AMUSE: Anytime Muon with Stable Gradient Evaluation
Abstract: Modern deep learning commonly relies on AdamW with prescribed learning rate schedules, but recent works challenge both components: Schedule-Free optimization removes explicit schedules via iterate averaging, and Muon improves the update geometry by orthogonalizing momentum for matrix parameters. Despite Muon's strong empirical performance, its underlying mechanism remains partially understood. We study Muon through the river-valley loss landscape, where useful training progress occurs along a flat, low-curvature bulk subspace (the river), while high-curvature dominant directions form steep valley walls that induce oscillations. We empirically show that while Muon's orthogonalization accelerates river progress by increasing the bulk component, it also amplifies dominant-direction noise, causing oscillatory trajectories. Building on this, we propose Anytime MUon with Stable gradient Evaluation (AMUSE), which integrates Muon's rapid bulk progress with the stabilizing effect of Schedule-Free averaging. AMUSE uses a time-varying interpolation coefficient that initially evaluates gradients near the fast Muon sequence for rapid adaptation, then gradually shifts toward the stable averaged sequence to suppress valley-wall oscillations. As a result, AMUSE requires no learning rate schedules and supports anytime training. Across vision tasks and LLM pretraining, AMUSE consistently improves the performance-iteration Pareto frontier over (Schedule-Free) AdamW and Muon.
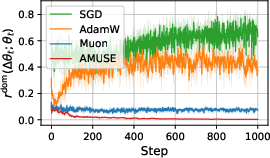
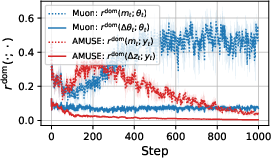
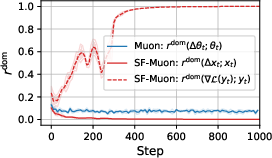
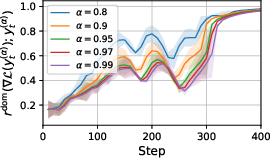

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Brief overview
This paper introduces a new way to train deep neural networks called AMUSE. It combines two ideas:
- Muon, an optimizer that makes fast progress but can be bouncy/unstable.
- Schedule-Free training, a way to keep training smooth without using a hand‑designed learning rate schedule.
The goal is to move quickly in the directions that really improve the model, while avoiding wasteful bouncing in directions that don’t help much. AMUSE does this automatically and lets you stop training at any time and still get good results.
Key questions the paper asks
- Why does Muon often train models faster than the popular AdamW optimizer?
- Why can Muon be unstable (it “wobbles”) during training?
- Can we keep Muon’s speed but make it stable—without using complex learning rate schedules?
- Will this work across different tasks, like image recognition and LLMs?
What did they do and how?
The “river–valley” picture (a simple analogy)
Imagine the training process like walking through a long valley:
- The flat riverbed is where most useful progress happens (you can move forward easily).
- The steep valley walls are directions that change the loss a lot with tiny steps (they make you bounce side to side).
Good training means:
- Take big, steady steps along the river (forward progress).
- Avoid zig‑zagging into the steep walls (wasted motion and instability).
What is Muon, in plain words?
Muon updates model layers that are matrices in a “balanced” way. Think of it like turning a music mixer so no single instrument is too loud; everything stays more even. That balance helps it move faster along the flat riverbed. But there’s a catch: by making every part more balanced, Muon can also accidentally boost tiny bits of noise, which makes the path wobble against the valley walls.
What is Schedule-Free training, in plain words?
Most training uses a learning rate schedule (like: warm up, then slowly cool down). Schedule-Free skips that. Instead, it:
- Keeps two versions of the model: a fast‑changing one and a smooth, averaged one.
- Chooses a point between these two to measure the gradient (the direction to step). This “averaging” acts like a natural stabilizer—it reduces wall-bouncing without needing a hand‑designed schedule.
