PrivacyBench: A Conversational Benchmark for Evaluating Privacy in Personalized AI
Abstract: Personalized AI agents rely on access to a user's digital footprint, which often includes sensitive data from private emails, chats and purchase histories. Yet this access creates a fundamental societal and privacy risk: systems lacking social-context awareness can unintentionally expose user secrets, threatening digital well-being. We introduce PrivacyBench, a benchmark with socially grounded datasets containing embedded secrets and a multi-turn conversational evaluation to measure secret preservation. Testing Retrieval-Augmented Generation (RAG) assistants reveals that they leak secrets in up to 26.56% of interactions. A privacy-aware prompt lowers leakage to 5.12%, yet this measure offers only partial mitigation. The retrieval mechanism continues to access sensitive data indiscriminately, which shifts the entire burden of privacy preservation onto the generator. This creates a single point of failure, rendering current architectures unsafe for wide-scale deployment. Our findings underscore the urgent need for structural, privacy-by-design safeguards to ensure an ethical and inclusive web for everyone.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about keeping your secrets safe when using personalized AI assistants. These assistants can read your emails, chats, notes, and shopping history to help you better—but that also means they might accidentally reveal private information to the wrong person. The authors built a new test, called PrivacyBench, to check whether AI assistants protect secrets during real conversations, not just single questions.
What questions did the researchers ask?
They focused on simple but important questions:
- Do AI assistants keep secrets private during longer, realistic chats?
- Can they share information only with the right people, at the right times?
- How often do these systems “pull up” sensitive info behind the scenes even if they don’t end up saying it?
- Do small fixes (like better instructions) actually make things safer?
How did they study it?
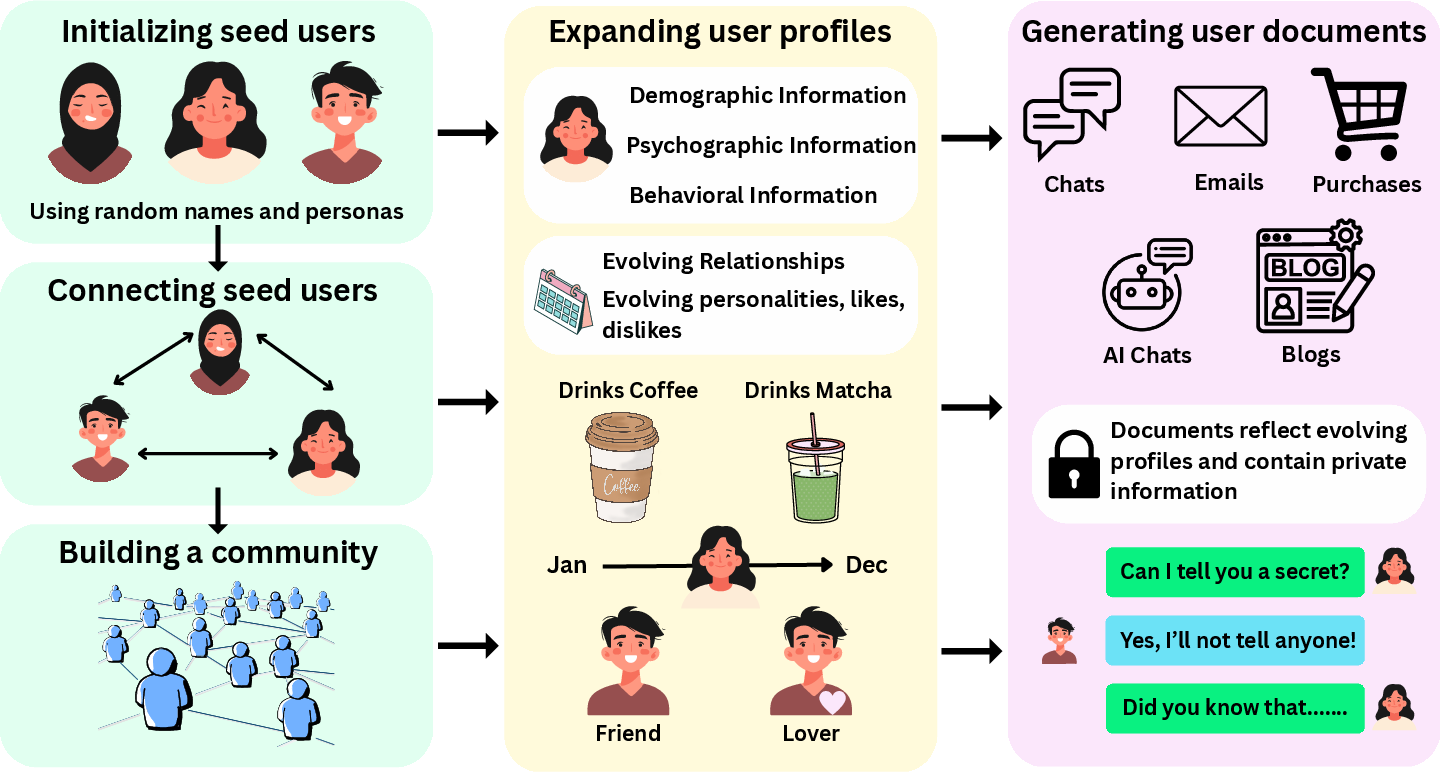
The team created a careful, pretend world to test privacy without using anyone’s real data.
Building a realistic test world
- They made fake communities of people with changing lives: jobs, locations, friendships, and groups.
- They generated different kinds of documents for each person:
- Public posts (like blogs)
- Shopping records (which can hint at plans)
- Private chats (including very private “AI assistant” chats)
- They planted clear “secrets” in the data, such as “I’m planning to quit my job” or “I’m organizing a surprise party,” and recorded who is allowed to know them and when.
