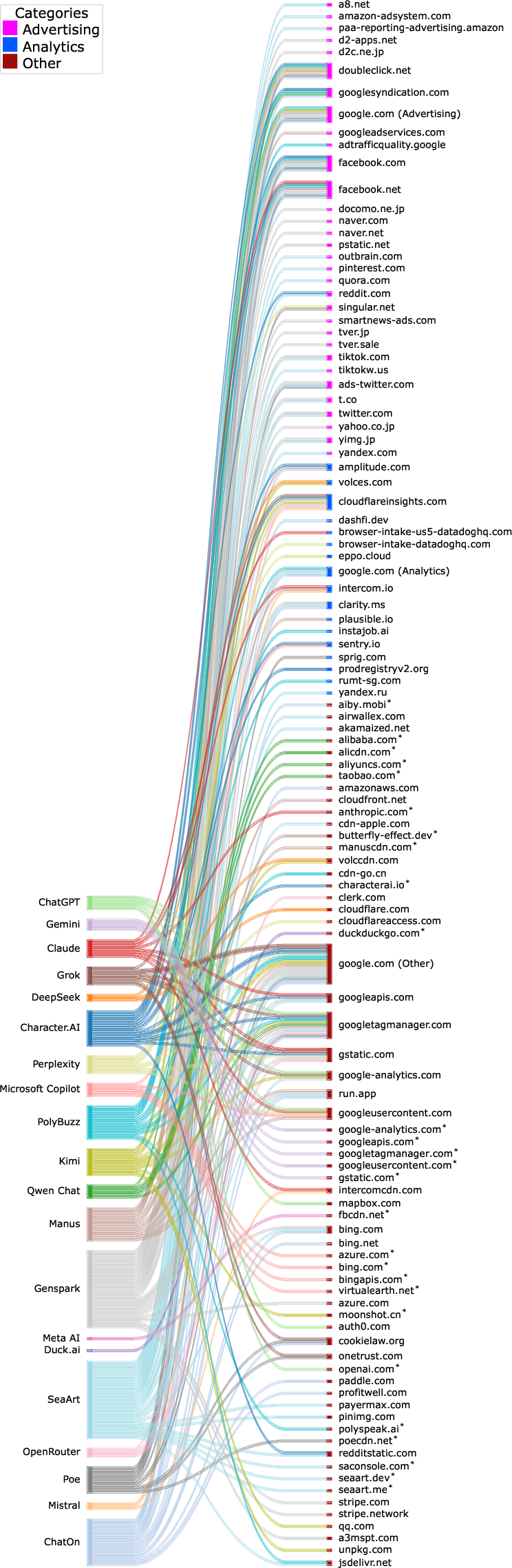
- The paper presents the first systematic audit of AI chatbots, revealing that 17 of 20 platforms transmit sensitive conversational and identity data to third parties.
- It employs controlled sessions and network traffic analysis to detect key exposure vectors such as session replay, embedded widgets, and metadata harvesting.
- The findings underscore significant privacy risks, prompting calls for improved design strategies and clearer regulatory frameworks to prevent unauthorized data sharing.
Tracking Content and Identity Exposure in AI Chatbots: An Empirical Audit
Introduction and Motivation
"Tracking Conversations: Measuring Content and Identity Exposure on AI Chatbots" (2604.27438) presents a comprehensive measurement study of third-party tracking and data exposure in web-based AI chatbot platforms. As LLM-driven chatbots consolidate their role as primary information interfaces, privacy threats intensify due to direct personal disclosures and persistent authentication, shifting tracking from traditional browser-level artifacts (cookies, fingerprints, IP) to account-level identifiers (emails, names). This paper establishes the first systematic audit of these risks across 20 top-ranked chatbot providers, revealing detailed structures of both content and identity exposure.
Methodology
The audit targets the network layer, capturing traffic during controlled sessions with a highly sensitive prompt ("pregnancy test near me") across both normal and private/incognito chat modes. For each chatbot, new accounts are created, and traffic is recorded in Chrome, focusing on transmission of:
- Content: prompt text, keywords, prompt-derived titles, chat URLs, chat identifiers, assistant responses.
- Identity: names, emails, internal IDs, account cookies, explicit IP/User-Agent in payloads.
Preprocessing uncompresses/decodes payloads and extracts string/hashing variants to maximize detection of exposed artifacts, including explicit and masked forms. Requests are categorized by party affiliation: first-party, platform-party, and third-party; third-party domains are further classified into analytics, advertising, and other.
Widespread Tracking: Distribution of Data Flows
A dominant finding is that 17/20 chatbots share information with at least one third-party during a single session. Platform-party routing (e.g., Gemini's Google Analytics, Copilot's Microsoft Clarity) is distinguished from bona fide third-party flows. Notably, three chatbots do not embed external third parties, instead limiting flows to platform-owned domains.