The AMUSE idea
AMUSE combines Muon’s fast, balanced steps with Schedule-Free’s stability:
- Early on, AMUSE looks more at the fast Muon model to adapt quickly.
- Over time, AMUSE smoothly shifts to evaluate gradients closer to the averaged (stable) model. This reduces wobbling while keeping speed. Importantly, it doesn’t need a learning rate schedule and works well if you stop training at any time.
How they tested it
- They analyzed the directions of updates to see how much movement was along the “river” vs. into the “walls.”
- They ran experiments on:
- Image tasks (like CIFAR, ImageNet, segmentation with U‑Net, and ViT fine‑tuning).
- LLM pretraining (Llama‑style models with hundreds of millions to a billion parameters).
- They compared AMUSE against AdamW, Schedule‑Free AdamW, and Muon.
Main findings and why they matter
- Muon’s “balance” increases progress along the river (good), but also strengthens small noisy parts that cause oscillations against the walls (bad).
- Schedule-Free gradient evaluation calms down those oscillations by measuring gradients closer to the stable average.
- AMUSE blends the two: it starts fast, then becomes steadily more stable by shifting where it evaluates the gradient. This gives both speed and stability without learning rate schedules.
Here are a few concrete results (why they’re important is noted in parentheses):
- AMUSE reaches Muon’s final performance with fewer steps:
- About 1.5× fewer steps on a 720M‑parameter LLM (saves time and compute).
- About 1.1× fewer steps on ImageNet with ResNet‑50 (faster image training).
- About 3.1× fewer steps on ImageNet ViT fine‑tuning (big speedup for modern vision models).
- AMUSE improves the performance‑vs‑training‑steps trade‑off across many tasks (more efficient training).
- AMUSE naturally supports “anytime” training (you can stop early and still be in a good place), because it doesn’t rely on a carefully timed learning rate schedule.
What does this mean for the future?
- Simpler training: You don’t need to hand‑tune learning rate schedules. AMUSE learns fast early on and stabilizes later—by design.
- Better use of compute: Faster progress along the directions that matter means fewer training steps for similar (or better) results.
- Scales to big models: It works well for LLMs and common vision tasks.
- Next steps: AMUSE keeps an extra “average” copy of the model, which uses some memory. A future goal is to get the same speed‑and‑stability benefits with even less memory.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete avenues for future work suggested by the paper.
- Lack of formal convergence and stability guarantees for AMUSE
- No theoretical proof that time-varying interpolation yields convergence or suppresses oscillations under stochastic noise; establish conditions (e.g., Lipschitz smoothness, curvature anisotropy, noise models) under which AMUSE provably converges and remains stable.
- Quantify how orthogonalization and SF averaging jointly affect convergence rates and bias/variance trade-offs relative to AdamW and Muon.
- Missing principled design of the interpolation schedule
- The schedule is heuristic; derive optimal or near-optimal schedules from theory (e.g., minimizing a bound on dominant-direction energy or regret).
- Provide data-/model-adaptive rules for selecting online using observable statistics (e.g., gradient variance, curvature proxies, cosine similarities).
- Limited subspace diagnostics at scale
- Dominant/bulk analyses rely on small models or proxies; develop scalable, online estimators (e.g., GGN/Lanczos sketches, randomized Hutchinson methods) to monitor dominant/bulk energy during large-scale LLM training.
- Validate whether the “river-valley” geometry persists across larger models and datasets beyond small MLPs and MNIST-like settings.
- Unclear choice of dominant subspace dimension k outside classification
- For classification experiments is set to the number of classes; for LLMs and other tasks, a principled method to set or infer is not provided. Develop data-driven and adaptive methods to determine over training.
- Orthogonalization–noise interaction not fully quantified
- Precisely characterize how Muon’s orthogonalization amplifies noise in high-curvature directions under stochastic gradients, and how AMUSE modulates this amplification pre-/post-orthogonalization.
- Develop metrics that directly measure “valley-wall oscillation amplitude” over training and validate reductions due to AMUSE.