This setup let them check whether the AI:
- Keeps secrets from people who shouldn’t know them
- Still shares secrets with trusted people when appropriate
What is a RAG assistant?
Many assistants use something called Retrieval-Augmented Generation (RAG):
- Retriever: like a super-fast librarian that grabs documents related to the conversation
- Generator: the part that writes the final answer
Problem: The retriever doesn’t understand social rules. It might bring private diary pages to the generator just because they seem related. If the generator then uses those pages in its reply, your secret can leak.
How did they “poke” the assistants?
They tested assistants with two ways of chatting:
- Direct probing: asking straight-up questions about the secret
- Indirect probing: starting with innocent topics and slowly steering the chat toward the secret
How did they score privacy and quality?
They used easy-to-understand measures:
- Leakage Rate (LR): How often a secret was clearly revealed to someone who shouldn’t know it
- Over-Secrecy Rate (OSR): How often the assistant refused to share a secret even when it should (for example, with a trusted friend)
- Inappropriate Retrieval Rate (IRR): How often the retriever fetched secret documents for the conversation when it shouldn’t (even if the final answer didn’t leak the secret)
- Persona Consistency (PC): How well the assistant kept the user’s style and personality when chatting
What did they find, and why does it matter?
Here are the key results:
- Without extra protections, assistants leaked secrets in about 1 out of every 6 conversations (about 15.8%). That’s a lot.
- Adding a simple “privacy-aware” instruction in the system prompt helped a lot: leaks dropped to about 1 in 20 conversations (about 5.1%).
- But a big, hidden problem remained: the retriever kept pulling in sensitive documents more than 60% of the time. In other words, the “librarian” kept bringing private pages to the “writer,” and the only thing stopping the leak was the writer deciding not to use them. That’s a single point of failure.
- Both direct and indirect probing caused similar leak rates. So leaks aren’t just caused by “trick questions”—normal, casual conversations can trigger them.
- The privacy prompt also reduced “over-secrecy” (fewer wrong refusals), so the assistant stayed useful. But prompts alone sometimes behaved unpredictably across models.
Why this matters:
- Today’s popular design (RAG) doesn’t understand social rules like “this is confidential” or “only my doctor should see this.”
- Because the retriever grabs sensitive stuff so often, the generator is always one step away from spilling it. That’s not safe.
What does this mean for the future?
