- The paper demonstrates that message-level anonymization fails to protect sensitive demographic data as LLMs infer traits from stylistic and topical cues.
- The methodology applies Llama-3.3-70B-Instruct across multi-country datasets, achieving high F1 scores (0.84-0.90) for inferring age, gender, and country.
- The study reveals stereotype-mediated biases in attribution and calls for robust, conversation-level privacy solutions to mitigate inequitable harms.
Inferential Privacy Leakage in Anonymized Conversational AI Logs
Study Motivation and Data Collection
This paper systematically analyzes inferential privacy risks associated with anonymized conversational logs from ChatGPT, focusing on a corpus of full-user histories donated by over one thousand users from Brazil, India, Nigeria, and Pakistan. Two primary analytic datasets are leveraged: a multicountry set (N=1,057) of ChatGPT logs with demographic labels (age, gender, country), and a sub-cohort (N=212, India) including Google Search, YouTube search, and YouTube watch data, paired with richer demographic attributes (religion, education, income, voting, etc.). The core concern is whether message-level redaction and explicit self-disclosure filters suffice to protect demographic privacy under adversarial LLM inference.
Explicit Disclosure Patterns and Temporal Dynamics
A targeted message-level audit using Llama-3.3-70B-Instruct reveals 34.5% of messages contain personal information (per a twenty-category taxonomy). Disclosure manifests predominantly through job/education (25.1%), lifestyle/habits (18.7%), and mental state (11.6%), rather than direct demographic statements (age 1.5%, gender 0.3%, sexual orientation 0.1%). Median users disclose identifying content by the 14% mark of their conversation history, with a spike at the very first message, and the disclosure rate remains stationary as history accumulates—no observable attenuation in caution as familiarity grows.
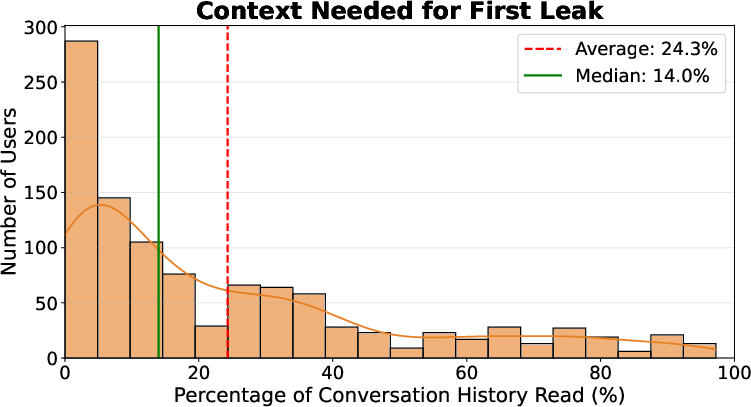
Figure 1: Distribution of the discovery point $P_{\text{discovery}$ showing early explicit disclosure in most conversation histories.
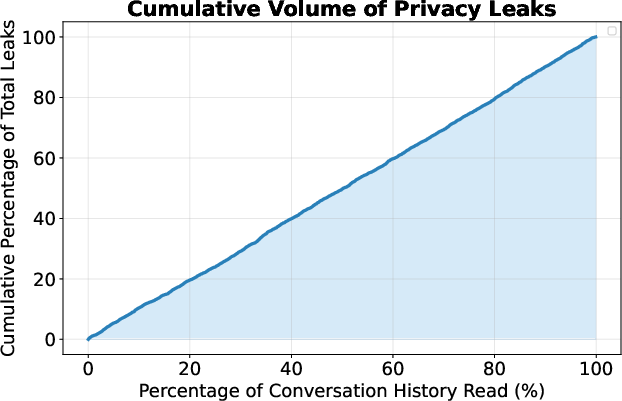
Figure 2: Cumulative flagged-message count versus fraction of conversation history, revealing a linear, stationary disclosure rate.
Demographic Inference from Sanitized Logs
Sanitization filters excluded all explicit demographic self-disclosure (as flagged by LLM classifier) and PII (via SpaCy NER). Even with this conservative regime, Llama-3.3-70B-Instruct accurately inferred user age, gender, and country at weighted F1 scores of 0.84, 0.90, and 0.88 respectively—substantially above majority-class baselines (0.23, 0.52, 0.26). For >50% of users, correct classification was achieved with only the first 5% of their conversation.