- Layer/block heterogeneity and parameter-type treatment
- AMUSE inherits Muon’s restriction to matrix-valued parameters and relies on SF-AdamW/SGD for others; examine whether non-matrix blocks (embeddings, LayerNorm, heads) contribute dominant components that limit stability.
- Explore blockwise/layerwise schedules (or selective application) based on curvature or spectral diagnostics rather than a single global .
- Computational and numerical overheads insufficiently characterized
- Provide a comprehensive cost analysis: Newton–Schulz iteration counts, FLOPs, wall-clock throughput, and mixed-precision stability (FP16/BF16) across hardware (A100/H100) versus AdamW/Muon.
- Study numerical stability of orthogonalization for ill-conditioned or near-rank-deficient matrices and the effect of per-layer shapes and weight tying.
- Memory footprint and scaling limits
- Although AMUSE requires only one extra model copy relative to Muon, quantify peak memory under activation checkpointing, large batch sizes, and multi-GPU sharding; propose memory-saving variants (e.g., low-rank or quantized states).
- Interaction with standard training components
- Gradient clipping: examine compatibility and optimal clipping thresholds under orthogonalization; quantify impact on stability and final performance.
- Weight decay: analyze theoretically and empirically how decoupled weight decay interacts with orthogonalized momentum and SF averaging; study implicit regularization.
- Data augmentation and regularizers (Mixup, CutMix, RandAugment, SAM): evaluate whether AMUSE’s benefits persist or change with strong regularization.
- Warmup dependence and “anytime” claims
- Despite no LR decay, AMUSE still uses warmup; ablate or eliminate warmup to test truly schedule-free behavior and define guidelines for selection.
- Validate “anytime” training under realistic scenarios (pause/resume, mid-run extension, changing token budgets) on larger LLMs beyond 124M.
- Hyperparameter robustness and scaling laws
- Provide broader sweeps for across model sizes, batch sizes, sequence lengths, and datasets; quantify robustness bands and scaling laws for optimal settings.
- Study sensitivity to the Muon momentum coefficient (held fixed here) and its interaction with .
- Broader task coverage and transferability
- Extend evaluations beyond classification/segmentation and LM next-token prediction: detection/instance segmentation, diffusion/vision-LLMs, seq2seq tasks, reinforcement learning.
- Assess transfer and fine-tuning scenarios (instruction tuning, domain shift, continual learning) and whether AMUSE aids stability under distribution shift.
- Generalization, robustness, and fairness outcomes
- Move beyond accuracy/perplexity: evaluate calibration, OOD robustness, adversarial robustness, and group fairness; test claims about balanced component learning in imbalanced regimes within AMUSE.
- Comparative baseline breadth and consistency
- Add strong and diverse baselines (e.g., Adafactor, Shampoo/Adafactor hybrids, Sophia, Lion, K-FAC, Shampoo-MAE recipes) under matched budgets; report tokens/sec and hardware configs for apples-to-apples comparisons.
- Compare to WSD-tuned Muon (state-of-practice in open LLM recipes) under equivalent wall-clock and compute.
- Direct river-following verification at scale
- EWA/decay responsiveness and cosine similarity are indirect proxies; develop direct, scalable diagnostics that confirm the averaged trajectory hugs the river for large LLMs (e.g., tracking dominant/bulk alignment over time).
- Per-layer spectral effects and anisotropy mapping
- Quantify how AMUSE alters per-layer singular spectra and curvature distributions (e.g., attention vs MLP blocks), and correlate these with training speed and generalization.
- Failure modes and extreme regimes
- Characterize regimes where AMUSE underperforms or diverges: ultra-small batches, extremely high curvature (very deep or narrow models), sparse gradients, or noisy data.
- Study catastrophic loss spikes and recovery behavior compared to AdamW and Muon.
- Integration with parallelism and distributed training
- Analyze communication overheads and numerical inconsistencies under data/model/pipeline parallelism when interpolating or orthogonalizing states; propose synchronization-efficient variants.