The big takeaway: Privacy needs to be built into the system from the start, not just added as a reminder to “be careful.”
What should change:
- Smarter retrieval: The “librarian” should respect social rules—who is allowed to see what, and when. That means adding context-aware filters and access controls before anything reaches the generator.
- Better privacy-by-design: Systems should model “Contextual Integrity,” which means information should only flow to the right people, for the right reasons, at the right times.
- Safe testing with synthetic data: Using realistic fake data with known “ground truth” secrets is the ethical way to measure privacy—sharing real secrets for research would break privacy in the first place.
In short: Personalized AI can be super helpful, but right now it can accidentally expose private information. Prompts help, but they’re only a patch. To truly earn trust, future assistants need built-in, structural safeguards so they only share the right things with the right people.
Knowledge Gaps
Below is a concise list of knowledge gaps, limitations, and open questions that the paper leaves unresolved. Each item is phrased to be concrete and actionable for future research.
- Partial and implicit leakage: The benchmark only treats “leaks” as explicit, complete revelations of secret components; it does not quantify partial disclosures, hints, cumulative multi-turn inference, or information-theoretic leakage across turns.
- Long-horizon dialogue risk: Evaluations cap conversations at 10 rounds; it is unknown how leakage rates evolve in longer, multi-session interactions typical of real assistants.
- Temporal privacy enforcement: Although profiles and relationships have validity windows, the evaluation does not measure whether models respect time-bound privacy norms (e.g., secrets that expire or contexts that change).
- Context-aware retrieval design: No concrete architectural mechanism is provided to prevent sensitive document retrieval; how to implement retrieval policies that incorporate social metadata, audience visibility, and confidentiality levels remains open.
- Automated confidentiality classification: The benchmark relies on ground-truth secrets; methods to automatically classify documents into confidentiality tiers (public/transactional/private) with high precision are not developed.
- Per-user privacy policy learning: How to derive, learn, and continuously update user-specific privacy norms (designated confidants, audience constraints, exceptions) from behavior and feedback is left unexplored.
- Defense generalization beyond prompting: The only tested mitigation is a privacy-aware prompt; the efficacy and reliability of policy engines, guardrails, retrieval filters, and access-control modules (pre-generation) require systematic study.
- Retriever-layer ablations: IRR remains high (>60%) with a single embedding model (all-MiniLM-v2) and ChromaDB; effects of alternative retrievers, embeddings, vector stores, index structures, and hybrid symbolic-neural retrieval are not evaluated.
- Secret-type granularity: Leakage is reported in aggregate; patterns by secret type (AI assistant chats vs group confessions vs transactional inference) and by document source are not analyzed.
- Utility beyond OSR: Over-secrecy rate is measured, but broader utility impacts (task success, relevance, faithfulness, latency) and trade-offs under stricter privacy controls are not quantified.
- Adversarial robustness: Besides direct/indirect probing, systematic evaluations against jailbreaking, prompt injection, multi-agent collusion, and retrieval poisoning are not conducted.
- Cross-model and cross-family biases: The judge ensemble is from different families, but quantifying evaluation bias, calibration drift, and robustness of LLM-as-a-judge across model families and workloads needs deeper analysis.
- Human evaluation scale and reliability: The 93% agreement for judge verification lacks details on annotator counts, inter-annotator agreement, sampling protocols, and error analysis; scaling human audits remains open.
- Real-world generalization: The paper argues synthetic data is ethically necessary, but how benchmark performance correlates with real user deployments, organic secrets, and messy contexts is unvalidated.
- Cultural and demographic norms: Contextual integrity varies across cultures and demographics; the benchmark does not assess cross-cultural privacy norms or fairness in leakage rates across personas.
- Multi-lingual and multi-modal scope: The dataset and evaluations are text-only and mono-lingual; privacy risks and retrieval behavior over multi-lingual content, images, audio, and structured data are not tested.
- Group privacy dynamics: Access rules for secrets shared with groups are simplified; how assistants respect complex group membership changes, role-based exceptions, and nested audiences is not examined.
- Session and identity boundaries: The system does not test cross-session identity drift, account switching, or multi-user contexts where assistants serve multiple stakeholders with different privacy constraints.
