- The paper reveals that a dominant latent factor tied to model size influences AI leaderboard rankings despite significant benchmark-specific noise.
- The paper employs CFA, G-Theory, and mixed-effects latent regression to systematically decompose measurement noise and assess scaling laws.
- The paper demonstrates that contributor effects and benchmark identity contribute more variance than architecture, urging improvements in benchmark design.
AI Cartography: Unveiling the Latent Structure and Noise in Benchmark Ecosystems
Introduction and Motivation
The paper "AI Cartography: Mapping the Latent Landscape of AI Benchmark Ecosystems" (2605.25272) investigates the foundational assumptions and statistical properties underlying AI benchmarking leaderboards, with an explicit focus on the reliability and interpretability of aggregate scores commonly used to rank LLMs. With over 4,000 models from the Open LLM Leaderboard analyzed, the study establishes a comprehensive framework that combines Confirmatory Factor Analysis (CFA), Generalizability Theory (G-Theory), and mixed-effects latent regression to dissect sources of measurement noise and latent capability structure.
Aggregate leaderboard scores have become central to model evaluation, funding decisions, and claims regarding scaling laws. However, such scores are shown to contain substantial measurement noise originating from artifact-driven, ecosystem-specific factors. The paper rigorously quantifies these sources—benchmark idiosyncrasies, contributor effects, architecture families, and deployment strategies—demonstrating that naive aggregation strategies obscure nuanced signals about genuine model capabilities.
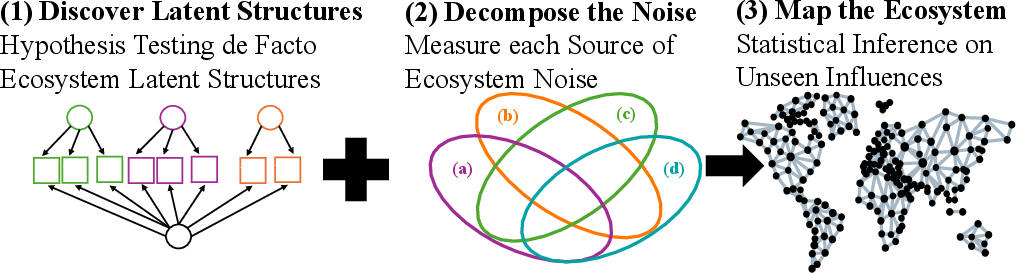
Figure 1: Study overview presenting the three methodological pillars: latent structure discovery, variance decomposition, and noise-controlled latent regression.
Methodological Framework
Structural Discovery via CFA
The CFA approach interrogates the assumptions that leaderboards implicitly make about latent abilities. Six competing structural models are statistically evaluated, spanning independent per-benchmark factors, a single general factor, hierarchical structures, correlated factors, bifactor models, and correlated bifactor models. Item-level bootstrapping and permutation controls are leveraged for robustness against overfitting and to ensure findings are not artifacts of item selection or model flexibility.
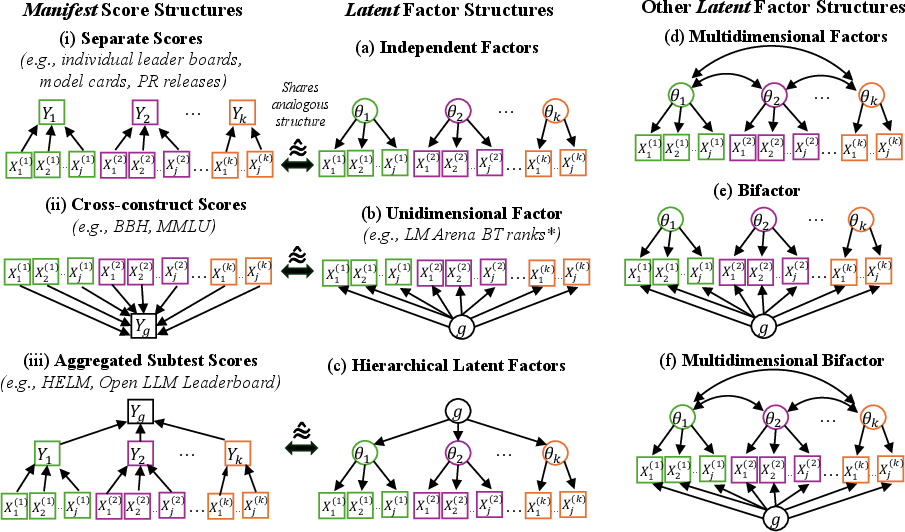
Figure 2: Manifest and latent scoring structures, highlighting the directionality and complexity of latent construct hypotheses used in AI benchmark ecosystems.