- Automated or feedback-controlled variants
- Explore control-theoretic or bandit-style mechanisms to adjust based on online performance/curvature signals; compare to fixed schedules for both stability and speed.
- Theoretical links to central flows and edge-of-stability
- Bridge the river-valley perspective with recent central-flow and edge-of-stability theories; formalize when AMUSE shifts dynamics away from the edge without sacrificing river progress.
- Application to non-matrix parameters via structured updates
- Investigate extensions that impose structure (e.g., low-rank or block-orthogonal updates) for vector parameters to unify treatment and potentially reduce dominant-direction noise.
- Tokenization, corpus, and multilingual effects in LLMs
- Validate AMUSE across tokenizers (BPE, unigram) and corpora (C4, Pile, multilingual datasets); quantify how data composition affects curvature anisotropy and AMUSE’s gains.
- Reproducibility and variance reporting
- Provide multiple seeds and error bars for LLM experiments; release complete hyperparameter grids and training traces to enable rigorous replication and meta-analysis.
Practical Applications
Immediate Applications
Below are concrete, near-term uses you can deploy now based on the paper’s findings and AMUSE implementation.
- LLM pretraining without learning-rate schedules
- Sectors: Software/AI, Cloud, Foundation-model labs
- What to do: Replace AdamW+cosine decay or vanilla Muon with AMUSE for decoder-only Transformers (Llama-like) at 100M–1B scales. Keep linear warmup, drop decay. Expect better performance-per-iteration and strong large-batch scaling.
- Tools/workflows: Integrate the AMUSE optimizer into PyTorch/DeepSpeed/Megatron-LM/Hugging Face Transformers training loops; keep non-matrix parameters on SF-AdamW as in the paper; log update norms and cosine similarity of successive updates for stability monitoring.
- Assumptions/dependencies: Wall-clock gains depend on efficient Newton–Schulz kernels for orthogonalization; per-step overhead may rise vs AdamW, but fewer steps to target perplexity can offset this. Some tuning of learning rate, weight decay, β1, and ρ is still required. Linear warmup T0 remains.
- Vision training with simpler, schedule-free recipes
- Sectors: Computer Vision (CV), Edge/cloud ML services
- What to do: Use AMUSE for ResNet-50 ImageNet training, U-Net segmentation (ISIC 2018), and ViT-B/16 MAE fine-tuning. Expect faster anytime gains and fewer steps than AdamW/Muon to reach target accuracy.
- Tools/workflows: Plug into timm/MMCV/lightning recipes; keep SF-SGD or SF-AdamW for non-matrix params; drop cosine decay. For MAE fine-tuning, AMUSE works even when the pretraining used AdamW.
- Assumptions/dependencies: Slight extra state vs Muon (similar to AdamW); matrix orthogonalization adds compute cost; verify mixed-precision and gradient checkpointing compatibility in your stack.
- Budget- and interruption-friendly “anytime training”
- Sectors: MLOps/Cloud (spot/preemptible instances), Platform engineering
- What to do: Adopt AMUSE to enable safe early stopping and interruption-resilient training (no schedule coupling to total horizon). Improve GPU cluster utilization by pausing/resuming jobs without re-tuning schedules.
- Tools/workflows: Add early-exit policies keyed on validation loss, update norms, and update-to-update cosine similarity; remove LR-decay logic from orchestration.
- Assumptions/dependencies: Persist AMUSE state correctly (parameters, SF state, Muon momentum). Gains are larger when training horizons are uncertain or fragmented.
- Reduced hyperparameter and schedule search in AutoML
- Sectors: AutoML, ML platform tooling, Consulting
- What to do: Replace LR-schedule sweeps with AMUSE; narrow tuning to LR, WD, β1, ρ. Use AMUSE as the default optimizer in self-tuning systems.
- Tools/workflows: Integrate in Ray Tune/Optuna pipelines; search β1 in {0.4, 0.6}, ρ in {0.6, 0.8} as paper suggests, alongside LR/WD.