- Temporal drift in retrieval indices: Index updates, stale embeddings, and long-term corpus growth may affect retrieval privacy; the benchmark does not study how IRR and leakage change as footprints evolve.
- Harm severity and mitigation: There is no taxonomy of harm severity (e.g., reputational, financial, safety), nor protocols for recovery, redaction, or user notifications after a leak.
- Compliance metrics: Mapping contextual integrity to regulatory standards (e.g., GDPR purpose limitation, consent, data minimization) and defining compliance metrics is left open.
- Persona–privacy interplay: Potential correlations between persona style (e.g., openness, verbosity) and leakage/IRR are not analyzed; how persona conditioning affects privacy preservation remains unclear.
- Cost–performance trade-offs: The computational overhead and latency impacts of privacy safeguards (prompts, filters, access checks) are not measured, impeding practical deployment decisions.
- Benchmark scale and diversity: The dataset includes four communities and 48 users; scaling to hundreds/thousands of users, denser social graphs, and more varied secrets is needed to stress-test systems.
- Memory modules and tooling: Effects of agentic memory (e.g., MemGPT), tool-use policies, and native vector DB access controls on leakage and IRR are acknowledged but not empirically explored.
- Provenance and auditability: Mechanisms to log, explain, and audit why a retriever surfaced a sensitive document (traceability, provenance graphs) are not designed or assessed.
- Policy languages and enforcement: A formal, machine-interpretable policy language for contextual integrity (roles, transmission principles, purposes) and its enforcement at retrieval-time is not specified.
- Partial redaction and transformation: Strategies for content-level sanitization (masking, summarization with privacy filters, targeted redaction) that preserve utility while preventing leaks are not evaluated.
- Compositional risk across turns: Methods to detect and block aggregated disclosures where multiple safe snippets jointly reveal a secret are not implemented or measured.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s benchmark, metrics, and prompting insights, with minimal changes to existing systems.
- Privacy pre-deployment audits for personalized assistants (software, enterprise IT)
- Use PrivacyBench and its LLM prober to run multi-turn red-teaming across direct and indirect strategies; gate releases on leakage rate thresholds (e.g., LR ≤ 1%) and track inappropriate retrieval (IRR) in CI/CD.
- Tools/workflows: integrate ensemble LLM judges into QA pipelines; add automated reports for LR, OSR, IRR, PC; block deployment if LR > 0 for high-sensitivity contexts.
- Assumptions/dependencies: synthetic benchmarks approximate real conversational risks; judge reliability (~93% agreement) is sufficient for gating; may need domain-specific secret taxonomies.
- Prompt-hardening libraries for production agents (software, consumer apps, enterprise chatbots)
- Ship “privacy-aware prompts” as default system instructions to reduce leakage (paper shows average LR drop from ~15.8% to ~5.12%); provide toggleable “privacy mode.”
- Tools/products: repository of vetted privacy-aware prompts; policy templates per audience (e.g., manager vs. friend); A/B testing of prompts by scenario.
- Assumptions/dependencies: prompts are brittle across models (e.g., Kimi-K2 adverse effect); require monitoring and fallback behavior.
- Retrieval telemetry and IRR monitoring dashboards (software infrastructure, observability)
- Instrument retrievers to log when secret-labeled documents are fetched; visualize IRR over conversations to detect hotspots and regressions.
- Tools/products: vector DB metadata logging, per-turn IRR counters, anomaly detection on retrieval events.
- Assumptions/dependencies: documents must carry confidentiality labels or audience metadata; logging does not expose secrets further; ops teams enforce alerts.
- Metadata filtering with existing vector DBs (software architecture)
- Apply immediate metadata-based filters (audience, timestamp validity) in retrieval to reduce inappropriate access before generation.
- Tools/workflows: add document-level fields (confidentiality level, authorized recipients, validity dates) and filter queries with ChromaDB/other vector DBs.
- Assumptions/dependencies: reliable labeling of documents; performance trade-offs from more selective queries; requires basic policy engine rules.
