Anytime Training with Schedule-Free Spectral Optimization
Published 21 May 2026 in cs.LG, cs.AI, math.OC, and stat.ML | (2605.23061v1)
Abstract: Standard neural network training relies on learning-rate schedules tied to a fixed horizon, leading to strong path dependence and costly re-tuning as data availability changes. Schedule-Free (SF) methods address this by removing explicit schedules, yet SF-AdamW, the current state-of-the-art anytime optimizer, consistently underperforms well-tuned AdamW baselines. We propose SF-NorMuon, a schedule-free spectral optimizer that closes this gap: with a single hyperparameter configuration, SF-NorMuon matches or exceeds tuned AdamW on 125M and 772M parameter LLMs across $1$--$8\times$ Chinchilla horizons. On the theoretical side, we prove a stationarity guarantee for schedule-free spectral dynamics and identify weight decay at the fast iterate as essential for long-horizon stability. SF-NorMuon enables practitioners to obtain high-quality checkpoints at any point during training without committing to a horizon in advance. By closing the performance gap with tuned baselines, SF-NorMuon makes horizon-free optimization more practical, taking a step towards truly open-ended, continual learning.
The paper introduces SF-NorMuon, a schedule-free optimizer that matches or outperforms horizon-tuned AdamW across various budget regimes.
The method leverages spectral geometry with fixed step sizes, polar decomposition, and weight decay at the fast iterate to ensure stability during continual training.
Empirical results on language models validate SF-NorMuon's anytime performance, offering valuable insights for open-ended and continual learning scenarios.
Schedule-Free Spectral Optimization for Anytime Neural Network Training
Introduction and Motivation
Training neural networks with standard optimizers such as AdamW necessitates a learning-rate schedule determined by a predefined compute horizon. This approach introduces significant path dependence and inflexibility when adapting to dynamic data availability, impeding open-ended and continual learning scenarios. This paper addresses this key limitation by advancing the field of schedule-free (SF) optimization—an approach that eliminates the need for pre-specified training horizons or explicit learning-rate schedules.
The authors present SF-NorMuon, a schedule-free optimizer that leverages spectral geometry to match or surpass well-tuned, horizon-specific AdamW baselines across a wide range of budget ratios. SF-NorMuon aims to deliver consistent, high-quality model checkpoints throughout training regardless of the eventual stopping point. Significant theoretical and practical advances underlie this optimizer, making it effective where previous anytime methods, such as SF-AdamW, consistently lagged behind tuned baselines.
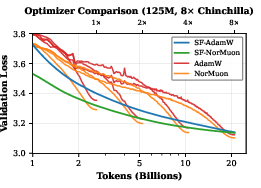
Figure 2: Optimizer comparison on the 125M model. Scheduled methods (NorMuon, AdamW) use horizon-dependent learning-rate schedules, while schedule-free methods (SF-NorMuon, SF-AdamW) employ consistent hyperparameters and are evaluated at arbitrary checkpoints. SF-NorMuon closely tracks scheduled NorMuon, demonstrating effective transfer of spectral-norm optimization benefits to the schedule-free paradigm.
Problem Formulation and Theoretical Results
The SF optimization paradigm maintains fast iterates updated at a fixed (constant) step size, while online averaging over these iterates induces an effective learning-rate decay. SF-NorMuon generalizes this dynamic to spectral-norm geometry, wherein update directions are determined via polar decomposition of the smoothed gradient (momentum buffer), rather than coordinate-wise adaptation.
The paper establishes a stationarity guarantee for schedule-free spectral dynamics, demonstrating that SF-NorMuon achieves a sublinear convergence rate O(T−1/4) in the stochastic (noisy) non-convex setting and O(T−1/2) in the noiseless regime. Notably, these rates match the best known for spectral optimizers such as Muon, even though SF-NorMuon forgoes access to horizon-specific schedules.
A critical insight is the identification of weight decay at the fast iterate (zt) as essential for stability, particularly over long-horizon (continual) training. Applying decay at alternative locations yields divergence, a result in sharp contrast to expectations from convex SF optimization theory. Theoretical analysis, supported by empirical steady-state norm characterizations, links this requirement to the constant-step dynamics of the fast sequence.
Algorithmic Design and Practical Refinements
SF-NorMuon integrates several key mechanisms:
Spectral Norm Geometry: The fast update is computed as the polar factor of the explicit momentum. This ensures updates progress uniformly across all singular directions of the weight matrix, rather than being dominated by the largest entries as in AdamW.
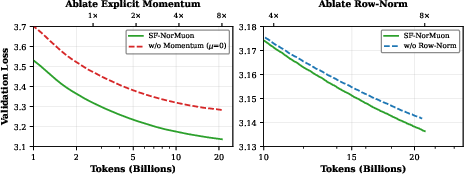
Explicit Momentum Buffer: Crucial for stabilizing aggressive polar updates; ablation reveals significant degradation without it.
Row-wise Adaptive Normalization: Handles high variance in update magnitudes across neurons, aligning with prior findings on NorMuon’s effectiveness and ensuring robust per-neuron adaptation.