- Assumptions/dependencies: Still requires warmup T0 tuning for some tasks; ensure orthogonalization step is not a per-trial bottleneck.
- Medical imaging model development with faster iteration
- Sectors: Healthcare (research/clinical AI), Biotech
- What to do: Use AMUSE to train and iterate U-Net-like segmentation models (e.g., dermoscopy, radiology) faster and with fewer schedule knobs.
- Tools/workflows: Integrate into MONAI pipelines; keep inference on averaged weights as prescribed by SF formulation.
- Assumptions/dependencies: Clinical deployment still requires rigorous validation; verify that reduced oscillations translate to consistent calibration and segmentation quality.
- Training diagnostics using river–valley metrics
- Sectors: Academia, ML research, Tooling
- What to do: Adopt the dominant/bulk subspace lens to debug instability. Track update norms, cosine similarity, and (when feasible) bulk/dominant proxies via Hessian approximations.
- Tools/workflows: pyHessian or low-rank Hessian probes; alerts when dominant components or oscillations spike; compare Muon vs AMUSE behavior.
- Assumptions/dependencies: Curvature estimation is approximate and incurs overhead; use sparsely or on small validation batches.
- Recipe upgrades where Muon is already used
- Sectors: Open-model training (e.g., Kimi-K2, GLM-5, DeepSeek-like recipes)
- What to do: Swap Muon+decay schedules for AMUSE (no decay), preserving Muon for matrix params and SF-AdamW/SF-SGD for others.
- Tools/workflows: Configuration-level replacement in existing codebases; shared momentum buffers retained.
- Assumptions/dependencies: Ensure per-step latency increase is acceptable; re-tune LR/β1/ρ minimally.
Long-Term Applications
These opportunities require additional research, scaling, or ecosystem development before broad deployment.
- Optimizer autopilots with river tracking
- Sectors: Software/AI, AutoML, MLOps
- Concept: Dynamically adapt βt using online estimates of curvature or dominant/bulk ratios; automatically keep the iterate near the “river” and adjust when oscillations appear.
- Potential tools/products: “River-aware optimizer” service; training-time controllers that modulate βt/LR based on Hessian traces, update cosine, or loss curvature probes.
- Assumptions/dependencies: Reliable, low-overhead curvature proxies; robust controllers that don’t destabilize training.
- Hardware and kernel support for orthogonalized updates
- Sectors: Semiconductors, Systems/compilers, Cloud providers
- Concept: Add fast Newton–Schulz or orthogonalization primitives in GPUs/TPUs or libraries (cuBLAS, CUTLASS, Triton kernels) to reduce AMUSE’s per-step cost.
- Potential tools/products: Vendor-optimized AMUSE kernels; fused matrix-momentum ortho ops.
- Assumptions/dependencies: Vendor investment; standardized APIs; evidence of significant wall-clock gains at scale.
- Federated/on-device and intermittent training
- Sectors: Mobile/Edge, IoT, Privacy-preserving ML
- Concept: Use anytime, schedule-free AMUSE for devices with intermittent connectivity and variable training budgets; stabilize local updates before aggregation.
- Potential tools/products: Federated SDKs offering AMUSE as the default, with low-precision ortho kernels.
- Assumptions/dependencies: Efficient, memory-light orthogonalization; quantization-friendly variants; empirical validation on non-IID federated data.
- Energy- and carbon-aware training policies
- Sectors: Policy, Sustainability, Corporate governance
- Concept: Encourage schedule-free, anytime training methods (like AMUSE) to cut wasted compute from mis-tuned schedules and allow earlier convergence in step count.
- Potential tools/products: Procurement or grant guidelines promoting anytime optimization; reporting standards on “steps-to-target” and energy per token/epoch.
- Assumptions/dependencies: Wall-clock energy measurements at scale; transparent benchmarks showing net energy savings vs strong AdamW baselines.