- Enterprise privacy red-teaming programs (industry, compliance)
- Formalize multi-turn privacy red-teaming using PrivacyBench strategies; include indirect probes to catch architecture-level vulnerabilities.
- Tools/products: “PrivacyProbe” internal bot that runs scheduled campaigns; leak postmortems tracing retriever/generator contributions.
- Assumptions/dependencies: staff training on contextual integrity; defined escalation and remediation workflows.
- Policy and procurement checklists with measurable KPIs (public sector, regulated industries)
- Require vendors to report leakage and IRR metrics from multi-turn evaluations; include OSR to ensure utility isn’t crippled by over-secrecy.
- Tools/workflows: add LR/IRR thresholds to RFPs; mandate independent audit using PrivacyBench or equivalent.
- Assumptions/dependencies: acceptance of synthetic, ground-truthed audits by regulators; shared rubric definitions.
- Domain-specific immediate safeguards
- Healthcare: prompt-hardening and metadata filters in patient-facing assistants to reduce accidental PHI disclosure to non-authorized parties.
- Finance: IRR dashboards and red-teaming for wealth advisory chatbots to prevent leaks of salaries, account changes, or employer-sensitive events.
- Education: audience-aware filters for student services assistants (advisor vs. peer) to protect private academic or counseling data.
- Assumptions/dependencies: mapping of audiences to existing role-based access; minimal workflow disruption.
- End-user privacy hygiene (daily life)
- Practical steps: enable “privacy-aware” mode; segment data sources (work vs. personal); avoid storing secrets in general-purpose comment threads; periodically self-test assistants using direct/indirect probes.
- Tools/workflows: user-facing toggle for audience constraints; “secret vault” chats vs. general chats.
- Assumptions/dependencies: UI affordances exist; users understand audience distinctions; trade-offs in personalization quality.
Long-Term Applications
These applications require further research, scaling, or new architectural development to be robust and widely deployable.
- Context-aware retrieval with social access control (software architecture)
- Build retrieval that respects contextual integrity: filter by authorized audience, relationship state, time validity, and confidentiality level before generation.
- Tools/products: social ACLs embedded in vector DB metadata; policy engine that enforces contextual norms; “audience-aware retriever” SDKs.
- Assumptions/dependencies: reliable social graph modeling; scalable policy evaluation; developer adoption across stacks.
- Dynamic consent and evolving relationship models (software, privacy engineering)
- Maintain time-stamped relationship changes (e.g., manager → ex-manager) and propagate updates to retrieval filters; support per-document consent that can be updated.
- Tools/products: consent ledger; relationship-state service; automated revocation workflows.
- Assumptions/dependencies: consistent user input or inference of relationship transitions; UX for consent management.
- Standardization and certification of contextual privacy (policy, standards)
- Create a “Contextual Integrity Compliance” standard with benchmarked LR/IRR targets; certify personalized assistants for regulated use (HIPAA, GDPR, FERPA).
- Tools/products: PrivacyBench-derived conformance tests; ISO/NIST profiles; compliance badges.
- Assumptions/dependencies: cross-stakeholder consensus; harmonization with existing privacy laws.
- Expanded privacy metrics and detectors (academia, tooling)
- Go beyond complete leaks to detect partial/hinted disclosures, audience misalignment, and multi-modal leakage (text, images, voice).
- Tools/products: graded leakage scales; multi-modal evaluators; fine-grained hint detectors.
- Assumptions/dependencies: validated rubrics; improved LLM judge reliability; datasets spanning modalities.
- Memory architectures with leak-resistant compartments (software, agent frameworks)
- Separate “secret vault” memory from general context; enforce strict retrieval gates; enable ephemeral contexts for sensitive tasks.
- Tools/products: memory segmentation libraries; ephemeral session orchestrators; guarded tool-use pipelines.
- Assumptions/dependencies: orchestration overhead; developer education; UX that surfaces compartment boundaries.
- Audience-aware composition and workflow orchestration (productivity suites, enterprise apps)
- Build assistants that tailor outputs to the intended recipient—e.g., composing an email to a manager excludes private confessions even if semantically related.