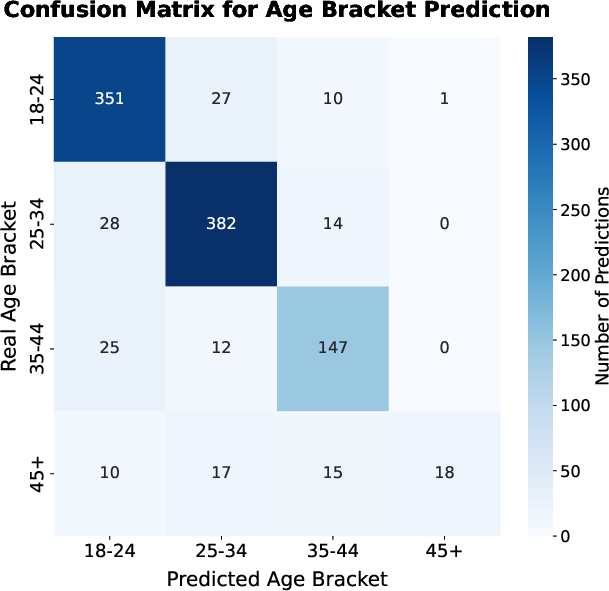
Figure 3: Confusion matrix for age-bracket inference on the N=1,057 analytic cohort, illustrating error clustering on older users and technical professionals.
These results are robust across demographic classes, despite recall collapse for women in technical fields, older users with contemporary skills, and Global South tech professionals (e.g., only 0.36 recall for 45+ age, 0.73 for women). Brazilian identity is perfectly predicted via Portuguese usage (F1=1.0), while Pakistanis and Nigerians are misassigned to Western identities when technical proficiency is observed.
Qualitative analysis of LLM rationales from chain-of-thought prompts reveals four recurrent stereotype patterns driving both correct inference and systematic errors:
- Tech ≡ Male: Any programming, Linux, finance, or cybersecurity content triggers male assignment; female recall (0.73) is substantially lower than male (0.99).
- Tech ≡ Western: Technical content from Nigerian/Pakistani users prompts misclassification as American/British, justified by “Western-style education.”
- English fluency ≡ US/UK: Absence of local linguistic markers results in assignment to Western countries.
- Contemporary Content ≡ Young: Tech-savvy older users are labeled as 25–34, with recall in 45+ group dropping to 0.36.
These bias patterns mirror broader errors in the class confusion matrices and are consistent with established literature on LLM stereotype propagation [sheng2019woman], [abid2021persistent].
For 212 Indian users, the same incremental-prefix inference protocol was applied to Google Search, YouTube search, and YouTube watch histories. ChatGPT logs proved the strongest signal for age (F1=0.87), education (F1=0.87), and voting preference (F1=0.59); search-based streams were superior for gender, religion, and income. YouTube watch history consistently performed worst across all attributes. Notably, search and watch platforms require less context for correct inference (e.g., gender: 7.1% for YouTube Search versus 12.0% for ChatGPT), indicating that succinct, intent-focused queries are demographically efficient, while conversational AI contains diluted but richer signals.
Theoretical and Practical Implications for Privacy
The empirical results directly contradict the claim that message-level PII removal suffices for anonymization. Stylistic and topical features in chat logs are potent proxies for identity—a sanitized conversation alone can serve as a substrate for demographic inference comparable to web search profiling. The inference attack is not a memorization or data-leak scenario; rather, generic pretraining-driven priors enable inference on unseen texts, akin to stylometric attribution.
Practical implications are deep: privacy interventions must move toward conversation-level or paraphrase-based rewriting to mitigate these risks. Substrate-level anonymization is inadequate when profile-building spans heterogeneous surfaces (AI conversations, search queries, media consumption).
Inequitable Privacy Harm and Regulatory Challenges
The stereotype-driven inference mechanism induces asymmetric error distribution, exposing both stereotype-conforming users (direct privacy risk) and nonconforming users (mis-assignment and representational harm). Current privacy regimes (GDPR, CCPA) do not account for stratification axes (e.g., caste, regional identity) salient in the Global South. The paper thus highlights the need for equity-focused regulatory intervention and further cross-cultural audit.
Conclusion
LLMs can infer demographic attributes from sanitized ChatGPT logs at high accuracy, relying on stereotype-mediated reasoning from style and topic alone, even after explicit self-disclosure and PII have been removed. The findings situate conversational AI as a profiling surface on par with (but orthogonal to) traditional search/history substrates, and underscore the insufficiency of current message-level anonymization strategies. Future developments should prioritize conversation-level privacy techniques, robust cross-cultural auditing, and regulatory frameworks sensitive to inference-based privacy harm.