAPS: Metric-Aware Pose and Shape Initialization
The core of metric consistency is established through the D-MAPS (Depth-guided Metric-Aware Pose and Shape) module. D-MAPS initializes human mesh parameters by enforcing bone-length priors calibrated by depth statistics. Specifically, the system decomposes pose estimation into analytically determined swing and learned twist components. Bone lengths are calculated using temporal confidence-weighted statistics over depth features, ensuring scale-consistent mesh reconstructions across frames. D-MAPS further incorporates root-centered, scale-normalized joint sequences derived from a 2D-to-3D lifting network (DSTformer) to provide a robust skeleton representation for subsequent temporal processing.
MoDAR: Motion-Depth Aligned Refinement
Although D-MAPS establishes a metric-consistent foundation, residual temporal artifacts and errors due to occlusions are addressed by the MoDAR module. MoDAR employs cross-modal attention between motion (skeleton trajectory tokens) and fused features, enforcing bidirectional flow of geometric and dynamical information. The output is refined pose and shape parameters that benefit from both geometric context and tempered motion smoothness. To prevent oversmoothing and loss of transient motion, MoDAR applies a residual causal filter, modulating the update magnitudes according to learned attention-derived gates.
Experimental Results
Comprehensive evaluations were conducted on 3DPW, Human3.6M, and MPI-INF-3DHP, following established protocols and metrics (MPJPE, PA-MPJPE, MPVPE, and Accel). The framework achieves state-of-the-art accuracy in both spatial and temporal domains, specifically:
Ablation studies reveal that both D-MAPS and MoDAR are crucial; individually, they offer partial improvements, but together yield superior accuracy and stability. Notably, mask-guided fusion and quality-aware depth estimation also contribute significant performance gains, demonstrating the importance of robust multi-modal integration.
Impact of Temporal Context
Sequence length analysis highlights the utility of leveraging extended temporal information: as the input sequence increases, both MPJPE and Accel decrease monotonically, implying that richer context aids in resolving ambiguous motions and enforcing consistency.
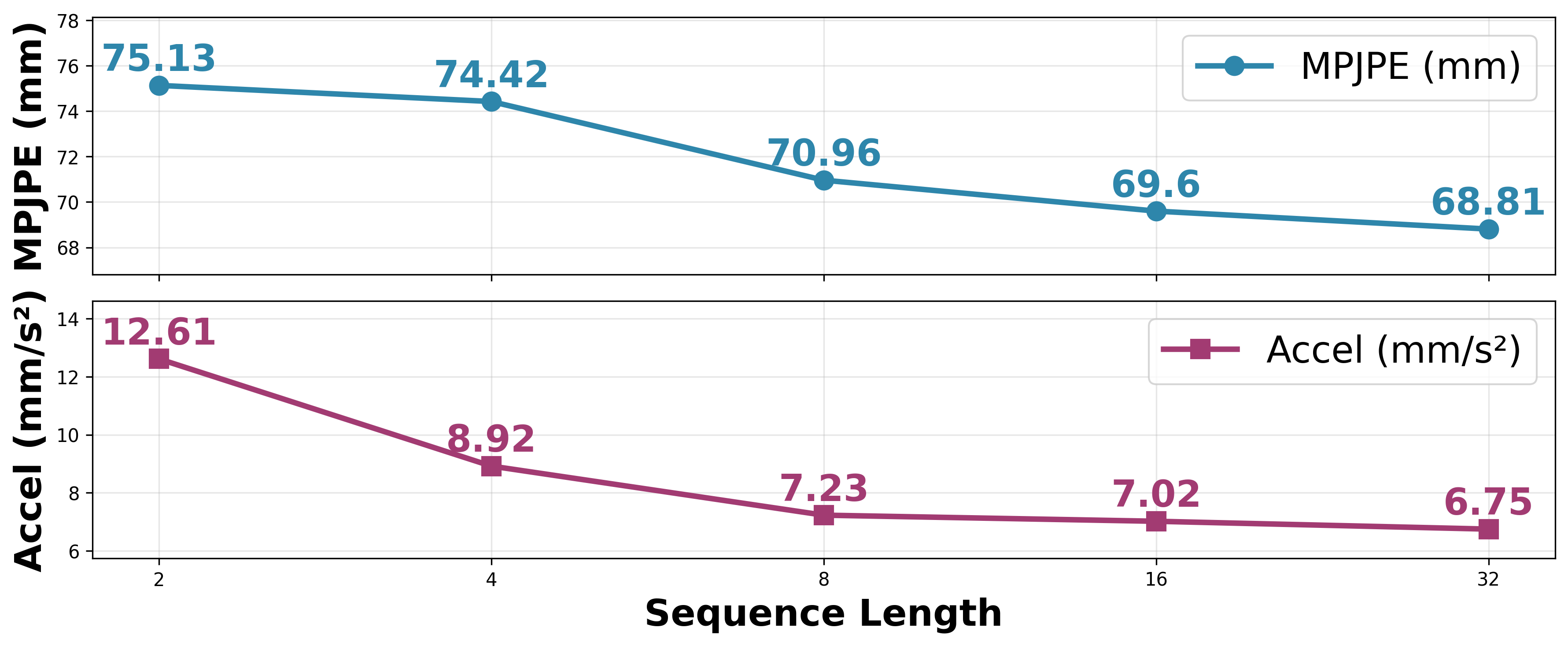
Figure 4: D-MAPS benefits from longer sequence input, exhibiting improved accuracy and stability with richer temporal context.
Implications and Future Directions
The integration of robust monocular depth priors into the human mesh recovery pipeline marks a shift toward metric-aware, temporally stable 3D understanding in monocular video. By enforcing geometric constraints early and aligning dynamic updates with depth-aware representations, this approach transcends the limitations of appearance-centric video pipelines. The implications extend to downstream applications requiring reliable metric scale and temporal fidelity—e.g., animation, VR/AR, and medical motion analysis—where scale drift and temporal jitter currently impede deployment.
Theoretically, this work accentuates the value of cross-modal fusion and geometric regularization, suggesting that future research may further benefit from stronger synergies between self-supervised depth models, articulated motion priors, and 3D mesh optimization. Possible extensions include adaptive spatiotemporal fusion with scene context awareness, self-supervised domain adaptation leveraging synthetic depth, and explicit occlusion reasoning modules to further enhance robustness.
Conclusion
This framework delivers a technically rigorous solution to the longstanding problem of metric and temporal inconsistencies in monocular video-based human mesh recovery. By explicitly integrating depth-derived geometric cues through multi-scale fusion, metric-aware bone calibration, and motion-depth aligned refinement, the approach achieves strong improvements in accuracy, temporal coherence, and robustness—laying a foundational methodology for future research in human-centric video understanding.