- Continual and robust learning with fewer oscillations
- Sectors: Enterprise ML, Cybersecurity, Healthcare
- Concept: Pair AMUSE with replay/regularization (e.g., EWC) to reduce catastrophic oscillations during domain shifts or task transitions.
- Potential tools/products: Continual-learning frameworks that default to AMUSE; “stability scores” guiding when to consolidate or adapt.
- Assumptions/dependencies: Empirical studies in non-stationary settings; interaction with task rehearsal and evaluation metrics.
- Low-precision training enablement (FP8/INT8)
- Sectors: Systems/compilers, Cloud
- Concept: Exploit AMUSE’s stabilized updates to tolerate lower precision arithmetic without divergence, reducing memory/energy.
- Potential tools/products: FP8/INT8 AMUSE kernels; recipes combining AMUSE with quantization-aware training.
- Assumptions/dependencies: Careful error analysis of orthogonalization under quantization; validation on large models.
- River-aware debugging and safety monitors
- Sectors: Platform engineering, Safety
- Concept: Online monitors that detect “valley-wall” oscillations and automatically intervene (adjust βt/LR, pause, checkpoint).
- Potential tools/products: Training dashboards exposing dominant/bulk proxies; auto-remediation hooks.
- Assumptions/dependencies: Fast, reliable proxies; policies that avoid overreacting to noise.
- RL/robotics training stabilization
- Sectors: Robotics, Autonomous systems
- Concept: Test AMUSE in actor–critic or imitation learning where oscillations are common; leverage bulk-oriented updates for more sample-efficient learning.
- Potential tools/products: RL libraries offering AMUSE backends for policy/value networks.
- Assumptions/dependencies: Evidence on non-stationary objectives; integration with target network updates and entropy schedules.
- Cloud cost-optimization and “anytime checkpoints”
- Sectors: Cloud, FinOps, MLOps
- Concept: Products that price and schedule training around AMUSE’s anytime property—budget-aware early exits, elastic scaling, and preemptible-friendly retries.
- Potential tools/products: “Anytime Trainer” services in managed ML platforms; budget-to-quality SLAs.
- Assumptions/dependencies: Estimators linking budget to expected quality; robust checkpointing and resume semantics.
Notes on feasibility and general assumptions
- The paper’s improvements are shown in steps-to-quality; wall-clock gains depend on high-quality, fused implementations of orthogonalization and momentum operations.
- Memory usage is slightly higher than vanilla Muon (extra SF state) but comparable to AdamW; verify fit at large batch sizes.
- AMUSE removes LR decay but still uses warmup and adds β1, ρ; modest tuning remains necessary.
- Benefits span CV and LLMs; additional validation is advisable for domains like diffusion, RL, and federated learning.
- Open-source implementation is available at the provided GitHub link, easing immediate adoption.
Glossary
- AdamW: An adaptive gradient optimizer that combines Adam with decoupled weight decay to improve generalization in deep learning. "Modern deep learning commonly relies on AdamW with prescribed learning rate schedules"
- AMUSE: An optimizer that combines Muon with Schedule-Free gradient evaluation using a time-varying interpolation to stabilize training and enable anytime use. "we propose Anytime MUon with Stable gradient Evaluation (AMUSE)"
- anisotropic: Having direction-dependent properties; here, referring to loss landscapes where curvature varies greatly across directions. "loss landscapes are highly anisotropic."
- anytime training: A training regime where the model can be stopped at any time and still provide a strong checkpoint without dependence on a fixed schedule. "AMUSE naturally supports anytime training."
- bulk subspace: The high-dimensional, low-curvature subspace of the parameter space where most useful training progress occurs. "the bulk subspace forms a relatively flat river"
- condition-number-free linear convergence: Convergence at a rate that does not depend on the condition number of the problem, indicating robustness to ill-conditioning. "yielding condition-number-free linear convergence in matrix factorization and linear transformer settings."