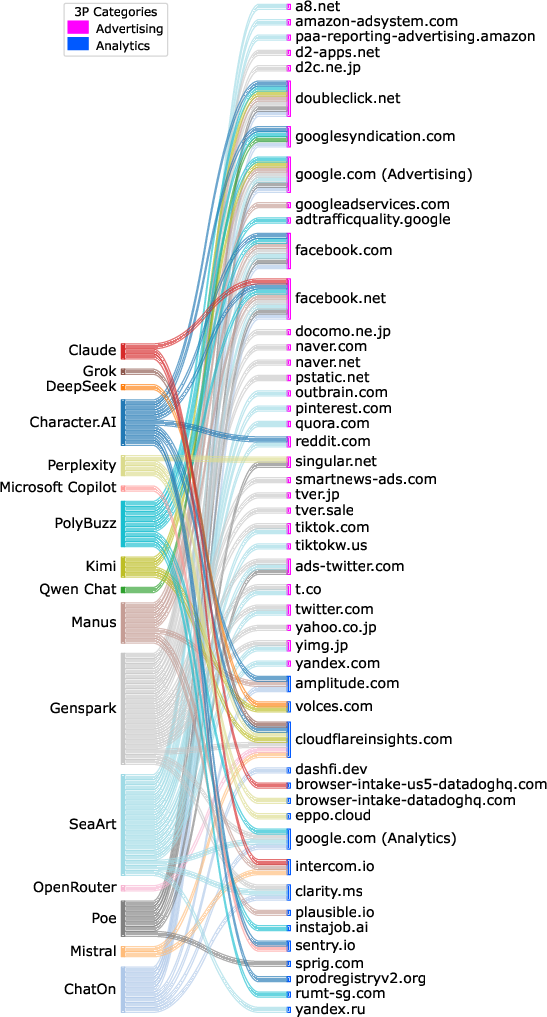
Figure 1: Sankey diagram showing the data flows from chatbots to advertising and analytics third-parties in normal chats, highlighting widespread cross-party transmission.
Advertising domains, though less ubiquitous than analytics, comprise the highest volume of unique flows. Some chatbots (e.g., SeaArt, Genspark) contact more than a dozen distinct advertisers in one interaction, emphasizing the high granularity of cross-site identifier linkage possible.
Content Exposure Mechanisms
Three vectors drive content exposure:
These mechanisms amplify risk: session replay is especially problematic, as rendered DOM often includes both sensitive content and user identity, allowing for deep cross-context correlation.
Identity Exposure Vectors
Identity artifacts reach third parties in numerous ways:
- Support Widgets: Intercom widget transmits user email, name, internal ID, and hash, even if user never interacts with support interface.
- Analytics/Error Monitoring: Sentry and Statsig tags receive explicit labels and user configuration data (email, IP, User-Agent) in payloads.
- Advertising Tags: Hashed emails are widely shared (Perplexity to Singular, SeaArt to TikTok Pixel) supporting persistent cross-site recognition; first-party cookies such as _fbp, _uetsid, _uetvid are consistently transmitted, even across chatbot platforms.
- Session Replay (Clarity): Account identity is captured as readable DOM text, even when not explicitly labeled, further exacerbating correlation risks.
Private (Incognito) Chat Evaluation
Private chat modes demonstrate marked reduction in tracking. Among chatbots supporting such modes, exposure to third parties plummets, and neither content nor identity information is transmitted externally. However, privacy policy disclosures rarely clarify extent of tracking mitigation, focusing instead on retention and model training opt-outs.

Figure 3: Sankey diagram of data flow from chatbots to all parties in temporary chats, demonstrating substantial attenuation of third-party sharing.
Mitigation Strategies and Policy Gaps
The paper proposes design/configuration mitigations that do not require removal of analytics/ads:
- Exclude prompt/chat identifiers/titles from page URLs and document.title metadata.
- Avoid passing raw prompts to embedded widgets; server-side resolution for integrations (e.g., location) should sanitize queries.
- Configure session-replay tools to mask DOM content or restrict deployment to unauthenticated pages.
- Minimize inclusion of account identifiers in analytics/error monitoring payloads.
Privacy policy alignment is inconsistent. Eight out of twenty policies fail to name third parties observed during measurement; some omit significant recipients (e.g., Microsoft Clarity). Only Claude and OpenRouter provide comprehensive enumeration and data-type mapping. Duck.ai is an exceptional case, deliberately stripping user IPs and avoiding tracking.
Implications and Future Directions
This study exposes an industry-wide gap between stated privacy policies and actual data transmission. The implications are severe: content/identity exposure across analytics, advertising, widgets, and session replay enables high-fidelity behavioral and contextual inference, especially given the sensitive and authenticated nature of chatbot sessions.
From a theoretical perspective, the prevalence of session replay on conversational interfaces expands the traditional attack surface. Existing privacy risk models—focused on search and browsing—are insufficient when LLMs drive deeper, context-rich communication with persistent identifiers.
Practical implications span regulatory compliance, cross-site identity linkage, and user trust erosion. Providers must adopt granular tracking controls, explicitly enumerate third-party recipients, and develop masking/configuration strategies for embedded third-party tools. Furthermore, private modes should be clearly described as tracking controls and not solely as retention/model-training mitigations.
Anticipated future developments include:
- Standardization of privacy controls for chatbots, especially around session replay and widget integration.
- Regulatory guidance specific to conversational context exposure, given the increasing use of chatbots for health, finance, and sensitive domains.
- Privacy-enhancing architectures that decouple conversational context from page metadata and network payloads, possibly leveraging client-side LLM inference.
Conclusion
The paper provides a critical empirical foundation for understanding and regulating tracking in AI chatbots (2604.27438). Through deep, systematic audit across content and identity vectors, it documents widespread third-party exposure, identifies mechanisms underlying transmission, and evaluates privacy modes. Its insights motivate urgent redesign of chatbot interface architecture, transparent disclosure of data flows, and precision-regulated deployment of third-party tools, marking a significant step toward safeguarding user privacy in LLM-driven conversational interfaces.