Across bootstraps, bifactor models consistently outperform strictly unidimensional or independent models—demonstrating that a dominant general factor (linked to model size) captures a large portion of cross-benchmark covariance, while benchmark-specific factors serve as residual structure. Modification indices, interpreted as Lagrange-multiplier tests, expose persistent local dependence: item pairs retain measurable residual association even after accounting for latent structure, challenging the assumption of benchmarks as independent measurement instruments.
Ecosystem Noise Decomposition via G-Theory
Variance decomposition via G-theory fully crosses four critical facets: architecture, benchmark identity, contributor/provenance metadata, and deployment/tuning choices. The share of leaderboard score variance attributable to each facet and their interactions is estimated using random effects models with random slopes for log-model size.
Contributions from metadata (provenance) explain more rank-relevant variation (~9%) than architecture or deployment, and benchmark identity accounts for ~43-46% of variance. These effects are robust to the granularity of categorization and Bayesian posterior analyses. The impact of contributor (human and procedural) decisions significantly outweighs architecture or deployment in explaining ranking variance.
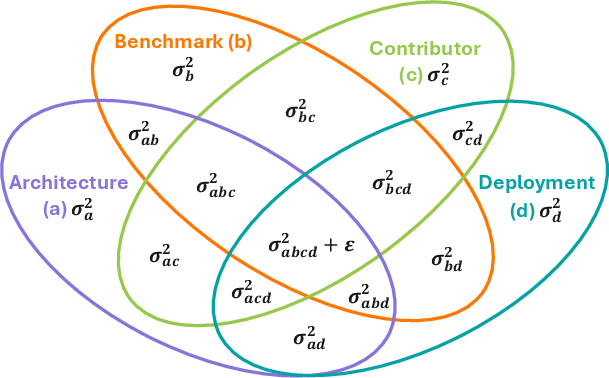
Figure 3: Variance decomposition diagram for four fully crossed facets visualizing ecosystem-induced noise.
Mixed-Effects Latent Regression
To estimate scaling laws and covariate effects on latent abilities, the paper deploys bifactor IRT with mixed-effects latent regression. This unifies measurement and structural modeling, enabling the regression of latent traits (general and benchmark-specific) on ecosystem covariates (size, deployment, contributor) while properly respecting pseudo-replication. The latent scaling vector replaces naive, scalar scaling laws.
Scaling reliability is quantified for each latent dimension as Rd=βd2+τd2βd2, where βd is the fixed-effect slope and τd2 is the random-slope variance. For the general factor, reliability is high (Rg=0.97), while several benchmark-specific abilities exhibit negligible scaling slopes with low reliability, evidencing context-dependent scaling.
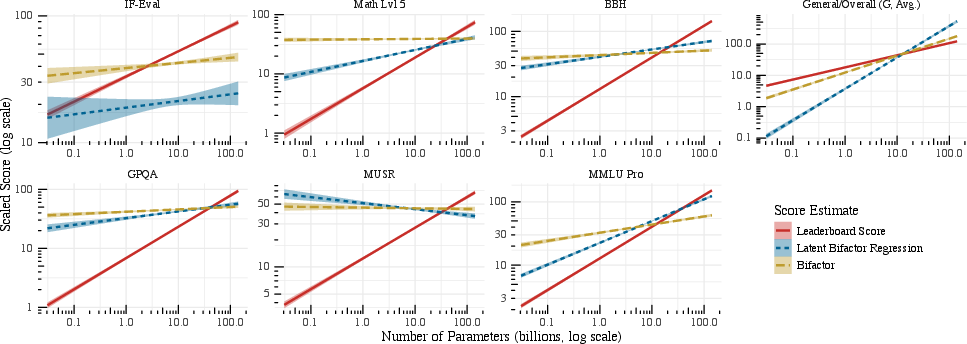
Figure 4: Log-log scaling laws for general and benchmark-specific latent abilities, robustness shown via confidence bands from variance decomposition.
Key Results
- Bifactor structure as scientific model: A general latent factor dominates the leaderboard's covariance, strongly linked to model size, while benchmark-specific residuals persist.
- Measurement assumptions violated: Common leaderboard practices (independent factor models, sum-score aggregation) underestimate inter-benchmark relationships and ignore substantial local dependence, rendering total scores non-construct-preserving.
- Noise attribution and ranking stability: Benchmark identity is the largest variance source, but contributor/provenance accounts for more signal than architecture or deployment. Only 10% of models in the top leaderboard decile retain their rank after conditioning on latent general ability.
- Scaling laws as multidimensional vector: Size robustly improves general latent ability, but scaling benefits for specific reasoning-focused benchmarks (e.g., GPQA, BBH) are trivial after controlling for ecosystem effects. Knowledge-intensive benchmarks (e.g., MMLU-Pro) retain strong scaling, implying that "scaling = capability improvement" is not universal.