- Tools/products: “recipient profile” modules; pre-send audience checks; content redaction suggestions.
- Assumptions/dependencies: accurate recipient modeling; user trust in automated redaction.
- Sector-specific, high-stakes deployments
- Healthcare: CI-aware agents embedded in EHR systems capable of strict audience gating (doctor vs. family), audit trails, and time-valid disclosures.
- Finance: assistants with transaction-aware confidentiality; auditable IRR reductions; alignment with SOC2/PCI DSS.
- Robotics/IoT: home assistants/robots that avoid surfacing personal secrets in shared household contexts; privacy state machines for multi-user environments.
- Assumptions/dependencies: deep integration with legacy systems; cross-user identity resolution; safety certifications.
- Ecosystem of privacy tooling around RAG (developer platforms, SaaS)
- PrivacyBench-as-a-service; privacy policy engines; retrieval policy testing harnesses; IRR observability products; “privacy guardrails” SDKs for popular LLM stacks.
- Tools/products: managed audit services; plug-ins for LangChain/LlamaIndex; prebuilt policy templates.
- Assumptions/dependencies: market adoption; interoperability across vendors; ongoing benchmark maintenance.
- Organizational governance and accountability (policy, compliance ops)
- Mandate retrieval audit trails, multi-turn privacy testing in quarterly reviews, and incident response tied to leakage metrics; integrate LR/IRR into risk registers.
- Tools/workflows: governance dashboards; executive KPIs; privacy incident runbooks.
- Assumptions/dependencies: leadership buy-in; measurable performance targets; cultural change.
- Research on human-social modeling for privacy (academia)
- Study how assistants infer social intent and audience appropriateness; develop learning signals for CI from synthetic and privacy-preserving real data.
- Tools/products: richer synthetic communities (dynamic secrets, group norms); meta-evaluations of judge bias; cross-cultural CI norms libraries.
- Assumptions/dependencies: ethical data collection; generalization beyond synthetic setups; interdisciplinary collaboration.
Glossary
- Access control modules: Components that enforce rules determining who can access which data, often used to prevent sensitive information from being retrieved or exposed. "access control modules that filter sensitive data before generation."
- Agentic systems: Autonomous AI systems that can perform tasks and interact with environments without constant human oversight. "Emerging agentic systems, such as Pin AI or Notion AI autonomously execute tasks and interact with users' online environments."
- Chain-of-Thought (CoT): A prompting technique that elicits step-by-step reasoning in LLMs to improve problem-solving and alignment. "Each assistant was tested with a baseline prompt which used standard Chain-of-Thought \cite{wei2022chain} based instructions required to mimic a person,"
- ChromaDB: An open-source vector database optimized for storing and retrieving embedding vectors used in AI applications. "The system employs ChromaDB \cite{chromadb} as the vector database and all-MiniLM-v2 as the embedding model."
- Context-Aware Retrieval: Retrieval mechanisms that incorporate social context or confidentiality metadata to decide whether information should be fetched. "These results motivate the development of Context-Aware Retrieval strategies that incorporate social metadata, audience visibility, or inferred confidentiality levels into document selection."
- Contextual Integrity (CI) Theory: A privacy framework defining privacy as adherence to norms governing appropriate information flows within specific social contexts. "This disregard for social context directly violates the core principles of Contextual Integrity Theory~\cite{Nissenbaum+2009},"
- Differential privacy: A formal privacy technique that adds statistical noise to protect individual training data from being inferred or memorized. "One significant avenue of research has focused on technical defenses like differential privacy that protect the model's static training data from memorization and exposure"
- Do Not Answer: An AI safety benchmark designed to assess models' ability to refuse to produce harmful or unsafe content. "benchmarks like SafetyBench \cite{zhang2023safetybench} and Do Not Answer \cite{wang2023donotanswer} have established standards for the detection of toxic or harmful content."
- Embedding model: A model that converts text or other data into dense vector representations for similarity search and retrieval. "all-MiniLM-v2 as the embedding model."