Weight Decay at Fast Iterate (zt): Enforced to guarantee boundedness and prevent late-stage divergence, especially in long-horizon regimes.
These design choices are validated through thorough ablation studies.
Figure 4: Left — The removal of explicit momentum (setting μ=0) in SF-NorMuon significantly harms convergence, underscoring its importance for smoothing gradients in the spectral geometry. Right — Ablating row-wise normalization produces a moderate slowdown.
Weight Decay and Long-Horizon Stability
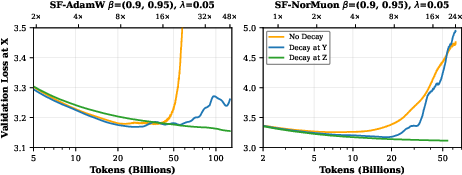
The investigation into weight decay location uncovers a failure mode unique to schedule-free (SF) methods. If decay is applied at the gradient evaluation point (yt), both SF-AdamW and SF-NorMuon diverge in the long run, contradicting classic convex analysis. Only decay at the fast iterate (zt) ensures stability and bounded parameter norms, confirmed both theoretically and empirically.
Figure 3: Weight decay strategies for schedule-free optimizers. Left — SF-AdamW is unstable without weight decay; decay at yt performs best initially but diverges with a long enough horizon. Decay at zt stabilizes the process, with analogous results for SF-NorMuon (right).
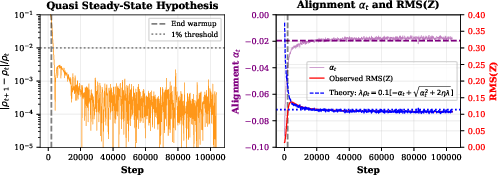
Empirical steady-state analysis demonstrates that the RMS norm of the fast iterate tracks a closed-form prediction, dependent on alignment with the update direction and the decay coefficient, confirming theoretical derivations.
Figure 5: Quasi steady-state analysis for SF-NorMuon with decay at zt, validating the steady-state prediction and showing controlled parameter norms across layers and training duration.
Experimental Results: LLM Training
Comprehensive experiments on decoder-only transformer models (125M and 772M parameters, LLaMA-2 style) are conducted on the FineWeb-100B dataset. Evaluation spans multiple Chinchilla-optimal horizons, with per-horizon tuned AdamW serving as a strong baseline. SF-NorMuon is run with the same fixed hyperparameter set across all regimes, as is SF-AdamW for direct comparison.
Key findings:
Performance: SF-NorMuon matches or marginally surpasses horizon-tuned AdamW in most regimes. The validation loss gap observed for SF-AdamW is eliminated.
Anytime Capability: SF-NorMuon produces high-quality models that can be checkpointed and deployed at arbitrary stages during training, robust to unforeseen changes in dataset size and compute availability.
Learning Rate Robustness: Validation loss sweeps reveal that SF-NorMuon is consistently less sensitive to suboptimal learning rates than SF-AdamW.
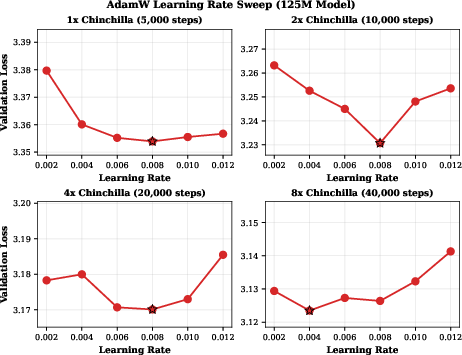
Figure 6: AdamW learning rate sweep with cosine scheduling across four training horizons. Longer training budgets favor smaller learning rates, highlighting the tuning burden for horizon-dependent optimizers.
Figure 1: SF-NorMuon matches scheduled NorMuon and per-horizon tuned AdamW throughout training, yielding genuine anytime performance.
Practical and Theoretical Implications
Practically, SF-NorMuon advances schedule-free optimization to a level fully competitive with extensively tuned, horizon-specific methods. This outcome has immediate relevance for long-horizon, open-ended training paradigms such as continual learning, reinforcement learning, and foundation model adaptation, where the final data availability is unknown at training onset.
Theoretically, the demonstration that weight decay at the fast iterate is necessary for stability in the spectral geometry underlines the importance of optimizer-state dynamics construction in non-convex high-dimensional problems. The bridging of schedule-free and spectral-norm geometries with rigorous convergence guarantees is a substantive contribution to first-order algorithmic theory for deep learning.
Future Directions
Potential research avenues include extending SF-NorMuon validation to diverse architectures (e.g., Mixture-of-Experts, multimodal transformers), scaling to trillions of parameters, and integrating into lifelong continual learning pipelines where the ability for robust checkpointing and anytime evaluation is essential.
Conclusion
SF-NorMuon is the first schedule-free optimizer to close the performance gap with horizon-dependent AdamW in neural network training settings of practical significance. Its theoretical convergence rate, empirical robustness, and improved practical features (state size, learning rate tolerance, anytime adaptivity) position it as a preferred choice for practitioners engaged in scalable, open-ended deployment of deep networks.
Reference: "Anytime Training with Schedule-Free Spectral Optimization" (2605.23061)
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.