- Actionable diagnostics: The paper provides variance decomposition metrics, ranking reliability diagnostics, and local dependence maps for practitioners and benchmark designers.
Figure 5: Scaling laws estimated by robust regression showing ecosystem-controlled differences across benchmark deployments.
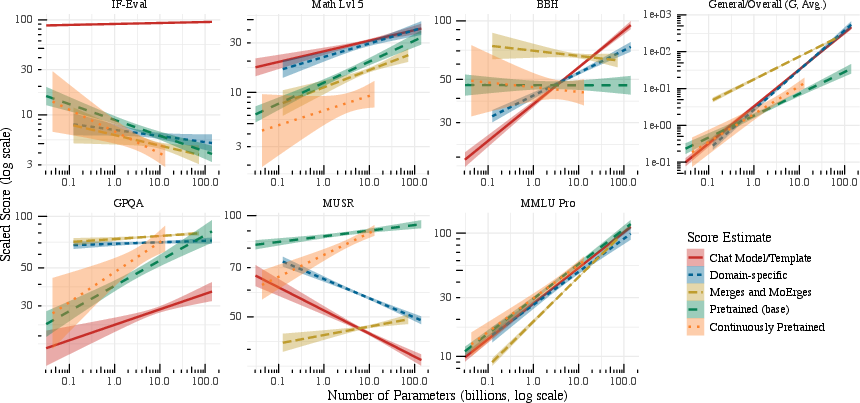
Figure 6: Deployment-specific scaling laws showcase variability introduced by post-training practices and chat template usage.
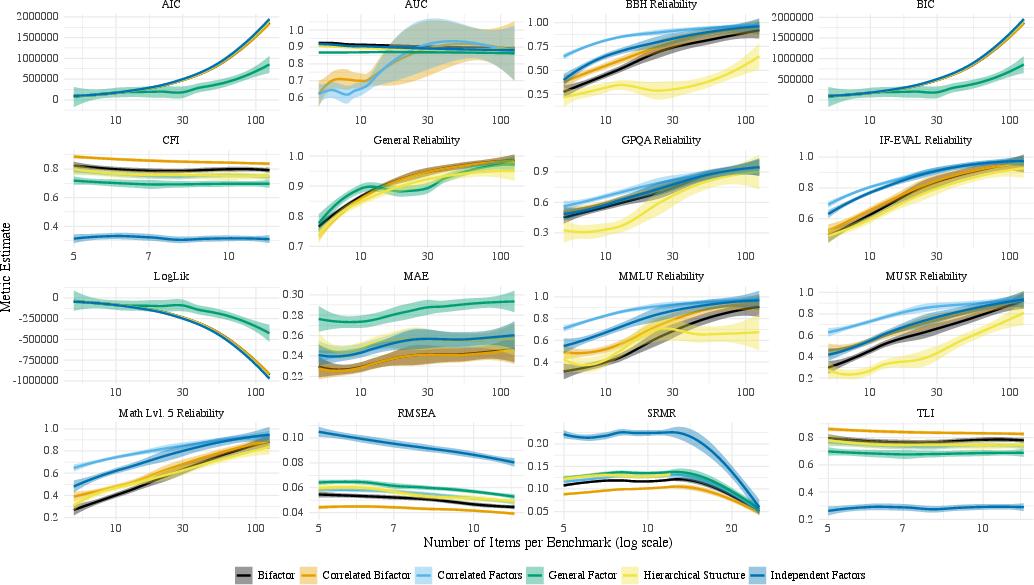
Figure 7: Bootstrap sensitivity analysis demonstrating methodological robustness for fit statistics aggregation.
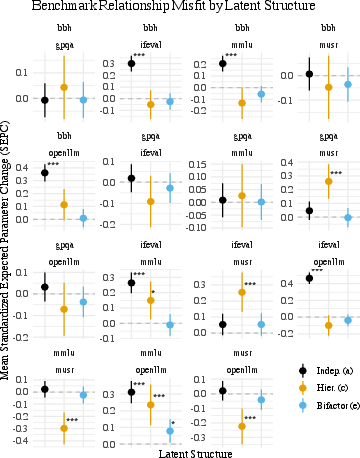
Figure 8: SEPC analysis of latent structure misfit quantifies underestimation and overestimation of inter-benchmark relationships.