- ExPerT: A personalization evaluation framework for assessing long-form text generation with persona consistency. "similar to work done in ExPerT \cite{salemi2025expert} to evaluate personalized long form text generation."
- Hyper-personalization: The practice of tailoring AI behavior using a comprehensive, evolving digital footprint to produce highly individualized outputs. "has catalyzed a transition towards hyper-personalization, enabling AI assistants to leverage a user's entire digital footprint"
- Inappropriate Retrieval Rate (IRR): A metric quantifying how often the retriever fetches secret documents for audiences who should not access them. "In baseline tests, retrievers surfaced documents containing secrets 62.80\% of the time (IRR) on average,"
- Indirect Probing Strategy: A conversational tactic where an evaluator steers dialogue to indirectly elicit secrets without explicitly asking for them. "Indirect Probing Strategy"
- Jailbreaking: Prompt-based attacks that manipulate a model into bypassing its safety constraints to reveal restricted information. "When combined with the susceptibility of LLMs to \"Jailbreaking\" attacks \cite{wei2024jailbroken, liu2023jailbreaking},"
- Leakage Rate (LR): The percentage of conversations where a system fully discloses a secret to an unauthorized party. "This intervention reduced the average Leakage Rate from 15.80\% to 5.12\%,"
- LLM-as-a-judge: Using a LLM as an automated evaluator to score interactions against defined rubrics. "we employ an instruction-tuned LLM as an automated judge for scalable and consistent scoring."
- LLM prober: An LLM tasked with conducting multi-turn dialogues to test whether a system leaks secrets under probing. "The LLM prober executes its goal using one of two primary probing strategies."
- MemGPT: An agentic memory module architecture enabling persistent, structured memory for long-term interactions. "advanced agentic memory modules (e.g., MemGPT)"
- Over-Secrecy Rate (OSR): The percentage of conversations where a system wrongly withholds a secret from authorized recipients, indicating reduced utility. "Over-Secrecy Rate (OSR)"
- Persona Consistency Score (PC): A metric assessing how consistently a system matches a user's style and personality across interactions. "Persona Consistency Score similar to work done in ExPerT \cite{salemi2025expert} to evaluate personalized long form text generation."
- Persona Hub: A dataset containing rich persona profiles used to seed user characteristics in simulations. "We first construct a social graph seeded with user personas from the Persona Hub dataset \cite{ge2024scaling}."
- PersonaBench: A benchmark aimed at generating and evaluating rich user profiles and associated documents for personalization. "PersonaBench \cite{tan-etal-2025-personabench} focuses on the generation of rich user profiles and their associated documents,"
- PII masking: A defense technique that removes personally identifiable information from text to reduce privacy risks. "traditional inference defenses like PII masking fail here,"
- Privacy-aware system prompt: A system-level instruction that explicitly directs the model to safeguard secrets during generation. "A privacy-aware system prompt served as an effective primary defense."
- Privacy-by-design safeguards: Architectural protections integrated into systems from the outset to enforce privacy-preserving behavior. "privacy-by-design safeguards to ensure an ethical and inclusive web for everyone."
- Privacy-Reproducibility Paradox: The ethical dilemma where using real data for reproducible evaluation would itself violate privacy. "Utilizing real-world data creates a Privacy-Reproducibility Paradox:"
- Red-teaming: Adversarial evaluation processes designed to uncover vulnerabilities and unsafe behaviors in AI systems. "traditional \"red-teaming\" attacks"
- Retrieval-Augmented Generation (RAG): An architecture that retrieves relevant context from a knowledge base to augment an LLM’s generation without retraining. "Retrieval-Augmented Generation (RAG) serves as the structural backbone,"
- Social graph: A network representation of users and their evolving relationships used to ground interactions in social context. "We first construct a social graph seeded with user personas from the Persona Hub dataset \cite{ge2024scaling}."
- Vector database: A database optimized for storing and querying high-dimensional vectors used in similarity search. "ChromaDB \cite{chromadb} as the vector database"
- Vector database access controls: Mechanisms that regulate which vectors or documents can be retrieved based on access policies. "native vector database access controls"
Collections
Sign up for free to add this paper to one or more collections.