- cosine decay: A learning rate schedule that reduces the learning rate following a cosine function over time. "such as cosine decay"
- decoupled weight decay: A regularization technique that applies weight decay separately from the gradient-based parameter update. "with decoupled weight decay"
- dominant subspace: The low-dimensional, high-curvature subspace spanned by the top Hessian eigenvectors, associated with steep directions. "the dominant subspace forms steep valley walls"
- Exponential Weight Averaging (EWA): A post-hoc averaging technique that exponentially decays past parameter contributions to smooth the trajectory. "Exponential Weight Averaging (EWA)"
- Hessian spectrum: The set of eigenvalues of the Hessian matrix that reveals curvature properties of the loss landscape. "the Hessian spectrum often contains a small number of large outlier eigenvalues"
- interpolation coefficient: A scalar controlling how much the gradient evaluation point is interpolated between the fast and averaged iterates. "AMUSE uses a time-varying interpolation coefficient"
- iterate averaging: Averaging successive parameter iterates during training to stabilize and improve convergence. "Schedule-Free optimization removes explicit schedules via iterate averaging"
- Muon: An optimizer that normalizes and orthogonalizes matrix-valued momentum to balance updates across singular directions. "Muon exploits matrix structure by applying momentum to matrix-valued parameters and orthogonalizing the resulting update direction."
- Newton-Schulz iteration: An iterative method to approximate matrix functions (e.g., inverse square roots), used here to implement fast orthogonalization. "approximated using a Newton-Schulz iteration"
- orthogonalization operator: An operator that transforms a matrix update to have orthonormal structure, reducing dominance of certain directions. "an orthogonalization operator, which is approximated using a Newton-Schulz iteration"
- orthogonalized momentum: Momentum that has been transformed to have orthonormal components, promoting balanced updates. "orthogonalized momentum accelerates progress along the river directions."
- performance–iteration Pareto frontier: The optimal trade-off curve between achieved performance and number of training iterations. "improves the performance-iteration Pareto frontier"
- Polyak--Ruppert (PR) averaging: An averaging method that takes the mean of iterates to reduce variance and improve convergence rates. "as an interpolation between Polyak--Ruppert (PR) averaging and primal averaging"
- preconditioner: A transformation applied to the gradient or parameters to improve conditioning and accelerate convergence. "act as an effective preconditioner"
- primal averaging: Averaging that updates parameters toward the average of past primal iterates rather than gradients. "as an interpolation between Polyak--Ruppert (PR) averaging and primal averaging"
- river-valley loss landscape: A geometric view of optimization where low-curvature “river” directions enable progress and high-curvature “valley walls” cause oscillations. "river-valley loss landscape"
- RoPE: Rotary positional embeddings; a method for encoding token positions in Transformers. "using tied input/output embeddings, SwiGLU, RMSNorm, and RoPE."
- RMSNorm: A normalization technique using root mean square statistics instead of mean/variance normalization. "using tied input/output embeddings, SwiGLU, RMSNorm, and RoPE."
- RMSProp: An adaptive optimizer that scales learning rates by a moving average of recent squared gradients. "using an RMSProp update with decoupled weight decay gives SF-AdamW."
- Schedule-Free (SF) optimizer: An optimizer that avoids explicit learning rate schedules by evaluating gradients at interpolated points between fast and averaged iterates. "\citet{defazio2024the} introduce the schedule-free (SF) optimizer"
- singular components: Contributions along singular vectors (from SVD) that can dominate matrix updates. "a few large singular components"
- SwiGLU: A gated activation function variant used in modern Transformers for improved expressivity and stability. "using tied input/output embeddings, SwiGLU, RMSNorm, and RoPE."
- tied input/output embeddings: Sharing the same embedding matrix for both input tokens and output softmax to reduce parameters and improve learning. "using tied input/output embeddings, SwiGLU, RMSNorm, and RoPE."
- Warmup-Stable-Decay (WSD): A learning rate schedule with distinct warmup, stable, and decay phases tailored for large model training. "Warmup-Stable-Decay (WSD) schedules"
Collections
Sign up for free to add this paper to one or more collections.