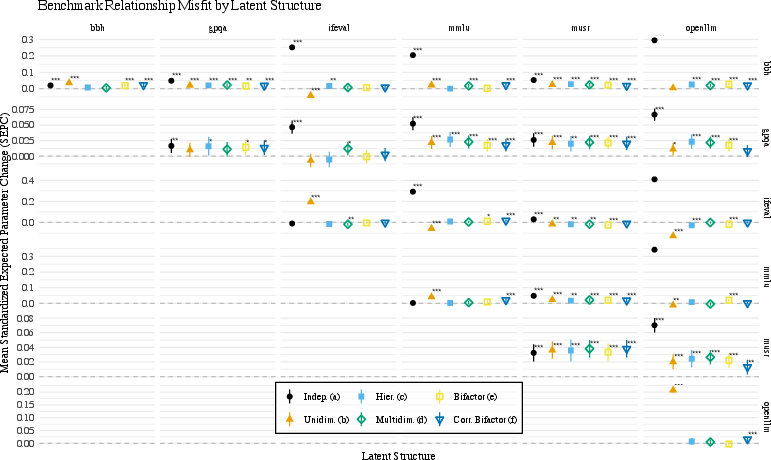
Figure 9: SEPC map post residual variance freeing, indicating item-level local dependence and misspecification.
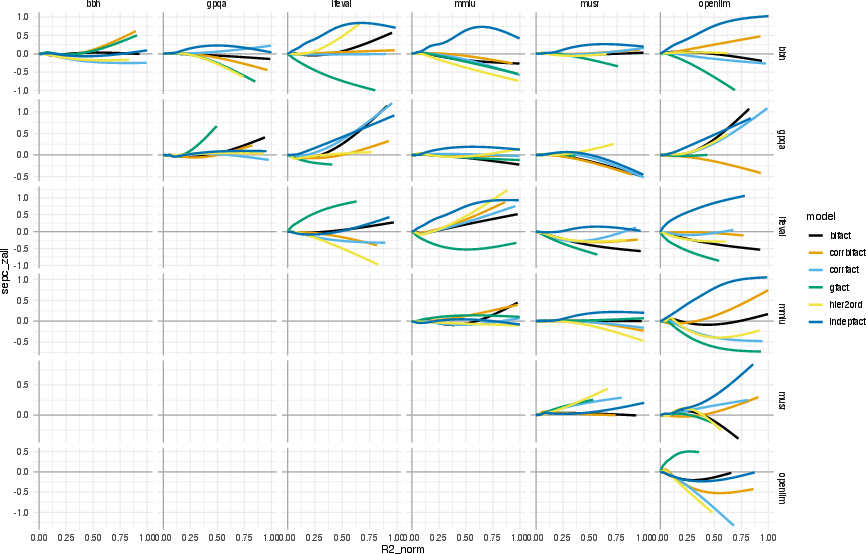
Figure 10: Effect size change diagram reveals latent structure under-/overestimation by freeing residual variance per benchmark.
Implications and Future Directions
Measurement-Theoretic Reframing
This work reframes AI benchmark ecosystems as measurement systems requiring explicit psychometric modeling and statistical validation. Benchmarks should not be treated as independent test suites; their scores reflect interrelated latent abilities and artifact-induced confounding. Methodological rigor—variance decomposition, latent structure hypothesis testing, and noise-controlled inference—is essential for credible claims regarding model capability, scaling, and training intervention efficacy.
Reliability and Trustworthy Rankings
Reliability of leaderboard rankings is conditional on ecosystem features. The prominent contributor effect suggests that human-driven implementation decisions (data mixtures, fine-tuning recipes, documentation) are more influential than architecture or deployment alone. Researchers focused on architecture-centric evaluation should treat provenance as a nuisance and adjust uncertainty accordingly.
Scaling Law Generalizability
Scaling laws are demonstrated to be context-dependent; a single scaling slope is misleading. The vector of scaling effects provides a capability-specific profile. For knowledge benchmarks, scaling drives improvement; for complex reasoning tasks, scaling yields diminishing returns after noise controls. Methodological innovations—such as mixed-effects latent regression—should be adopted universally to disentangle genuine scaling from ecosystem confounding.
Benchmark Design and Reporting
Benchmark ecosystems should adopt multifaceted reporting: difficulty-normalized or stratified scores, uncertainty diagnostics, and explicit latent structure specification. Noise decomposition enables actionable intervention: targeted benchmark construction, improved score aggregation methods, and transparency in the interpretation of ranking stability.
Prospects for AI Evaluation
Future developments should generalize this rigorous evaluation framework to broader classes of AI systems, incorporate dynamic models of ecosystem change, and extend to under-measured abilities (e.g., safety, robustness). Statistical psychometric paradigms—long used in human assessment—will be pivotal for valid, reproducible, and actionable AI comparison.
Conclusion
By deploying advanced measurement-theoretic tools—CFA, G-theory, mixed-effects latent regression—the study establishes that benchmark rankings mix genuine capability signals with ecosystem artifacts. The dominant general factor, measurement noise decomposition, and context-dependent scaling laws collectively point to the necessity of rigorous statistical control for trustworthy AI evaluation. The methodology and diagnostics offered are applicable beyond the presented ecosystem, setting new standards for reliability and interpretability in AI benchmark reporting.